 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Score
Apr 19, 2025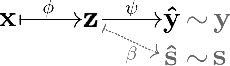
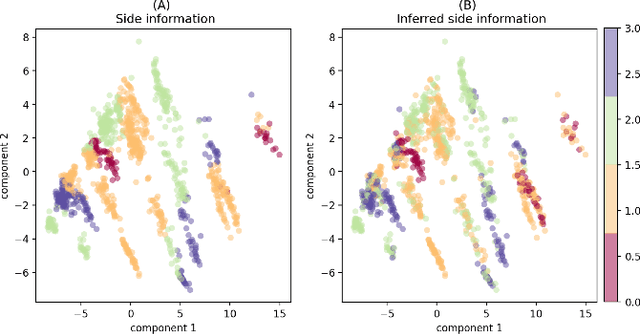
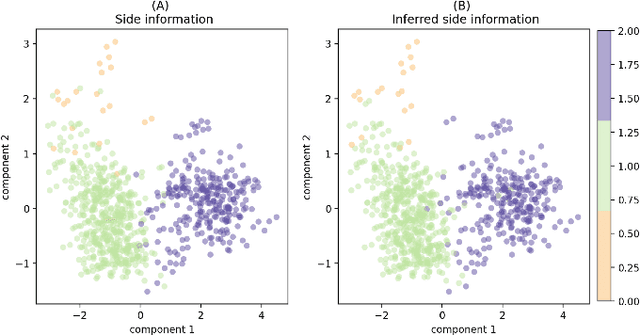
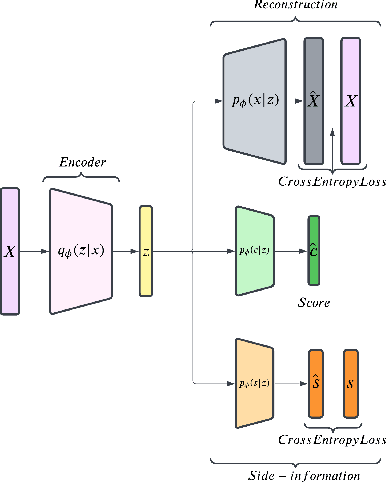
Common machine learning settings range from supervised tasks, where accurately labeled data is accessible, through semi-supervised and weakly-supervised tasks, where target labels are scant or noisy, to unsupervised tasks where labels are unobtainable. In this paper we study a scenario where the target labels are not available but additional related information is at hand. This information, referred to as Side Information, is either correlated with the unknown labels or imposes constraints on the feature space. We formulate the problem as an ensemble of three semantic components: representation learning, side information and metric learning. The proposed scoring model is advantageous for multiple use-cases. For example, in the healthcare domain it can be used to create a severity score for diseases where the symptoms are known but the criteria for the disease progression are not well defined. We demonstrate the utility of the suggested scoring system on well-known benchmark data-sets and bio-medical patient records.
Pairwise Margin Maximization for Deep Neural Networks
Oct 09, 2021
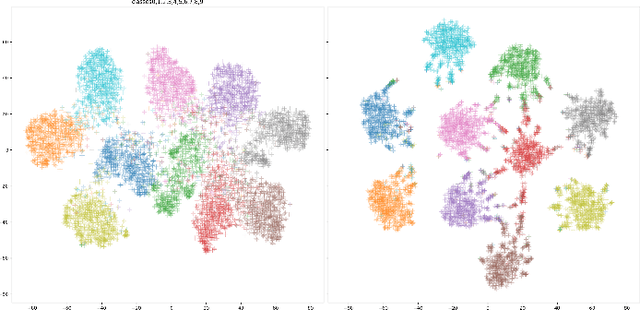
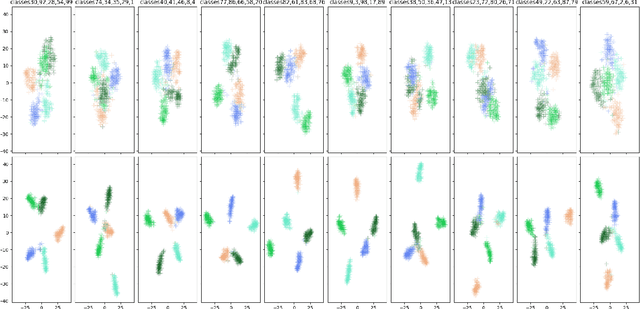
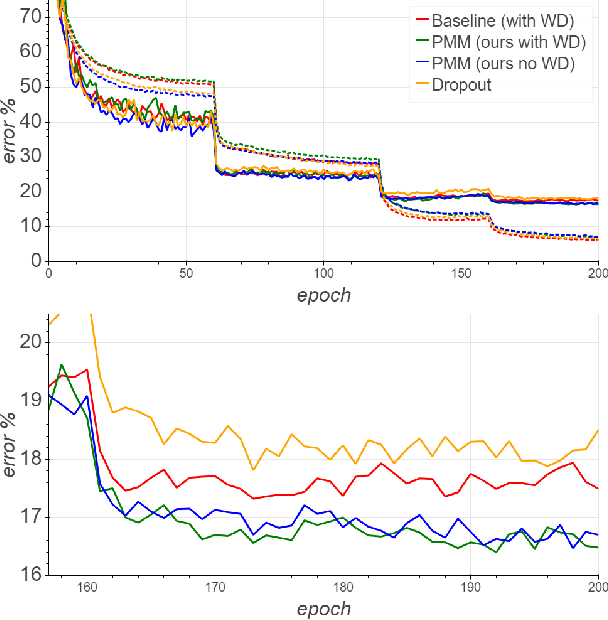
The weight decay regularization term is widely used during training to constrain expressivity, avoid overfitting, and improve generalization. Historically, this concept was borrowed from the SVM maximum margin principle and extended to multi-class deep networks. Carefully inspecting this principle reveals that it is not optimal for multi-class classification in general, and in particular when using deep neural networks. In this paper, we explain why this commonly used principle is not optimal and propose a new regularization scheme, called {\em Pairwise Margin Maximization} (PMM), which measures the minimal amount of displacement an instance should take until its predicted classification is switched. In deep neural networks, PMM can be implemented in the vector space before the network's output layer, i.e., in the deep feature space, where we add an additional normalization term to avoid convergence to a trivial solution. We demonstrate empirically a substantial improvement when training a deep neural network with PMM compared to the standard regularization terms.
Margin-Based Regularization and Selective Sampling in Deep Neural Networks
Sep 13, 2020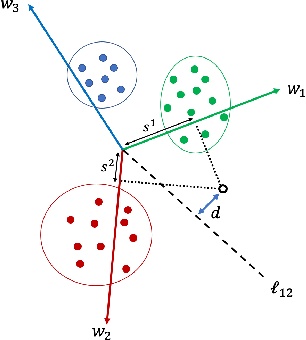
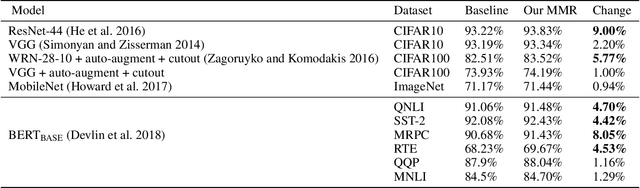
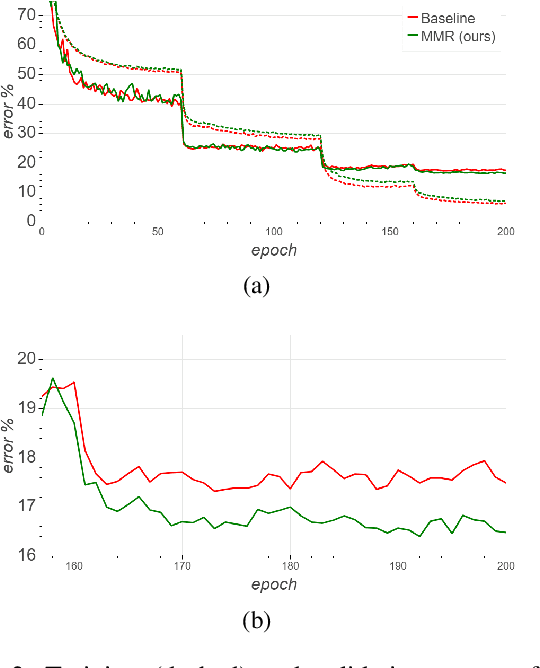
We derive a new margin-based regularization formulation, termed multi-margin regularization (MMR), for deep neural networks (DNNs). The MMR is inspired by principles that were applied in margin analysis of shallow linear classifiers, e.g., support vector machine (SVM). Unlike SVM, MMR is continuously scaled by the radius of the bounding sphere (i.e., the maximal norm of the feature vector in the data), which is constantly changing during training. We empirically demonstrate that by a simple supplement to the loss function, our method achieves better results on various classification tasks across domains. Using the same concept, we also derive a selective sampling scheme and demonstrate accelerated training of DNNs by selecting samples according to a minimal margin score (MMS). This score measures the minimal amount of displacement an input should undergo until its predicted classification is switched. We evaluate our proposed methods on three image classification tasks and six language text classification tasks. Specifically, we show improved empirical results on CIFAR10, CIFAR100 and ImageNet using state-of-the-art convolutional neural networks (CNNs) and BERT-BASE architecture for the MNLI, QQP, QNLI, MRPC, SST-2 and RTE benchmarks.
