 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-Relational Programs: Unifying Queries and Neural Computation over Structured Data
Jun 10, 2026The conventional approach to deep learning over relational databases applies neural models, such as Graph Neural Networks (GNNs), to a graph representation of the database. Recent approaches instead operate on databases directly, associating tuples with embeddings and extending query mechanisms to jointly process embeddings and relational content. Inspired by these developments, we introduce Neuro-Relational Programs (NRPs), a declarative query language for relational databases whose facts carry numeric vector embeddings. NRPs extend Datalog-style rules with operations that combine, aggregate, and transform embeddings, thereby interleaving relational reasoning and learnable neural components within a single formalism. This yields a general approach to neural computation over relational data: an NRP can be read both as a query plan with trainable components and as a neural architecture with relational structure built in. Natural syntactic fragments of NRPs recover existing architectures and query formalisms. Zero-ary NRPs correspond to non-adaptive query algorithms; monadic NRPs generalize GNN-style message passing and precisely capture Deep Homomorphism Networks, a connection that we extend to frontier-guarded NRPs over databases with row-ids. We characterize the expressive power of unrestricted NRPs with ReLU-FFN transformations by FOCQ, an extension of first-order logic with counting interpreted over real-weighted structures, yielding a precise connection with uniform TC$^0$ over ordered databases. Together, these results establish NRPs as a broad declarative framework for querying and neural computation over relational data.
Incorporating Deep Learning Design in Database Queries
May 22, 2026Deep learning over relational databases is conventionally realized by translating data into graph representations and applying graph-based neural networks within external frameworks. This round-trip between the database and external machine learning (ML) systems introduces non-trivial engineering overhead. In effect, these graph neural networks operate on tuple embeddings and manipulate them in ways that capture the interactions induced by relational joins. Given this natural correspondence, there is no fundamental reason why specifying a neural network over relational data should be substantially harder than querying it. We propose an approach that naturally integrates deep learning with database queries. The key idea is to associate each tuple with provenance, represented as a vector embedding with learnable parameters. Queries are lifted to operate jointly on data and embeddings, mapping input relations with embedded tuples to output relations with embedded tuples. This approach provides a declarative foundation for relational deep learning, facilitating integration with database systems, optimization, and wide adoption. We describe RelaNN, a proof-of-concept implementation of this approach built on top of PyTorch and cuDF. We illustrate the utility of RelaNN by implementing various graph-learning models, including graph convolutional networks, heterogeneous graph transformers, hypergraph neural networks and deep homomorphism networks. The simplicity of the programs and their competitive runtime performance demonstrate a concrete path toward making the implementation of state-of-the-art neural networks over databases as simple as writing a query.
Database Views as Explanations for Relational Deep Learning
Sep 11, 2025In recent years, there has been significant progress in the development of deep learning models over relational databases, including architectures based on heterogeneous graph neural networks (hetero-GNNs) and heterogeneous graph transformers. In effect, such architectures state how the database records and links (e.g., foreign-key references) translate into a large, complex numerical expression, involving numerous learnable parameters. This complexity makes it hard to explain, in human-understandable terms, how a model uses the available data to arrive at a given prediction. We present a novel framework for explaining machine-learning models over relational databases, where explanations are view definitions that highlight focused parts of the database that mostly contribute to the model's prediction. We establish such global abductive explanations by adapting the classic notion of determinacy by Nash, Segoufin, and Vianu (2010). In addition to tuning the tradeoff between determinacy and conciseness, the framework allows controlling the level of granularity by adopting different fragments of view definitions, such as ones highlighting whole columns, foreign keys between tables, relevant groups of tuples, and so on. We investigate the realization of the framework in the case of hetero-GNNs. We develop heuristic algorithms that avoid the exhaustive search over the space of all databases. We propose techniques that are model-agnostic, and others that are tailored to hetero-GNNs via the notion of learnable masking. Our approach is evaluated through an extensive empirical study on the RelBench collection, covering a variety of domains and different record-level tasks. The results demonstrate the usefulness of the proposed explanations, as well as the efficiency of their generation.
