 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Baseline for Detecting Out-of-Distribution Examples in Image Captioning
Jul 12, 2022
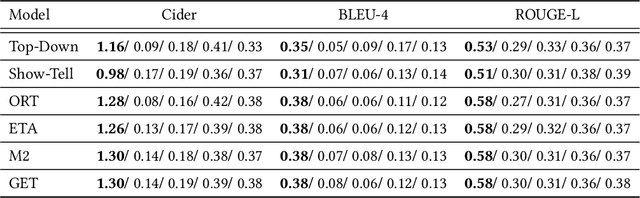

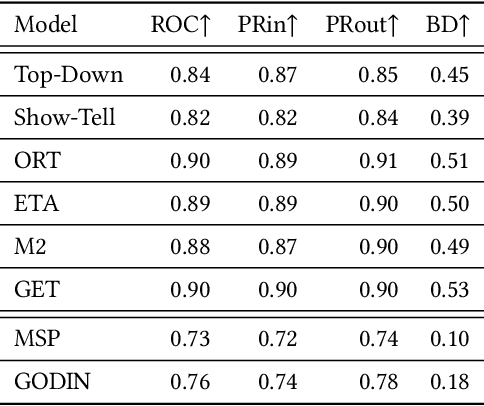
Image captioning research achieved breakthroughs in recent years by developing neural models that can generate diverse and high-quality descriptions for images drawn from the same distribution as training images. However, when facing out-of-distribution (OOD) images, such as corrupted images, or images containing unknown objects, the models fail in generating relevant captions. In this paper, we consider the problem of OOD detection in image captioning. We formulate the problem and suggest an evaluation setup for assessing the model's performance on the task. Then, we analyze and show the effectiveness of the caption's likelihood score at detecting and rejecting OOD images, which implies that the relatedness between the input image and the generated caption is encapsulated within the score.
Redesigning the classification layer by randomizing the class representation vectors
Nov 29, 2020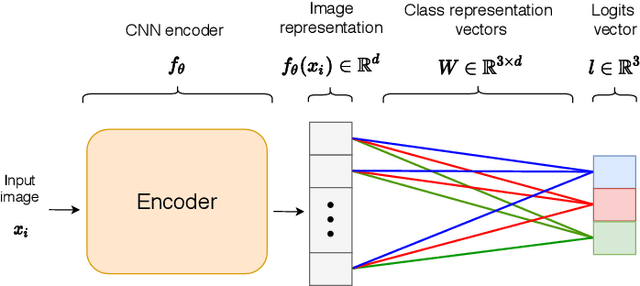
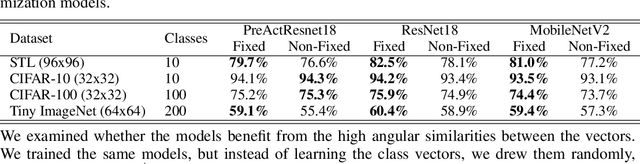
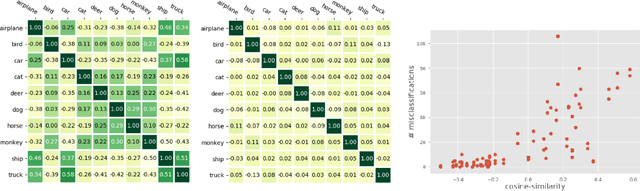
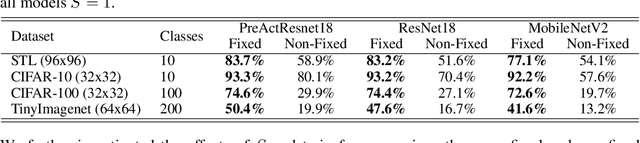
Neural image classification models typically consist of two components. The first is an image encoder, which is responsible for encoding a given raw image into a representative vector. The second is the classification component, which is often implemented by projecting the representative vector onto target class vectors. The target class vectors, along with the rest of the model parameters, are estimated so as to minimize the loss function. In this paper, we analyze how simple design choices for the classification layer affect the learning dynamics. We show that the standard cross-entropy training implicitly captures visual similarities between different classes, which might deteriorate accuracy or even prevents some models from converging. We propose to draw the class vectors randomly and set them as fixed during training, thus invalidating the visual similarities encoded in these vectors. We analyze the effects of keeping the class vectors fixed and show that it can increase the inter-class separability, intra-class compactness, and the overall model accuracy, while maintaining the robustness to image corruptions and the generalization of the learned concepts.
