 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualizing Thought: Conceptual Diagrams Enable Robust Planning in LMMs
Mar 14, 2025Human reasoning relies on constructing and manipulating mental models-simplified internal representations of situations that we use to understand and solve problems. Conceptual diagrams (for example, sketches drawn by humans to aid reasoning) externalize these mental models, abstracting irrelevant details to efficiently capture relational and spatial information. In contrast, Large Language Models (LLMs) and Large Multimodal Models (LMMs) predominantly reason through textual representations, limiting their effectiveness in complex multi-step combinatorial and planning tasks. In this paper, we propose a zero-shot fully automatic framework that enables LMMs to reason through multiple chains of self-generated intermediate conceptual diagrams, significantly enhancing their combinatorial planning capabilities. Our approach does not require any human initialization beyond a natural language description of the task. It integrates both textual and diagrammatic reasoning within an optimized graph-of-thought inference framework, enhanced by beam search and depth-wise backtracking. Evaluated on multiple challenging PDDL planning domains, our method substantially improves GPT-4o's performance (for example, from 35.5% to 90.2% in Blocksworld). On more difficult planning domains with solution depths up to 40, our approach outperforms even the o1-preview reasoning model (for example, over 13% improvement in Parking). These results highlight the value of conceptual diagrams as a complementary reasoning medium in LMMs.
Beyond Weak Perspective for Monocular 3D Human Pose Estimation
Sep 14, 2020
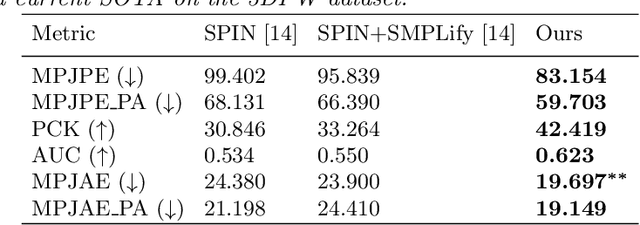
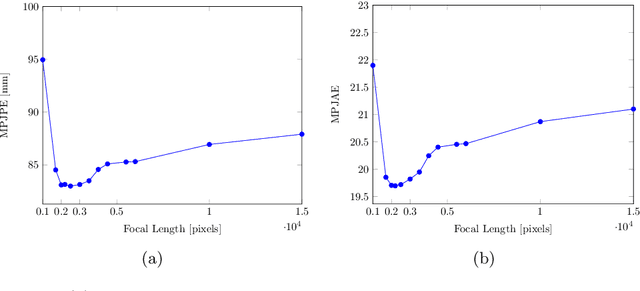
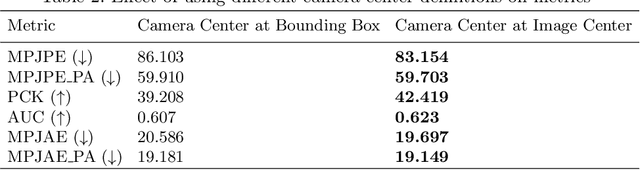
We consider the task of 3D joints location and orientation prediction from a monocular video with the skinned multi-person linear (SMPL) model. We first infer 2D joints locations with an off-the-shelf pose estimation algorithm. We use the SPIN algorithm and estimate initial predictions of body pose, shape and camera parameters from a deep regression neural network. We then adhere to the SMPLify algorithm which receives those initial parameters, and optimizes them so that inferred 3D joints from the SMPL model would fit the 2D joints locations. This algorithm involves a projection step of 3D joints to the 2D image plane. The conventional approach is to follow weak perspective assumptions which use ad-hoc focal length. Through experimentation on the 3D Poses in the Wild (3DPW) dataset, we show that using full perspective projection, with the correct camera center and an approximated focal length, provides favorable results. Our algorithm has resulted in a winning entry for the 3DPW Challenge, reaching first place in joints orientation accuracy.