SpannerLib: Embedding Declarative Information Extraction in an Imperative Workflow
Sep 03, 2024Document spanners have been proposed as a formal framework for declarative Information Extraction (IE) from text, following IE products from the industry and academia. Over the past decade, the framework has been studied thoroughly in terms of expressive power, complexity, and the ability to naturally combine text analysis with relational querying. This demonstration presents SpannerLib a library for embedding document spanners in Python code. SpannerLib facilitates the development of IE programs by providing an implementation of Spannerlog (Datalog-based documentspanners) that interacts with the Python code in two directions: rules can be embedded inside Python, and they can invoke custom Python code (e.g., calls to ML-based NLP models) via user-defined functions. The demonstration scenarios showcase IE programs, with increasing levels of complexity, within Jupyter Notebook.
A Dataset for Metaphor Detection in Early Medieval Hebrew Poetry
Feb 27, 2024
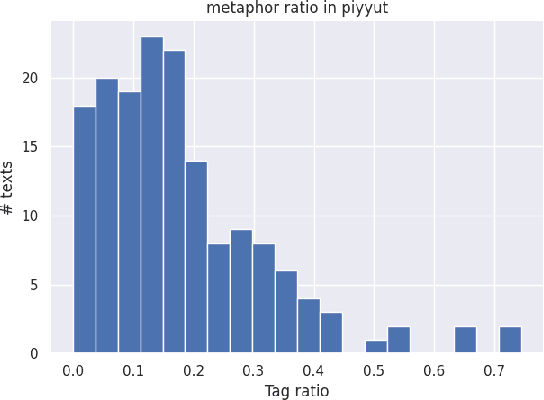
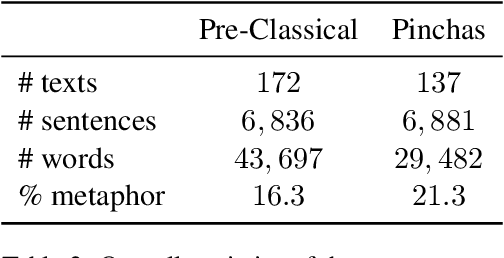
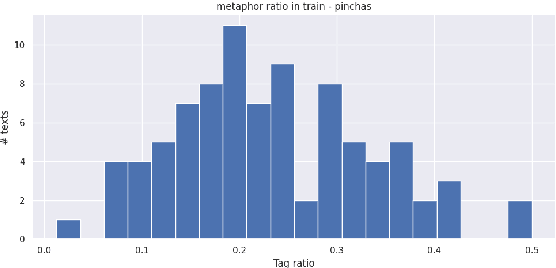
There is a large volume of late antique and medieval Hebrew texts. They represent a crucial linguistic and cultural bridge between Biblical and modern Hebrew. Poetry is prominent in these texts and one of its main haracteristics is the frequent use of metaphor. Distinguishing figurative and literal language use is a major task for scholars of the Humanities, especially in the fields of literature, linguistics, and hermeneutics. This paper presents a new, challenging dataset of late antique and medieval Hebrew poetry with expert annotations of metaphor, as well as some baseline results, which we hope will facilitate further research in this area.
Selecting Walk Schemes for Database Embedding
Jan 20, 2024



Machinery for data analysis often requires a numeric representation of the input. Towards that, a common practice is to embed components of structured data into a high-dimensional vector space. We study the embedding of the tuples of a relational database, where existing techniques are often based on optimization tasks over a collection of random walks from the database. The focus of this paper is on the recent FoRWaRD algorithm that is designed for dynamic databases, where walks are sampled by following foreign keys between tuples. Importantly, different walks have different schemas, or "walk schemes", that are derived by listing the relations and attributes along the walk. Also importantly, different walk schemes describe relationships of different natures in the database. We show that by focusing on a few informative walk schemes, we can obtain tuple embedding significantly faster, while retaining the quality. We define the problem of scheme selection for tuple embedding, devise several approaches and strategies for scheme selection, and conduct a thorough empirical study of the performance over a collection of downstream tasks. Our results confirm that with effective strategies for scheme selection, we can obtain high-quality embeddings considerably (e.g., three times) faster, preserve the extensibility to newly inserted tuples, and even achieve an increase in the precision of some tasks.
