 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFollow the Flow: On Information Flow Across Textual Tokens in Text-to-Image Models
Apr 01, 2025Text-to-Image (T2I) models often suffer from issues such as semantic leakage, incorrect feature binding, and omissions of key concepts in the generated image. This work studies these phenomena by looking into the role of information flow between textual token representations. To this end, we generate images by applying the diffusion component on a subset of contextual token representations in a given prompt and observe several interesting phenomena. First, in many cases, a word or multiword expression is fully represented by one or two tokens, while other tokens are redundant. For example, in "San Francisco's Golden Gate Bridge", the token "gate" alone captures the full expression. We demonstrate the redundancy of these tokens by removing them after textual encoding and generating an image from the resulting representation. Surprisingly, we find that this process not only maintains image generation performance but also reduces errors by 21\% compared to standard generation. We then show that information can also flow between different expressions in a sentence, which often leads to semantic leakage. Based on this observation, we propose a simple, training-free method to mitigate semantic leakage: replacing the leaked item's representation after the textual encoding with its uncontextualized representation. Remarkably, this simple approach reduces semantic leakage by 85\%. Overall, our work provides a comprehensive analysis of information flow across textual tokens in T2I models, offering both novel insights and practical benefits.
Padding Tone: A Mechanistic Analysis of Padding Tokens in T2I Models
Jan 12, 2025



Text-to-image (T2I) diffusion models rely on encoded prompts to guide the image generation process. Typically, these prompts are extended to a fixed length by adding padding tokens before text encoding. Despite being a default practice, the influence of padding tokens on the image generation process has not been investigated. In this work, we conduct the first in-depth analysis of the role padding tokens play in T2I models. We develop two causal techniques to analyze how information is encoded in the representation of tokens across different components of the T2I pipeline. Using these techniques, we investigate when and how padding tokens impact the image generation process. Our findings reveal three distinct scenarios: padding tokens may affect the model's output during text encoding, during the diffusion process, or be effectively ignored. Moreover, we identify key relationships between these scenarios and the model's architecture (cross or self-attention) and its training process (frozen or trained text encoder). These insights contribute to a deeper understanding of the mechanisms of padding tokens, potentially informing future model design and training practices in T2I systems.
NL-Eye: Abductive NLI for Images
Oct 03, 2024

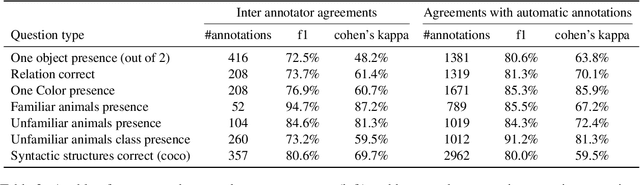
Will a Visual Language Model (VLM)-based bot warn us about slipping if it detects a wet floor? Recent VLMs have demonstrated impressive capabilities, yet their ability to infer outcomes and causes remains underexplored. To address this, we introduce NL-Eye, a benchmark designed to assess VLMs' visual abductive reasoning skills. NL-Eye adapts the abductive Natural Language Inference (NLI) task to the visual domain, requiring models to evaluate the plausibility of hypothesis images based on a premise image and explain their decisions. NL-Eye consists of 350 carefully curated triplet examples (1,050 images) spanning diverse reasoning categories: physical, functional, logical, emotional, cultural, and social. The data curation process involved two steps - writing textual descriptions and generating images using text-to-image models, both requiring substantial human involvement to ensure high-quality and challenging scenes. Our experiments show that VLMs struggle significantly on NL-Eye, often performing at random baseline levels, while humans excel in both plausibility prediction and explanation quality. This demonstrates a deficiency in the abductive reasoning capabilities of modern VLMs. NL-Eye represents a crucial step toward developing VLMs capable of robust multimodal reasoning for real-world applications, including accident-prevention bots and generated video verification.
LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations
Oct 03, 2024
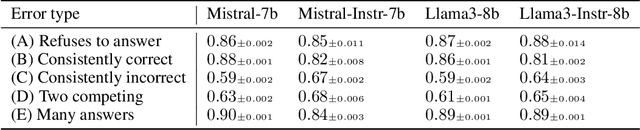
Large language models (LLMs) often produce errors, including factual inaccuracies, biases, and reasoning failures, collectively referred to as "hallucinations". Recent studies have demonstrated that LLMs' internal states encode information regarding the truthfulness of their outputs, and that this information can be utilized to detect errors. In this work, we show that the internal representations of LLMs encode much more information about truthfulness than previously recognized. We first discover that the truthfulness information is concentrated in specific tokens, and leveraging this property significantly enhances error detection performance. Yet, we show that such error detectors fail to generalize across datasets, implying that -- contrary to prior claims -- truthfulness encoding is not universal but rather multifaceted. Next, we show that internal representations can also be used for predicting the types of errors the model is likely to make, facilitating the development of tailored mitigation strategies. Lastly, we reveal a discrepancy between LLMs' internal encoding and external behavior: they may encode the correct answer, yet consistently generate an incorrect one. Taken together, these insights deepen our understanding of LLM errors from the model's internal perspective, which can guide future research on enhancing error analysis and mitigation.
Diffusion Lens: Interpreting Text Encoders in Text-to-Image Pipelines
Mar 09, 2024
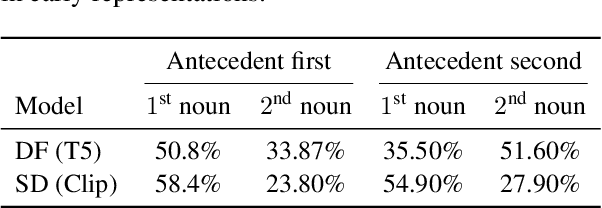