Joint Visual-Textual Embedding for Multimodal Style Search
Jun 15, 2019
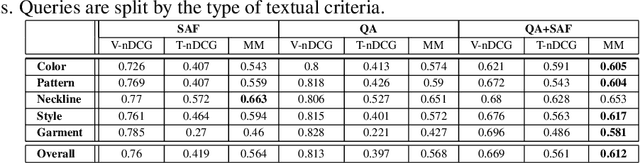


We introduce a multimodal visual-textual search refinement method for fashion garments. Existing search engines do not enable intuitive, interactive, refinement of retrieved results based on the properties of a particular product. We propose a method to retrieve similar items, based on a query item image and textual refinement properties. We believe this method can be leveraged to solve many real-life customer scenarios, in which a similar item in a different color, pattern, length or style is desired. We employ a joint embedding training scheme in which product images and their catalog textual metadata are mapped closely in a shared space. This joint visual-textual embedding space enables manipulating catalog images semantically, based on textual refinement requirements. We propose a new training objective function, Mini-Batch Match Retrieval, and demonstrate its superiority over the commonly used triplet loss. Additionally, we demonstrate the feasibility of adding an attribute extraction module, trained on the same catalog data, and demonstrate how to integrate it within the multimodal search to boost its performance. We introduce an evaluation protocol with an associated benchmark, and compare several approaches.
Generating Diverse and Informative Natural Language Fashion Feedback
Jun 15, 2019
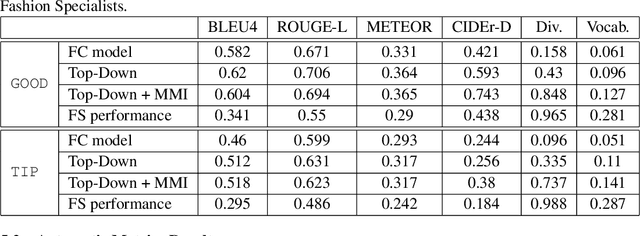
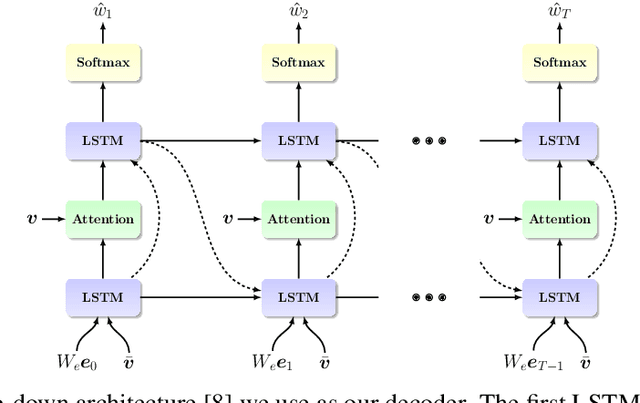
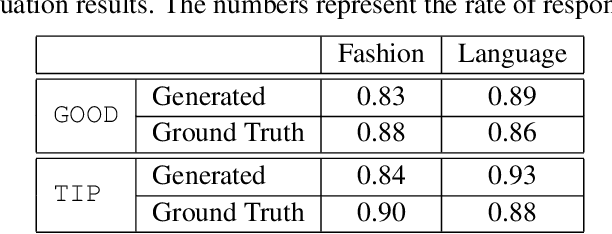
Recent advances in multi-modal vision and language tasks enable a new set of applications. In this paper, we consider the task of generating natural language fashion feedback on outfit images. We collect a unique dataset, which contains outfit images and corresponding positive and constructive fashion feedback. We treat each feedback type separately, and train deep generative encoder-decoder models with visual attention, similar to the standard image captioning pipeline. Following this approach, the generated sentences tend to be too general and non-informative. We propose an alternative decoding technique based on the Maximum Mutual Information objective function, which leads to more diverse and detailed responses. We evaluate our model with common language metrics, and also show human evaluation results. This technology is applied within the ``Alexa, how do I look?'' feature, publicly available in Echo Look devices.