 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinaural sound source localization using a hybrid time and frequency domain model
Feb 06, 2024



This paper introduces a new approach to sound source localization using head-related transfer function (HRTF) characteristics, which enable precise full-sphere localization from raw data. While previous research focused primarily on using extensive microphone arrays in the frontal plane, this arrangement often encountered limitations in accuracy and robustness when dealing with smaller microphone arrays. Our model proposes using both time and frequency domain for sound source localization while utilizing Deep Learning (DL) approach. The performance of our proposed model, surpasses the current state-of-the-art results. Specifically, it boasts an average angular error of $0.24 degrees and an average Euclidean distance of 0.01 meters, while the known state-of-the-art gives average angular error of 19.07 degrees and average Euclidean distance of 1.08 meters. This level of accuracy is of paramount importance for a wide range of applications, including robotics, virtual reality, and aiding individuals with cochlear implants (CI).
OrthoGAN: Multifaceted Semantics for Disentangled Face Editing
Nov 21, 2022



This paper describes a new technique for finding disentangled semantic directions in the latent space of StyleGAN. OrthoGAN identifies meaningful orthogonal subspaces that allow editing of one human face attribute, while minimizing undesired changes in other attributes. Our model is capable of editing a single attribute in multiple directions. Resulting in a range of possible generated images. We compare our scheme with three state-of-the-art models and show that our method outperforms them in terms of face editing and disentanglement capabilities. Additionally, we suggest quantitative measures for evaluating attribute separation and disentanglement, and exhibit the superiority of our model with respect to those measures.
DDNeRF: Depth Distribution Neural Radiance Fields
Mar 30, 2022
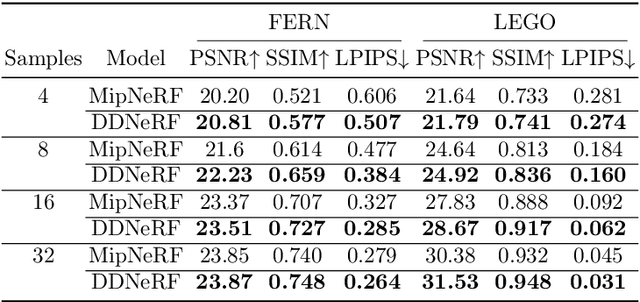


In recent years, the field of implicit neural representation has progressed significantly. Models such as neural radiance fields (NeRF), which uses relatively small neural networks, can represent high-quality scenes and achieve state-of-the-art results for novel view synthesis. Training these types of networks, however, is still computationally very expensive. We present depth distribution neural radiance field (DDNeRF), a new method that significantly increases sampling efficiency along rays during training while achieving superior results for a given sampling budget. DDNeRF achieves this by learning a more accurate representation of the density distribution along rays. More specifically, we train a coarse model to predict the internal distribution of the transparency of an input volume in addition to the volume's total density. This finer distribution then guides the sampling procedure of the fine model. This method allows us to use fewer samples during training while reducing computational resources.
DeepShadow: Neural Shape from Shadow
Mar 28, 2022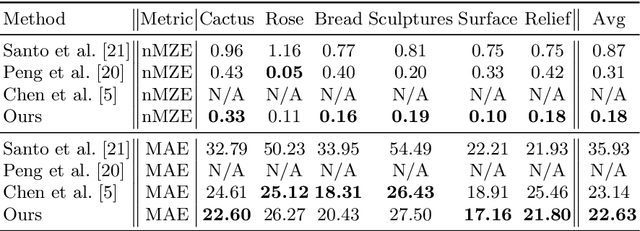
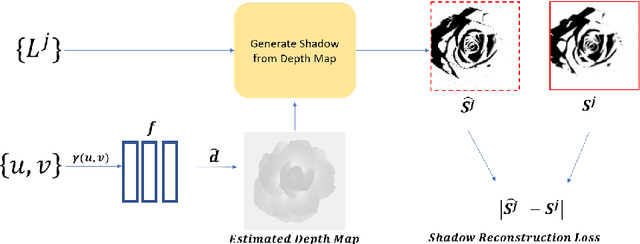

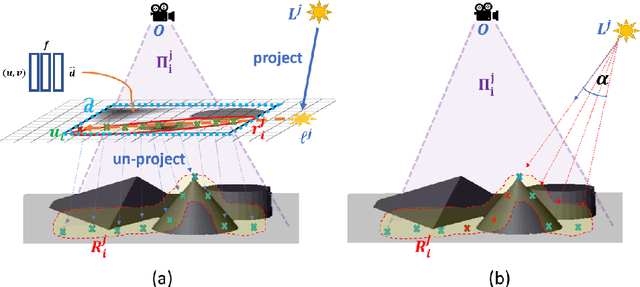
This paper presents DeepShadow, a one-shot method for recovering the depth map and surface normals from photometric stereo shadow maps. Previous works that try to recover the surface normals from photometric stereo images treat cast shadows as a disturbance. We show that the self and cast shadows not only do not disturb 3D reconstruction, but can be used alone, as a strong learning signal, to recover the depth map and surface normals. We demonstrate that 3D reconstruction from shadows can even outperform shape-from-shading in certain cases. To the best of our knowledge, our method is the first to reconstruct 3D shape-from-shadows using neural networks. The method does not require any pre-training or expensive labeled data, and is optimized during inference time.