* Accepted by CIKM 2023, 10 pages
Accelerating the Global Aggregation of Local Explanations
Dec 23, 2023



Local explanation methods highlight the input tokens that have a considerable impact on the outcome of classifying the document at hand. For example, the Anchor algorithm applies a statistical analysis of the sensitivity of the classifier to changes in the token. Aggregating local explanations over a dataset provides a global explanation of the model. Such aggregation aims to detect words with the most impact, giving valuable insights about the model, like what it has learned in training and which adversarial examples expose its weaknesses. However, standard aggregation methods bear a high computational cost: a na\"ive implementation applies a costly algorithm to each token of each document, and hence, it is infeasible for a simple user running in the scope of a short analysis session. % We devise techniques for accelerating the global aggregation of the Anchor algorithm. Specifically, our goal is to compute a set of top-$k$ words with the highest global impact according to different aggregation functions. Some of our techniques are lossless and some are lossy. We show that for a very mild loss of quality, we are able to accelerate the computation by up to 30$\times$, reducing the computation from hours to minutes. We also devise and study a probabilistic model that accounts for noise in the Anchor algorithm and diminishes the bias toward words that are frequent yet low in impact.
Automatic Location Type Classification From Social-Media Posts
Feb 05, 2020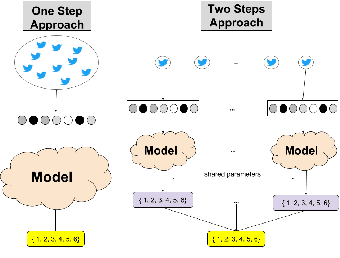
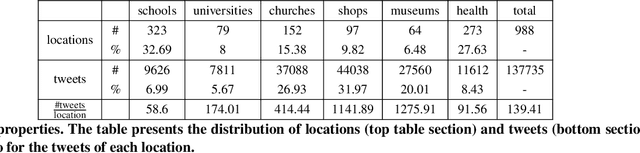

We introduce the problem of Automatic Location Type Classification from social media posts. Our goal is to correctly associate a set of messages posted in a small radius around a given location with their corresponding location type, e.g., school, church, restaurant or museum. We provide a dataset of locations associated with tweets posted in close geographical proximity. We explore two approaches to the problem: (a) a pipeline approach where each message is first classified, and then the location associated with the message set is inferred from the individual message labels; and (b) a joint approach where the individual messages are simultaneously processed to yield the desired location type. Our results demonstrate the superiority of the joint approach. Moreover, we show that due to the unique structure of the problem, where weakly-related messages are jointly processed to yield a single final label, simpler linear classifiers outperform deep neural network alternatives that have shown superior in previous text classification tasks.
Computational Social Choice Meets Databases
May 10, 2018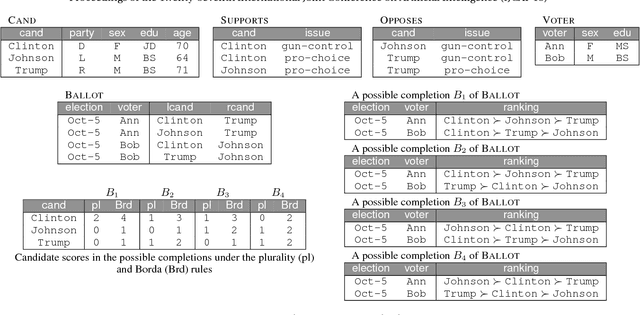
We develop a novel framework that aims to create bridges between the computational social choice and the database management communities. This framework enriches the tasks currently supported in computational social choice with relational database context, thus making it possible to formulate sophisticated queries about voting rules, candidates, voters, issues, and positions. At the conceptual level, we give rigorous semantics to queries in this framework by introducing the notions of necessary answers and possible answers to queries. At the technical level, we embark on an investigation of the computational complexity of the necessary answers. We establish a number of results about the complexity of the necessary answers of conjunctive queries involving positional scoring rules that contrast sharply with earlier results about the complexity of the necessary winners.
