 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining self-supervised peptide sequence models on artificially chopped proteins
Nov 09, 2022
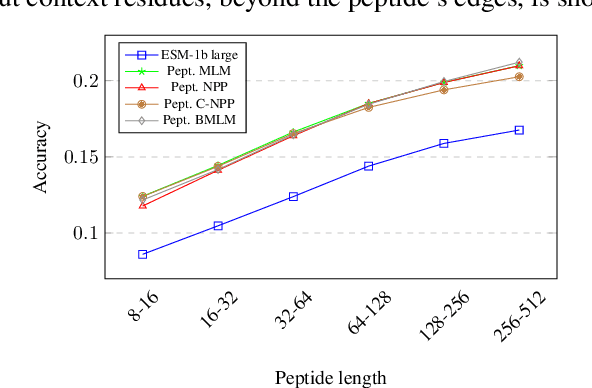

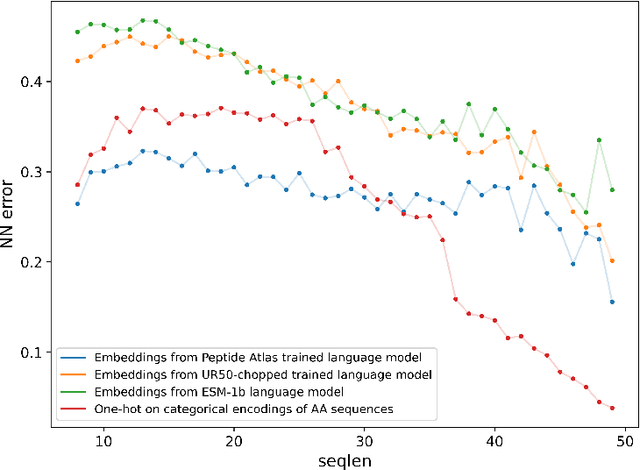
Representation learning for proteins has primarily focused on the global understanding of protein sequences regardless of their length. However, shorter proteins (known as peptides) take on distinct structures and functions compared to their longer counterparts. Unfortunately, there are not as many naturally occurring peptides available to be sequenced and therefore less peptide-specific data to train with. In this paper, we propose a new peptide data augmentation scheme, where we train peptide language models on artificially constructed peptides that are small contiguous subsets of longer, wild-type proteins; we refer to the training peptides as "chopped proteins". We evaluate the representation potential of models trained with chopped proteins versus natural peptides and find that training language models with chopped proteins results in more generalized embeddings for short protein sequences. These peptide-specific models also retain information about the original protein they were derived from better than language models trained on full-length proteins. We compare masked language model training objectives to three novel peptide-specific training objectives: next-peptide prediction, contrastive peptide selection and evolution-weighted MLM. We demonstrate improved zero-shot learning performance for a deep mutational scan peptides benchmark.
Joint Visual-Textual Embedding for Multimodal Style Search
Jun 15, 2019
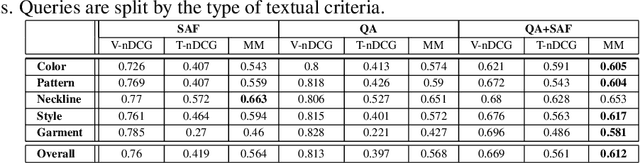


We introduce a multimodal visual-textual search refinement method for fashion garments. Existing search engines do not enable intuitive, interactive, refinement of retrieved results based on the properties of a particular product. We propose a method to retrieve similar items, based on a query item image and textual refinement properties. We believe this method can be leveraged to solve many real-life customer scenarios, in which a similar item in a different color, pattern, length or style is desired. We employ a joint embedding training scheme in which product images and their catalog textual metadata are mapped closely in a shared space. This joint visual-textual embedding space enables manipulating catalog images semantically, based on textual refinement requirements. We propose a new training objective function, Mini-Batch Match Retrieval, and demonstrate its superiority over the commonly used triplet loss. Additionally, we demonstrate the feasibility of adding an attribute extraction module, trained on the same catalog data, and demonstrate how to integrate it within the multimodal search to boost its performance. We introduce an evaluation protocol with an associated benchmark, and compare several approaches.