Selective sampling for accelerating training of deep neural networks
Nov 16, 2019
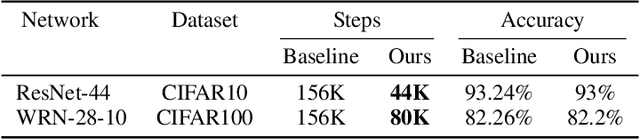
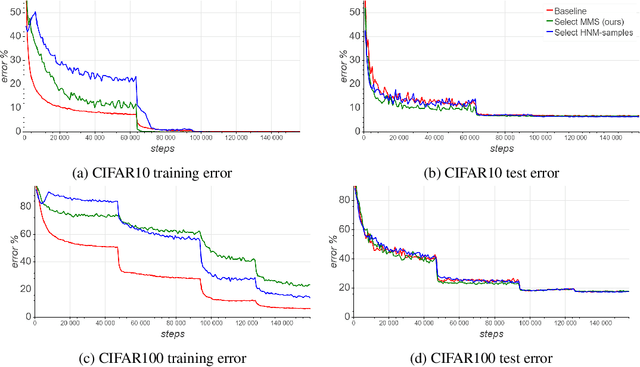
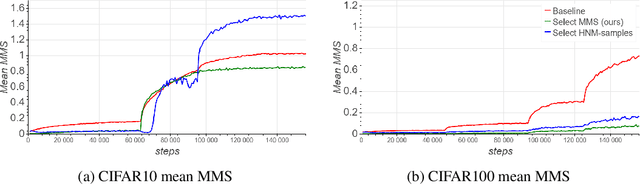
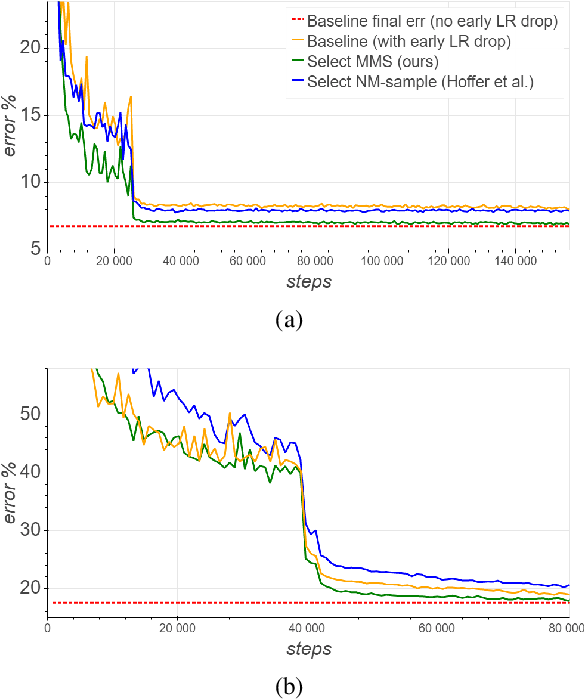
We present a selective sampling method designed to accelerate the training of deep neural networks. To this end, we introduce a novel measurement, the minimal margin score (MMS), which measures the minimal amount of displacement an input should take until its predicted classification is switched. For multi-class linear classification, the MMS measure is a natural generalization of the margin-based selection criterion, which was thoroughly studied in the binary classification setting. In addition, the MMS measure provides an interesting insight into the progress of the training process and can be useful for designing and monitoring new training regimes. Empirically we demonstrate a substantial acceleration when training commonly used deep neural network architectures for popular image classification tasks. The efficiency of our method is compared against the standard training procedures, and against commonly used selective sampling alternatives: Hard negative mining selection, and Entropy-based selection. Finally, we demonstrate an additional speedup when we adopt a more aggressive learning drop regime while using the MMS selective sampling method.