Pairwise Margin Maximization for Deep Neural Networks
Oct 09, 2021
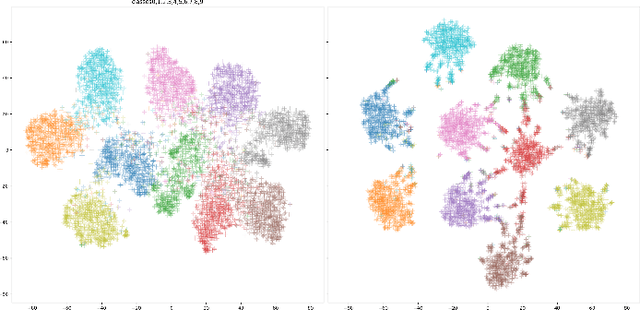
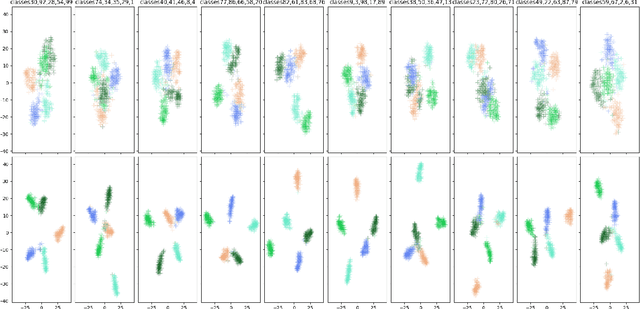
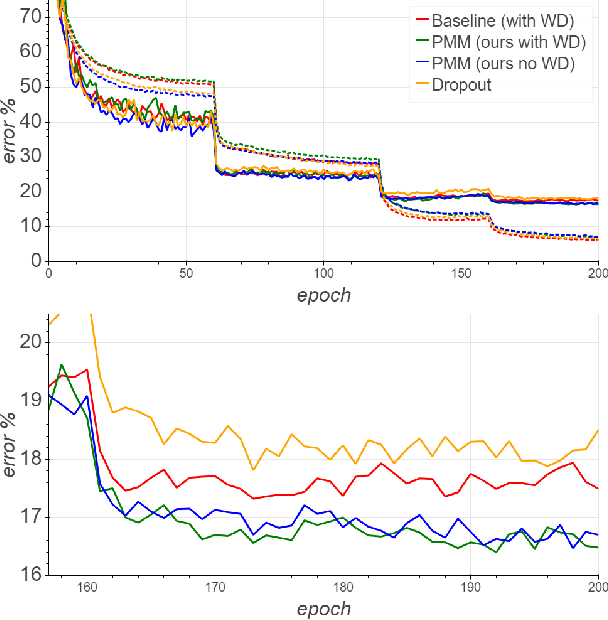
The weight decay regularization term is widely used during training to constrain expressivity, avoid overfitting, and improve generalization. Historically, this concept was borrowed from the SVM maximum margin principle and extended to multi-class deep networks. Carefully inspecting this principle reveals that it is not optimal for multi-class classification in general, and in particular when using deep neural networks. In this paper, we explain why this commonly used principle is not optimal and propose a new regularization scheme, called {\em Pairwise Margin Maximization} (PMM), which measures the minimal amount of displacement an instance should take until its predicted classification is switched. In deep neural networks, PMM can be implemented in the vector space before the network's output layer, i.e., in the deep feature space, where we add an additional normalization term to avoid convergence to a trivial solution. We demonstrate empirically a substantial improvement when training a deep neural network with PMM compared to the standard regularization terms.