Generating Diverse and Informative Natural Language Fashion Feedback
Jun 15, 2019
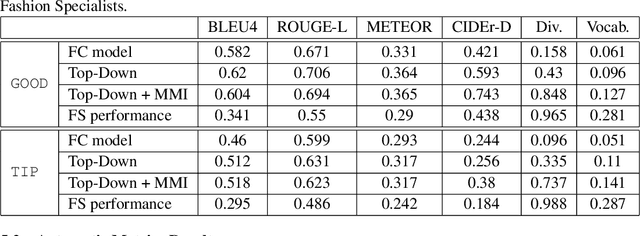
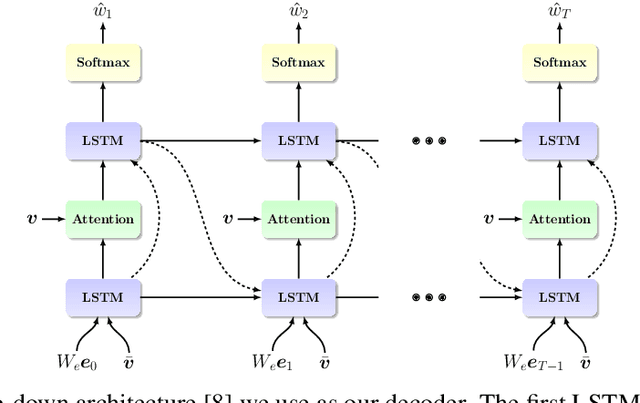
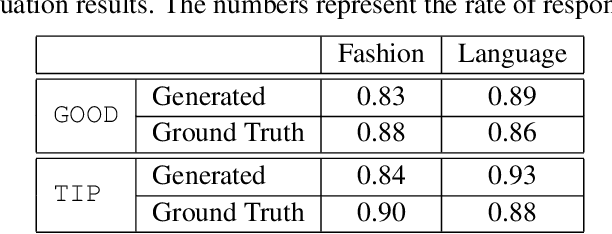
Recent advances in multi-modal vision and language tasks enable a new set of applications. In this paper, we consider the task of generating natural language fashion feedback on outfit images. We collect a unique dataset, which contains outfit images and corresponding positive and constructive fashion feedback. We treat each feedback type separately, and train deep generative encoder-decoder models with visual attention, similar to the standard image captioning pipeline. Following this approach, the generated sentences tend to be too general and non-informative. We propose an alternative decoding technique based on the Maximum Mutual Information objective function, which leads to more diverse and detailed responses. We evaluate our model with common language metrics, and also show human evaluation results. This technology is applied within the ``Alexa, how do I look?'' feature, publicly available in Echo Look devices.
RNN Fisher Vectors for Action Recognition and Image Annotation
Dec 12, 2015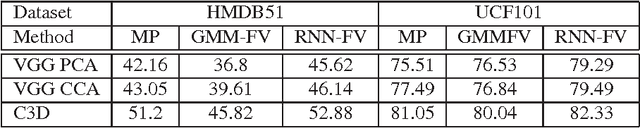
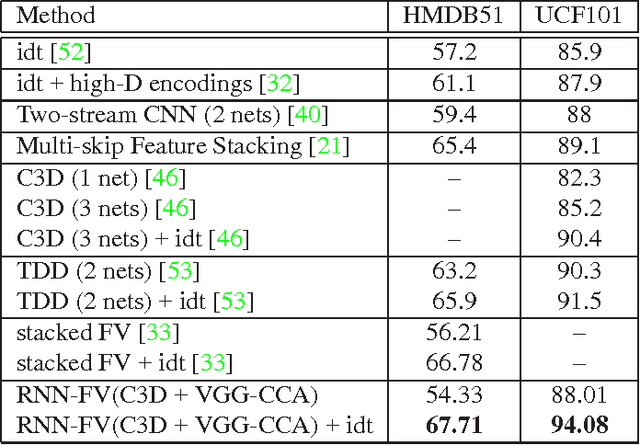
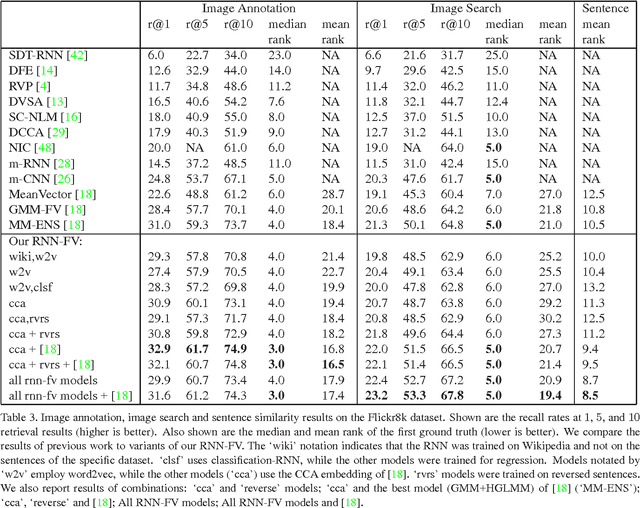
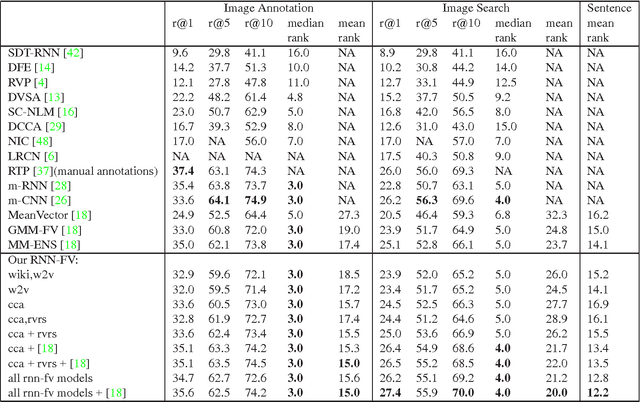
Recurrent Neural Networks (RNNs) have had considerable success in classifying and predicting sequences. We demonstrate that RNNs can be effectively used in order to encode sequences and provide effective representations. The methodology we use is based on Fisher Vectors, where the RNNs are the generative probabilistic models and the partial derivatives are computed using backpropagation. State of the art results are obtained in two central but distant tasks, which both rely on sequences: video action recognition and image annotation. We also show a surprising transfer learning result from the task of image annotation to the task of video action recognition.
