 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Baseline for Detecting Out-of-Distribution Examples in Image Captioning
Jul 12, 2022
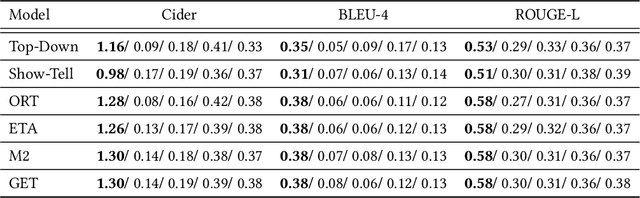

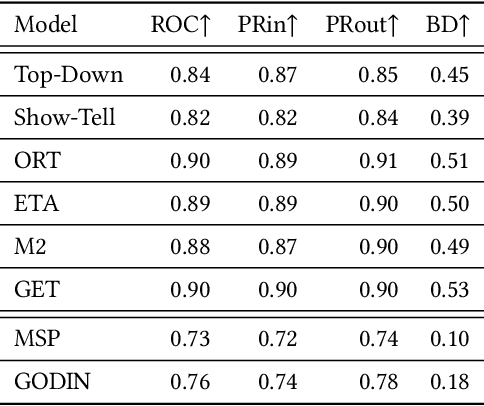
Image captioning research achieved breakthroughs in recent years by developing neural models that can generate diverse and high-quality descriptions for images drawn from the same distribution as training images. However, when facing out-of-distribution (OOD) images, such as corrupted images, or images containing unknown objects, the models fail in generating relevant captions. In this paper, we consider the problem of OOD detection in image captioning. We formulate the problem and suggest an evaluation setup for assessing the model's performance on the task. Then, we analyze and show the effectiveness of the caption's likelihood score at detecting and rejecting OOD images, which implies that the relatedness between the input image and the generated caption is encapsulated within the score.
Redesigning the classification layer by randomizing the class representation vectors
Nov 29, 2020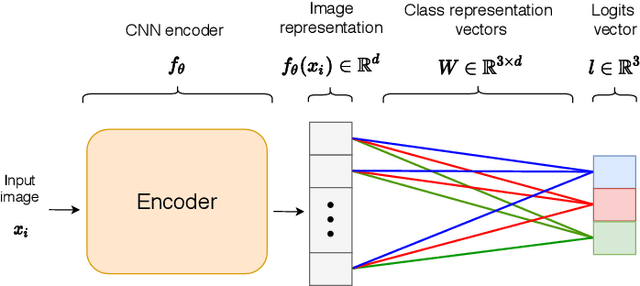
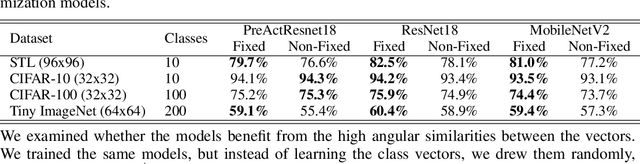
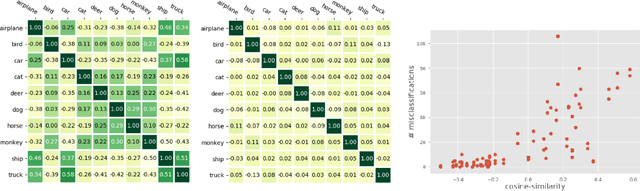
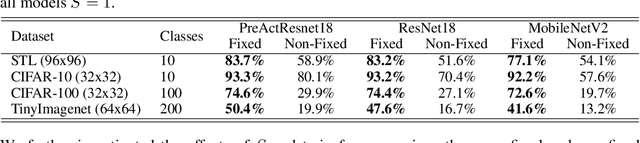
Neural image classification models typically consist of two components. The first is an image encoder, which is responsible for encoding a given raw image into a representative vector. The second is the classification component, which is often implemented by projecting the representative vector onto target class vectors. The target class vectors, along with the rest of the model parameters, are estimated so as to minimize the loss function. In this paper, we analyze how simple design choices for the classification layer affect the learning dynamics. We show that the standard cross-entropy training implicitly captures visual similarities between different classes, which might deteriorate accuracy or even prevents some models from converging. We propose to draw the class vectors randomly and set them as fixed during training, thus invalidating the visual similarities encoded in these vectors. We analyze the effects of keeping the class vectors fixed and show that it can increase the inter-class separability, intra-class compactness, and the overall model accuracy, while maintaining the robustness to image corruptions and the generalization of the learned concepts.