Joint Visual-Textual Embedding for Multimodal Style Search
Jun 15, 2019
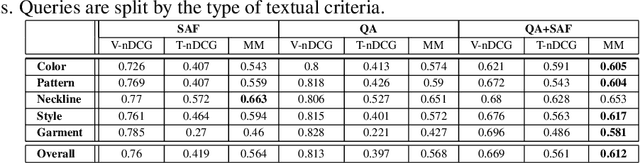


We introduce a multimodal visual-textual search refinement method for fashion garments. Existing search engines do not enable intuitive, interactive, refinement of retrieved results based on the properties of a particular product. We propose a method to retrieve similar items, based on a query item image and textual refinement properties. We believe this method can be leveraged to solve many real-life customer scenarios, in which a similar item in a different color, pattern, length or style is desired. We employ a joint embedding training scheme in which product images and their catalog textual metadata are mapped closely in a shared space. This joint visual-textual embedding space enables manipulating catalog images semantically, based on textual refinement requirements. We propose a new training objective function, Mini-Batch Match Retrieval, and demonstrate its superiority over the commonly used triplet loss. Additionally, we demonstrate the feasibility of adding an attribute extraction module, trained on the same catalog data, and demonstrate how to integrate it within the multimodal search to boost its performance. We introduce an evaluation protocol with an associated benchmark, and compare several approaches.
Generating Diverse and Informative Natural Language Fashion Feedback
Jun 15, 2019
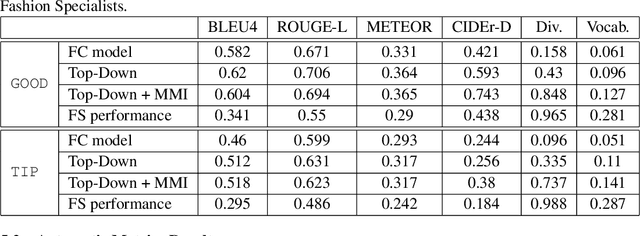
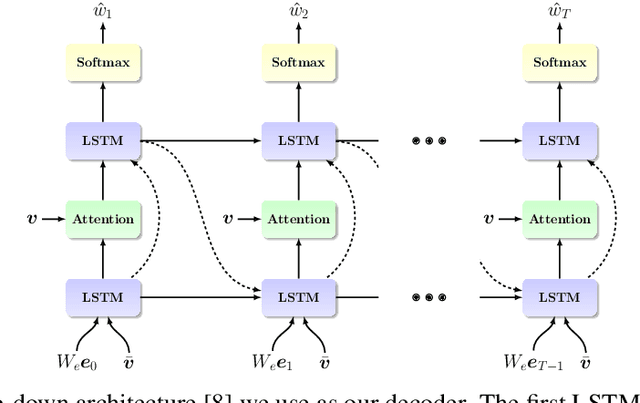
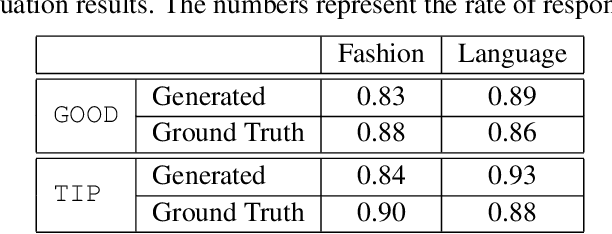
Recent advances in multi-modal vision and language tasks enable a new set of applications. In this paper, we consider the task of generating natural language fashion feedback on outfit images. We collect a unique dataset, which contains outfit images and corresponding positive and constructive fashion feedback. We treat each feedback type separately, and train deep generative encoder-decoder models with visual attention, similar to the standard image captioning pipeline. Following this approach, the generated sentences tend to be too general and non-informative. We propose an alternative decoding technique based on the Maximum Mutual Information objective function, which leads to more diverse and detailed responses. We evaluate our model with common language metrics, and also show human evaluation results. This technology is applied within the ``Alexa, how do I look?'' feature, publicly available in Echo Look devices.
Out-of-Distribution Detection using Multiple Semantic Label Representations
Oct 21, 2018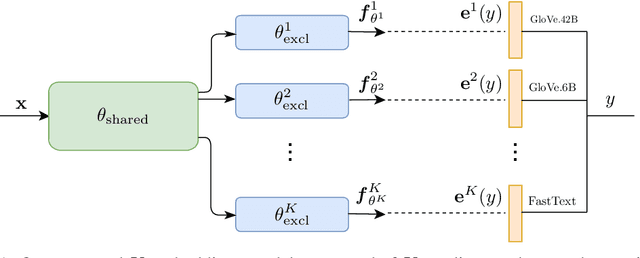
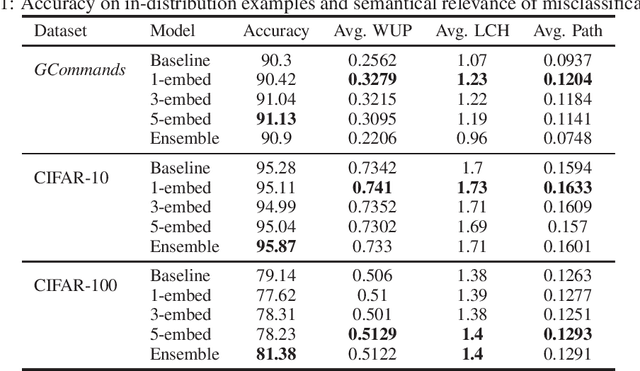
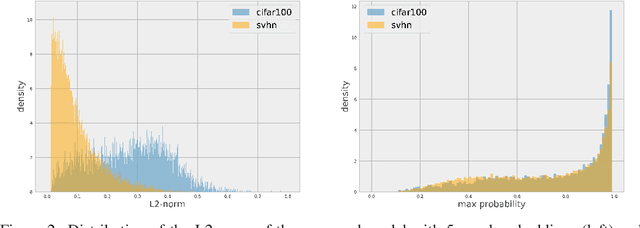
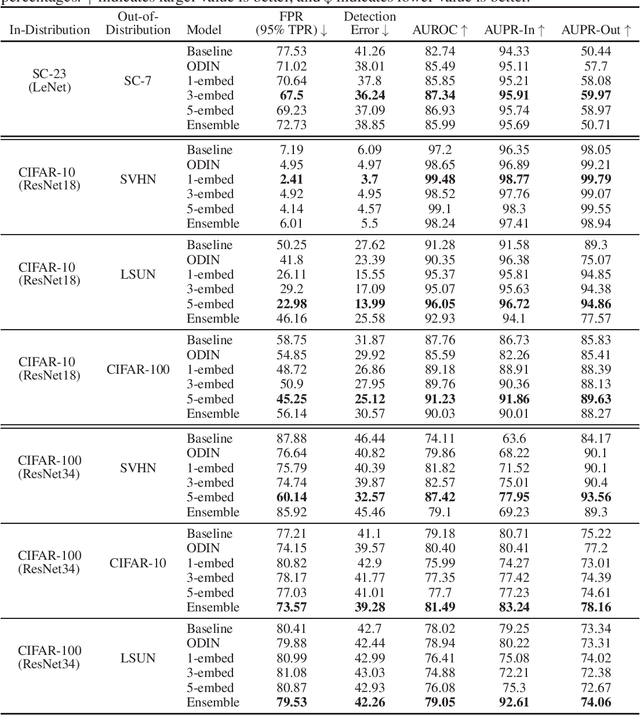