Declarative Statistical Modeling with Datalog
Jan 05, 2015

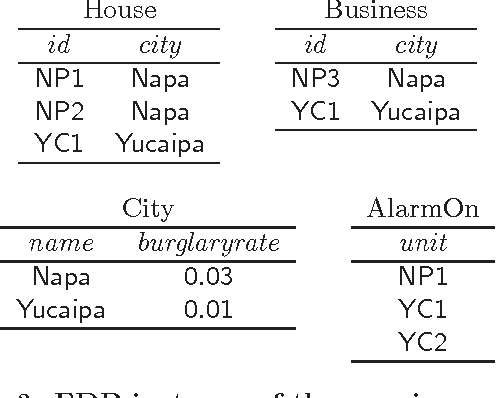
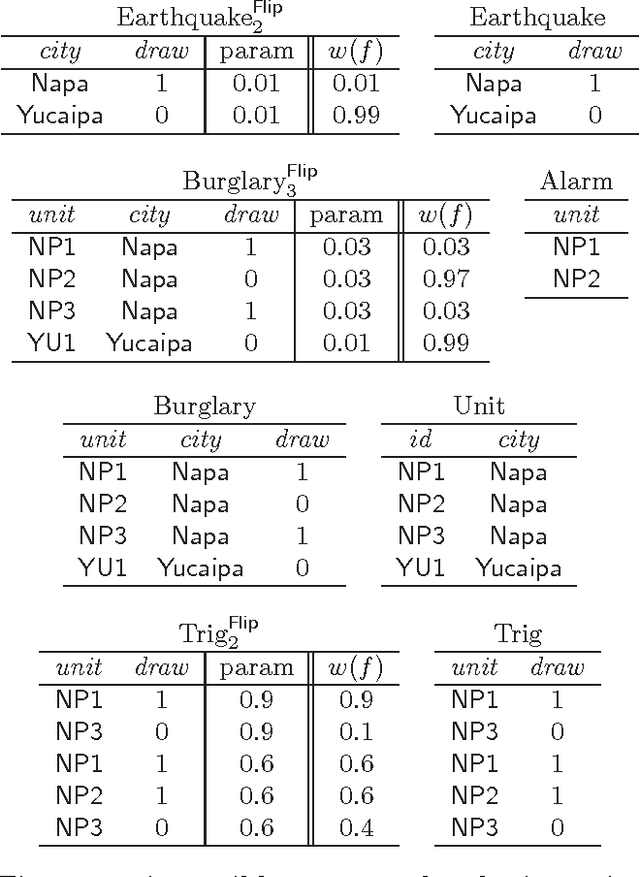
Formalisms for specifying statistical models, such as probabilistic-programming languages, typically consist of two components: a specification of a stochastic process (the prior), and a specification of observations that restrict the probability space to a conditional subspace (the posterior). Use cases of such formalisms include the development of algorithms in machine learning and artificial intelligence. We propose and investigate a declarative framework for specifying statistical models on top of a database, through an appropriate extension of Datalog. By virtue of extending Datalog, our framework offers a natural integration with the database, and has a robust declarative semantics. Our Datalog extension provides convenient mechanisms to include numerical probability functions; in particular, conclusions of rules may contain values drawn from such functions. The semantics of a program is a probability distribution over the possible outcomes of the input database with respect to the program; these outcomes are minimal solutions with respect to a related program with existentially quantified variables in conclusions. Observations are naturally incorporated by means of integrity constraints over the extensional and intensional relations. We focus on programs that use discrete numerical distributions, but even then the space of possible outcomes may be uncountable (as a solution can be infinite). We define a probability measure over possible outcomes by applying the known concept of cylinder sets to a probabilistic chase procedure. We show that the resulting semantics is robust under different chases. We also identify conditions guaranteeing that all possible outcomes are finite (and then the probability space is discrete). We argue that the framework we propose retains the purely declarative nature of Datalog, and allows for natural specifications of statistical models.