On the Blindspots of Convolutional Networks
Jul 08, 2018
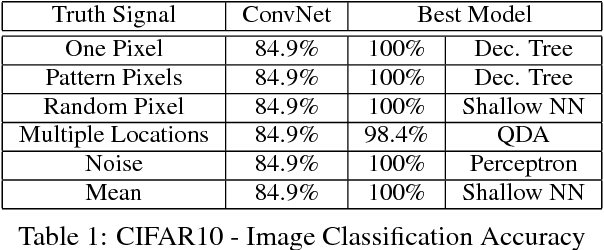
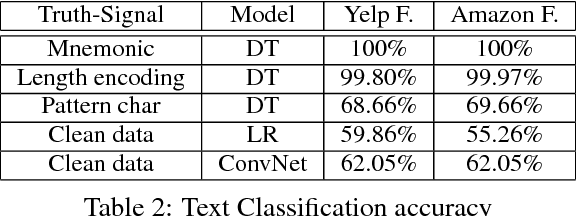

Deep convolutional network has been the state-of-the-art approach for a wide variety of tasks over the last few years. Its successes have, in many cases, turned it into the default model in quite a few domains. In this work, we will demonstrate that convolutional networks have limitations that may, in some cases, hinder it from learning properties of the data, which are easily recognizable by traditional, less demanding, models. To this end, we present a series of competitive analysis studies on image recognition and text analysis tasks, for which convolutional networks are known to provide state-of-the-art results. In our studies, we inject a truth-revealing signal, indiscernible for the network, thus hitting time and again the network's blind spots. The signal does not impair the network's existing performances, but it does provide an opportunity for a significant performance boost by models that can capture it. The various forms of the carefully designed signals shed a light on the strengths and weaknesses of convolutional network, which may provide insights for both theoreticians that study the power of deep architectures, and for practitioners that consider applying convolutional networks to the task at hand.
Actigraphy-based Sleep/Wake Pattern Detection using Convolutional Neural Networks
Feb 22, 2018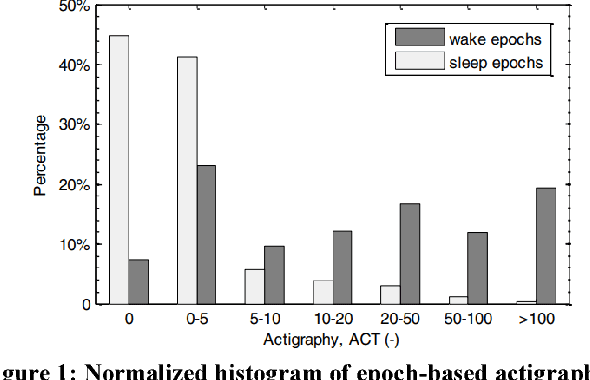

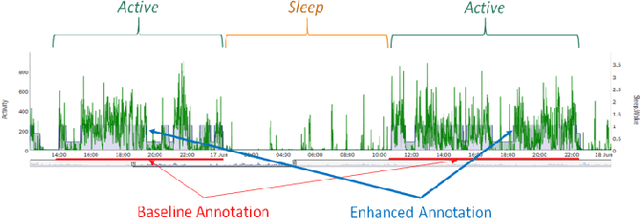

Common medical conditions are often associated with sleep abnormalities. Patients with medical disorders often suffer from poor sleep quality compared to healthy individuals, which in turn may worsen the symptoms of the disorder. Accurate detection of sleep/wake patterns is important in developing personalized digital markers, which can be used for objective measurements and efficient disease management. Big Data technologies and advanced analytics methods hold the promise to revolutionize clinical research processes, enabling the effective blending of digital data into clinical trials. Actigraphy, a non-invasive activity monitoring method is heavily used to detect and evaluate activities and movement disorders, and assess sleep/wake behavior. In order to study the connection between sleep/wake patterns and a cluster headache disorder, activity data was collected using a wearable device in the course of a clinical trial. This study presents two novel modeling schemes that utilize Deep Convolutional Neural Networks (CNN) to identify sleep/wake states. The proposed methods are a sequential CNN, reminiscent of the bi-directional CNN for slot filling, and a Multi-Task Learning (MTL) based model. Furthermore, we expand standard "Sleep" and "Wake" activity states space by adding the "Falling asleep" and "Siesta" states. We show that the proposed methods provide promising results in accurate detection of the expanded sleep/wake states. Finally, we explore the relations between the detected sleep/wake patterns and onset of cluster headache attacks, and present preliminary observations.
Distributed Learning, Communication Complexity and Privacy
May 25, 2012We consider the problem of PAC-learning from distributed data and analyze fundamental communication complexity questions involved. We provide general upper and lower bounds on the amount of communication needed to learn well, showing that in addition to VC-dimension and covering number, quantities such as the teaching-dimension and mistake-bound of a class play an important role. We also present tight results for a number of common concept classes including conjunctions, parity functions, and decision lists. For linear separators, we show that for non-concentrated distributions, we can use a version of the Perceptron algorithm to learn with much less communication than the number of updates given by the usual margin bound. We also show how boosting can be performed in a generic manner in the distributed setting to achieve communication with only logarithmic dependence on 1/epsilon for any concept class, and demonstrate how recent work on agnostic learning from class-conditional queries can be used to achieve low communication in agnostic settings as well. We additionally present an analysis of privacy, considering both differential privacy and a notion of distributional privacy that is especially appealing in this context.