Deep Neural Networks are powerful models that attained remarkable results on a variety of tasks. These models are shown to be extremely efficient when training and test data are drawn from the same distribution. However, it is not clear how a network will act when it is fed with an out-of-distribution example. In this work, we consider the problem of out-of-distribution detection in neural networks. We propose to use multiple semantic dense representations instead of sparse representation as the target label. Specifically, we propose to use several word representations obtained from different corpora or architectures as target labels. We evaluated the proposed model on computer vision, and speech commands detection tasks and compared it to previous methods. Results suggest that our method compares favorably with previous work. Besides, we present the efficiency of our approach for detecting wrongly classified and adversarial examples.
Actigraphy-based Sleep/Wake Pattern Detection using Convolutional Neural Networks
Feb 22, 2018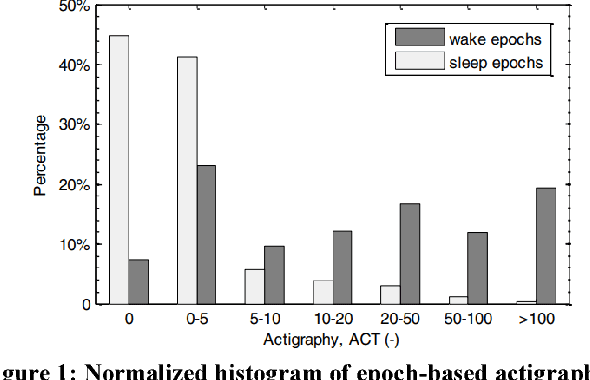

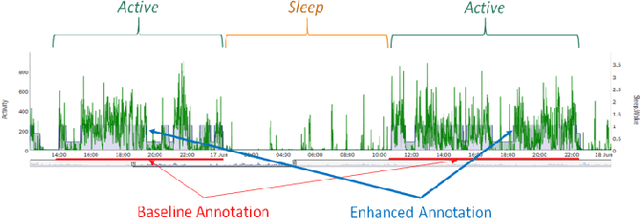

Common medical conditions are often associated with sleep abnormalities. Patients with medical disorders often suffer from poor sleep quality compared to healthy individuals, which in turn may worsen the symptoms of the disorder. Accurate detection of sleep/wake patterns is important in developing personalized digital markers, which can be used for objective measurements and efficient disease management. Big Data technologies and advanced analytics methods hold the promise to revolutionize clinical research processes, enabling the effective blending of digital data into clinical trials. Actigraphy, a non-invasive activity monitoring method is heavily used to detect and evaluate activities and movement disorders, and assess sleep/wake behavior. In order to study the connection between sleep/wake patterns and a cluster headache disorder, activity data was collected using a wearable device in the course of a clinical trial. This study presents two novel modeling schemes that utilize Deep Convolutional Neural Networks (CNN) to identify sleep/wake states. The proposed methods are a sequential CNN, reminiscent of the bi-directional CNN for slot filling, and a Multi-Task Learning (MTL) based model. Furthermore, we expand standard "Sleep" and "Wake" activity states space by adding the "Falling asleep" and "Siesta" states. We show that the proposed methods provide promising results in accurate detection of the expanded sleep/wake states. Finally, we explore the relations between the detected sleep/wake patterns and onset of cluster headache attacks, and present preliminary observations.