 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperdimensional computing for structured querying on tabular data embeddings
Jun 11, 2026Tabular data embeddings have become a cornerstone of data profiling and data integration pipelines, enabling tasks such as entity annotation and resolution; schema matching; column type detection; and table search, among others. Existing approaches embed rows, columns, or entire tables into a vector space and rely on nearest-neighbor search to retrieve candidate matches. A fundamental limitation of current embedding methods is the lack of interpretable similarity scores: the concrete similarity value between a query and its nearest neighbour carries no intrinsic meaning, making it impossible to determine whether that neighbour is a true match or simply the least-dissimilar item in a corpus that contains no valid answer. This inability to set principled thresholds for retrieval undermines practical deployment, particularly for zero-match detection. We investigate the use of HyperDimensional Computing (HDC), specifically the Holographic Reduced Representations (HRR) model, as a framework for tabular row embeddings when the retrieval task corresponds to answering structured select-project queries in vector space. Exploiting the algebraic properties of HDC operations, we derive closed-form expected similarity values for both equality and non-equality retrieval predicates, which converge to interpretable values as dimensionality increases, and use these to identify suitable retrieval thresholds. We evaluate HDC against EmbDI, a graph-based baseline, on two real-world datasets across varying table sizes and predicate lengths. Our results show that HDC matches or outperforms EmbDI for row retrieval across all configurations, handles non-equality predicates more robustly, and achieves perfect attribute projection accuracy at sufficient dimensionality -- while uniquely enabling reliable identification of zero-match predicates through its principled thresholds.
On Halting vs Converging in Recurrent Graph Neural Networks
Apr 28, 2026Recurrent Graph Neural Networks (RGNNs) extend standard GNNs by iterating message-passing until some stopping condition is met. Various RGNN models have been proposed in the literature. In this paper, we study three such models: converging RGNNs, where all vertex representations must stabilise; output-converging RGNNs, where only the output classifications must stabilise; and halting RGNNs, where a per-vertex halting classifier determines when to stop. We establish expressiveness relationships between these models: over undirected graphs, converging RGNNs are equally expressive as graded-bisimulation-invariant halting RGNNs, while output-converging RGNNs are at least as expressive. Combined with prior results on halting RGNNs, this shows that, relative to the classifiers expressible in monadic second-order logic (MSO), converging RGNNs express exactly the graded modal $μ$-calculus ($μ$GML), and output-converging RGNNs express at least $μ$GML. These results hold even when restricting to ReLU networks with sum aggregation. The main technical challenge is simulating halting RGNNs by converging ones: without a global halting classifier, vertices may locally decide to halt at different times, causing desynchronisation. We develop a "traffic-light" protocol that enables vertices to coordinate despite this asynchrony. Our results answer an open question from Bollen et al. (2025) and show that the RGNN model of Pflueger et al. (2024) retains full $μ$GML expressiveness even when convergence is guaranteed.
Halting Recurrent GNNs and the Graded $μ$-Calculus
May 16, 2025Graph Neural Networks (GNNs) are a class of machine-learning models that operate on graph-structured data. Their expressive power is intimately related to logics that are invariant under graded bisimilarity. Current proposals for recurrent GNNs either assume that the graph size is given to the model, or suffer from a lack of termination guarantees. In this paper, we propose a halting mechanism for recurrent GNNs. We prove that our halting model can express all node classifiers definable in graded modal mu-calculus, even for the standard GNN variant that is oblivious to the graph size. A recent breakthrough in the study of the expressivity of graded modal mu-calculus in the finite suggests that conversely, restricted to node classifiers definable in monadic second-order logic, recurrent GNNs can express only node classifiers definable in graded modal mu-calculus. To prove our main result, we develop a new approximate semantics for graded mu-calculus, which we believe to be of independent interest. We leverage this new semantics into a new model-checking algorithm, called the counting algorithm, which is oblivious to the graph size. In a final step we show that the counting algorithm can be implemented on a halting recurrent GNN.