Margin-Based Regularization and Selective Sampling in Deep Neural Networks
Sep 13, 2020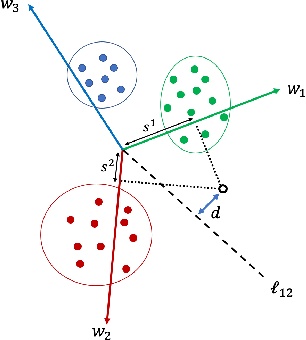
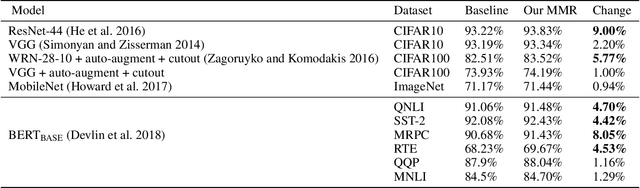
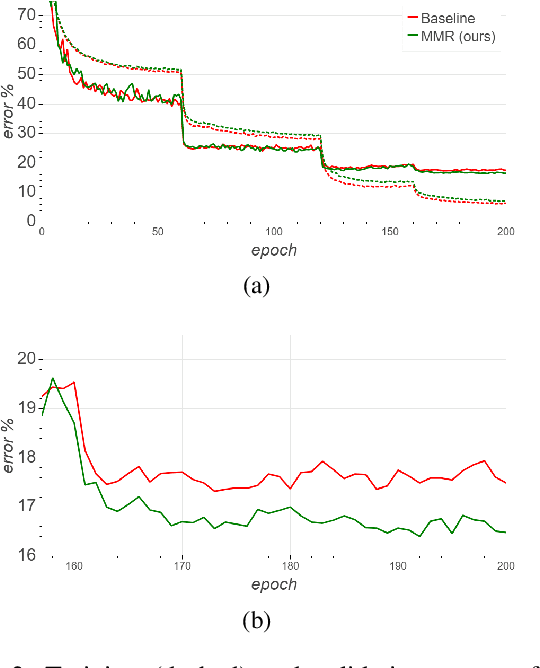
We derive a new margin-based regularization formulation, termed multi-margin regularization (MMR), for deep neural networks (DNNs). The MMR is inspired by principles that were applied in margin analysis of shallow linear classifiers, e.g., support vector machine (SVM). Unlike SVM, MMR is continuously scaled by the radius of the bounding sphere (i.e., the maximal norm of the feature vector in the data), which is constantly changing during training. We empirically demonstrate that by a simple supplement to the loss function, our method achieves better results on various classification tasks across domains. Using the same concept, we also derive a selective sampling scheme and demonstrate accelerated training of DNNs by selecting samples according to a minimal margin score (MMS). This score measures the minimal amount of displacement an input should undergo until its predicted classification is switched. We evaluate our proposed methods on three image classification tasks and six language text classification tasks. Specifically, we show improved empirical results on CIFAR10, CIFAR100 and ImageNet using state-of-the-art convolutional neural networks (CNNs) and BERT-BASE architecture for the MNLI, QQP, QNLI, MRPC, SST-2 and RTE benchmarks.
Faithful Autoencoder Interpolation by Shaping the Latent Space
Aug 04, 2020



One of the fascinating properties of deep learning is the ability of the network to reveal the underlying factors characterizing elements in datasets of different types. Autoencoders represent an effective approach for computing these factors. Autoencoders have been studied in the context of their ability to interpolate between data points by decoding mixed latent vectors. However, this interpolation often incorporates disrupting artifacts or produces unrealistic images during reconstruction. We argue that these incongruities are due to the manifold structure of the latent space where interpolated latent vectors deviate from the data manifold. In this paper, we propose a regularization technique that shapes the latent space following the manifold assumption while enforcing the manifold to be smooth and convex. This regularization enables faithful interpolation between data points and can be used as a general regularization as well for avoiding overfitting and constraining the model complexity.
Proximity Preserving Binary Code using Signed Graph-Cut
Feb 05, 2020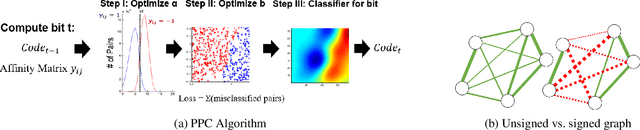
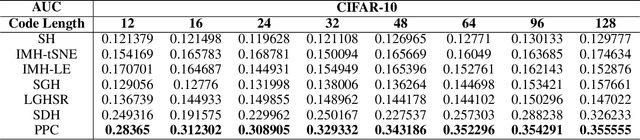
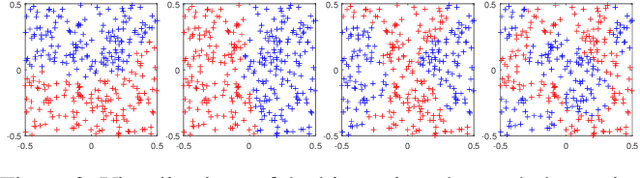

We introduce a binary embedding framework, called Proximity Preserving Code (PPC), which learns similarity and dissimilarity between data points to create a compact and affinity-preserving binary code. This code can be used to apply fast and memory-efficient approximation to nearest-neighbor searches. Our framework is flexible, enabling different proximity definitions between data points. In contrast to previous methods that extract binary codes based on unsigned graph partitioning, our system models the attractive and repulsive forces in the data by incorporating positive and negative graph weights. The proposed framework is shown to boil down to finding the minimal cut of a signed graph, a problem known to be NP-hard. We offer an efficient approximation and achieve superior results by constructing the code bit after bit. We show that the proposed approximation is superior to the commonly used spectral methods with respect to both accuracy and complexity. Thus, it is useful for many other problems that can be translated into signed graph cut.