Text-to-image diffusion models (T2I) use a latent representation of a text prompt to guide the image generation process. However, the process by which the encoder produces the text representation is unknown. We propose the Diffusion Lens, a method for analyzing the text encoder of T2I models by generating images from its intermediate representations. Using the Diffusion Lens, we perform an extensive analysis of two recent T2I models. Exploring compound prompts, we find that complex scenes describing multiple objects are composed progressively and more slowly compared to simple scenes; Exploring knowledge retrieval, we find that representation of uncommon concepts requires further computation compared to common concepts, and that knowledge retrieval is gradual across layers. Overall, our findings provide valuable insights into the text encoder component in T2I pipelines.
A Dataset for Metaphor Detection in Early Medieval Hebrew Poetry
Feb 27, 2024
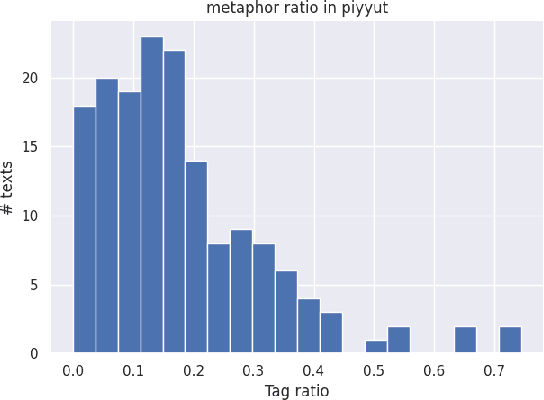
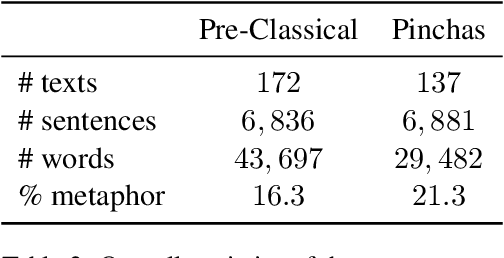
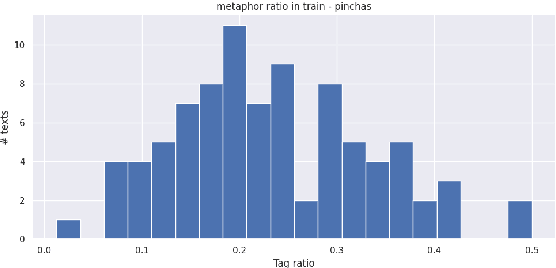
There is a large volume of late antique and medieval Hebrew texts. They represent a crucial linguistic and cultural bridge between Biblical and modern Hebrew. Poetry is prominent in these texts and one of its main haracteristics is the frequent use of metaphor. Distinguishing figurative and literal language use is a major task for scholars of the Humanities, especially in the fields of literature, linguistics, and hermeneutics. This paper presents a new, challenging dataset of late antique and medieval Hebrew poetry with expert annotations of metaphor, as well as some baseline results, which we hope will facilitate further research in this area.
TRBLLmaker -- Transformer Reads Between Lyrics Lines maker
Dec 09, 2022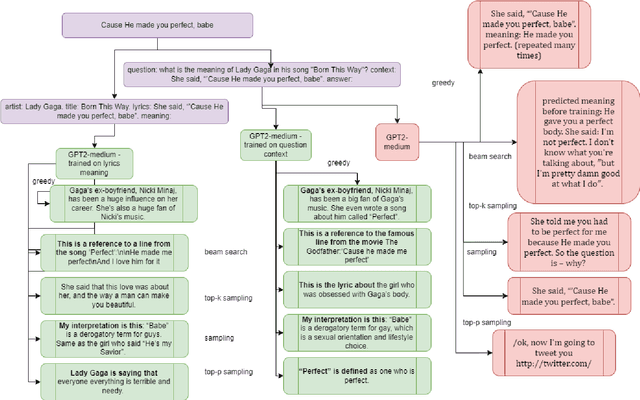
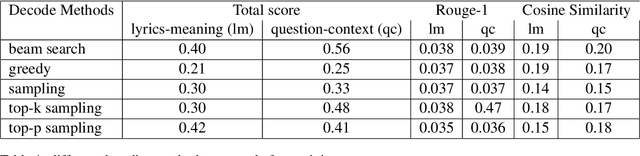
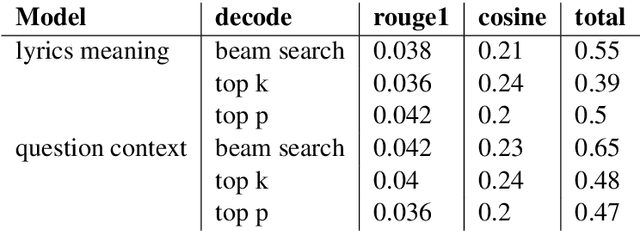
Even for us, it can be challenging to comprehend the meaning of songs. As part of this project, we explore the process of generating the meaning of songs. Despite the widespread use of text-to-text models, few attempts have been made to achieve a similar objective. Songs are primarily studied in the context of sentiment analysis. This involves identifying opinions and emotions in texts, evaluating them as positive or negative, and utilizing these evaluations to make music recommendations. In this paper, we present a generative model that offers implicit meanings for several lines of a song. Our model uses a decoder Transformer architecture GPT-2, where the input is the lyrics of a song. Furthermore, we compared the performance of this architecture with that of the encoder-decoder Transformer architecture of the T5 model. We also examined the effect of different prompt types with the option of appending additional information, such as the name of the artist and the title of the song. Moreover, we tested different decoding methods with different training parameters and evaluated our results using ROUGE. In order to build our dataset, we utilized the 'Genious' API, which allowed us to acquire the lyrics of songs and their explanations, as well as their rich metadata.