SpannerLib: Embedding Declarative Information Extraction in an Imperative Workflow
Sep 03, 2024Document spanners have been proposed as a formal framework for declarative Information Extraction (IE) from text, following IE products from the industry and academia. Over the past decade, the framework has been studied thoroughly in terms of expressive power, complexity, and the ability to naturally combine text analysis with relational querying. This demonstration presents SpannerLib a library for embedding document spanners in Python code. SpannerLib facilitates the development of IE programs by providing an implementation of Spannerlog (Datalog-based documentspanners) that interacts with the Python code in two directions: rules can be embedded inside Python, and they can invoke custom Python code (e.g., calls to ML-based NLP models) via user-defined functions. The demonstration scenarios showcase IE programs, with increasing levels of complexity, within Jupyter Notebook.
Schema Matching with Large Language Models: an Experimental Study
Jul 16, 2024



Large Language Models (LLMs) have shown useful applications in a variety of tasks, including data wrangling. In this paper, we investigate the use of an off-the-shelf LLM for schema matching. Our objective is to identify semantic correspondences between elements of two relational schemas using only names and descriptions. Using a newly created benchmark from the health domain, we propose different so-called task scopes. These are methods for prompting the LLM to do schema matching, which vary in the amount of context information contained in the prompt. Using these task scopes we compare LLM-based schema matching against a string similarity baseline, investigating matching quality, verification effort, decisiveness, and complementarity of the approaches. We find that matching quality suffers from a lack of context information, but also from providing too much context information. In general, using newer LLM versions increases decisiveness. We identify task scopes that have acceptable verification effort and succeed in identifying a significant number of true semantic matches. Our study shows that LLMs have potential in bootstrapping the schema matching process and are able to assist data engineers in speeding up this task solely based on schema element names and descriptions without the need for data instances.
Learning Graph Neural Networks using Exact Compression
Apr 28, 2023
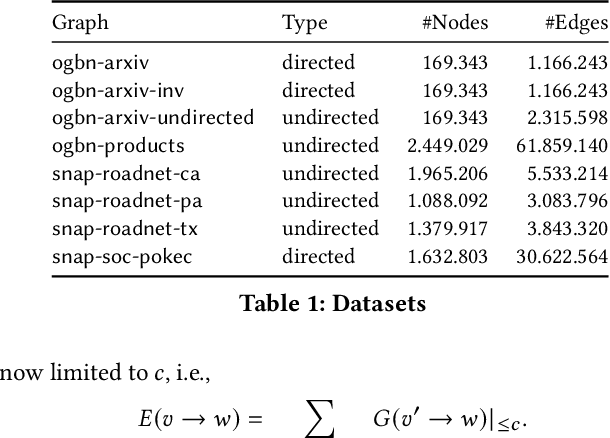
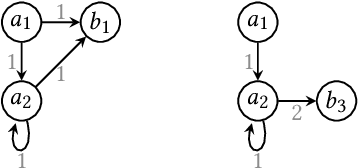
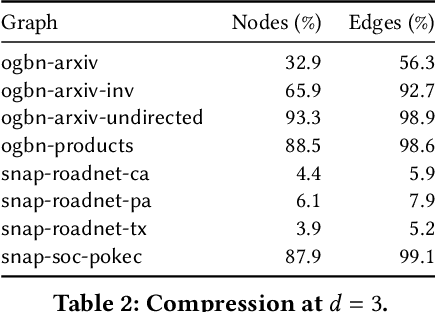
Graph Neural Networks (GNNs) are a form of deep learning that enable a wide range of machine learning applications on graph-structured data. The learning of GNNs, however, is known to pose challenges for memory-constrained devices such as GPUs. In this paper, we study exact compression as a way to reduce the memory requirements of learning GNNs on large graphs. In particular, we adopt a formal approach to compression and propose a methodology that transforms GNN learning problems into provably equivalent compressed GNN learning problems. In a preliminary experimental evaluation, we give insights into the compression ratios that can be obtained on real-world graphs and apply our methodology to an existing GNN benchmark.