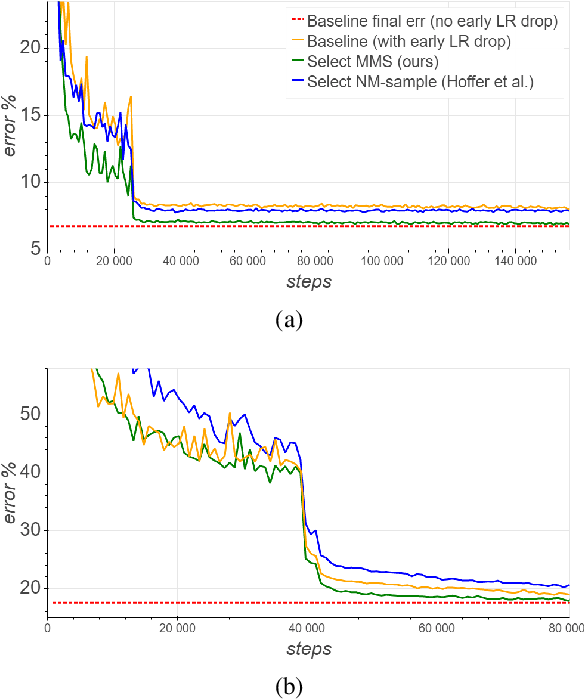
Selective sampling for accelerating training of deep neural networks
Nov 16, 2019
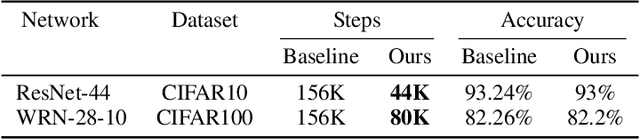
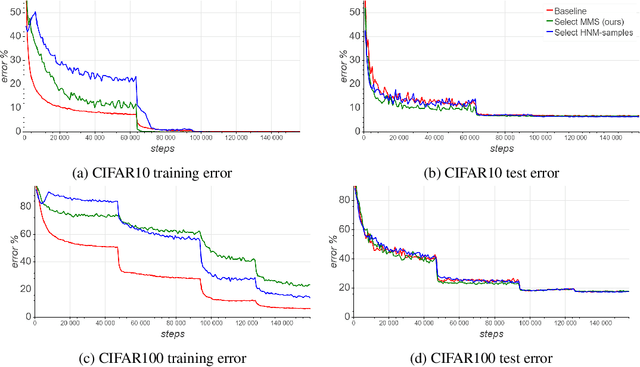
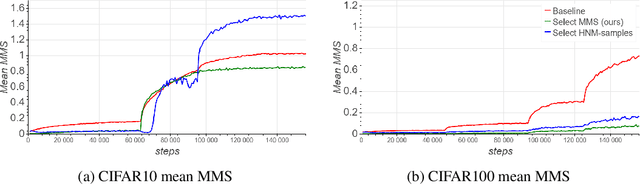
We present a selective sampling method designed to accelerate the training of deep neural networks. To this end, we introduce a novel measurement, the minimal margin score (MMS), which measures the minimal amount of displacement an input should take until its predicted classification is switched. For multi-class linear classification, the MMS measure is a natural generalization of the margin-based selection criterion, which was thoroughly studied in the binary classification setting. In addition, the MMS measure provides an interesting insight into the progress of the training process and can be useful for designing and monitoring new training regimes. Empirically we demonstrate a substantial acceleration when training commonly used deep neural network architectures for popular image classification tasks. The efficiency of our method is compared against the standard training procedures, and against commonly used selective sampling alternatives: Hard negative mining selection, and Entropy-based selection. Finally, we demonstrate an additional speedup when we adopt a more aggressive learning drop regime while using the MMS selective sampling method.