Fisher Vectors Derived from Hybrid Gaussian-Laplacian Mixture Models for Image Annotation
Jan 24, 2015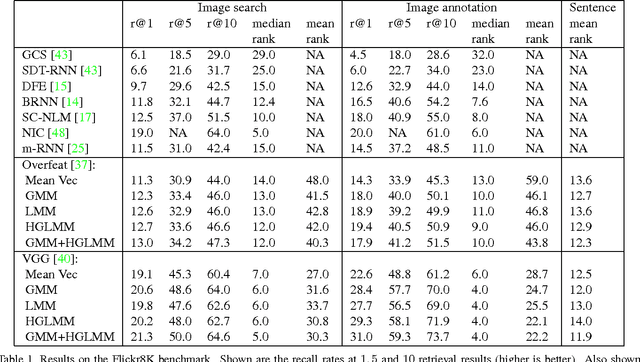

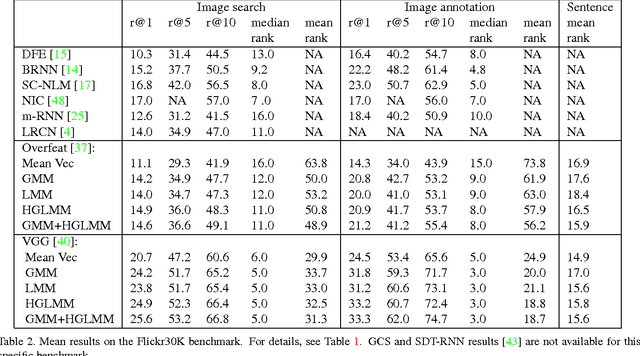
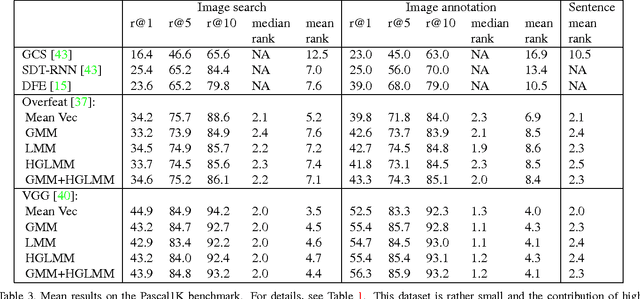
In the traditional object recognition pipeline, descriptors are densely sampled over an image, pooled into a high dimensional non-linear representation and then passed to a classifier. In recent years, Fisher Vectors have proven empirically to be the leading representation for a large variety of applications. The Fisher Vector is typically taken as the gradients of the log-likelihood of descriptors, with respect to the parameters of a Gaussian Mixture Model (GMM). Motivated by the assumption that different distributions should be applied for different datasets, we present two other Mixture Models and derive their Expectation-Maximization and Fisher Vector expressions. The first is a Laplacian Mixture Model (LMM), which is based on the Laplacian distribution. The second Mixture Model presented is a Hybrid Gaussian-Laplacian Mixture Model (HGLMM) which is based on a weighted geometric mean of the Gaussian and Laplacian distribution. An interesting property of the Expectation-Maximization algorithm for the latter is that in the maximization step, each dimension in each component is chosen to be either a Gaussian or a Laplacian. Finally, by using the new Fisher Vectors derived from HGLMMs, we achieve state-of-the-art results for both the image annotation and the image search by a sentence tasks.