 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Power and Limitations of Examples for Description Logic Concepts
Dec 23, 2024Labeled examples (i.e., positive and negative examples) are an attractive medium for communicating complex concepts. They are useful for deriving concept expressions (such as in concept learning, interactive concept specification, and concept refinement) as well as for illustrating concept expressions to a user or domain expert. We investigate the power of labeled examples for describing description-logic concepts. Specifically, we systematically study the existence and efficient computability of finite characterisations, i.e. finite sets of labeled examples that uniquely characterize a single concept, for a wide variety of description logics between EL and ALCQI, both without an ontology and in the presence of a DL-Lite ontology. Finite characterisations are relevant for debugging purposes, and their existence is a necessary condition for exact learnability with membership queries.
* Published in the Proceedings of the 33rd International Joint Conference on Artificial Intelligence (IJCAI)
SAT-Based PAC Learning of Description Logic Concepts
May 15, 2023



We propose bounded fitting as a scheme for learning description logic concepts in the presence of ontologies. A main advantage is that the resulting learning algorithms come with theoretical guarantees regarding their generalization to unseen examples in the sense of PAC learning. We prove that, in contrast, several other natural learning algorithms fail to provide such guarantees. As a further contribution, we present the system SPELL which efficiently implements bounded fitting for the description logic $\mathcal{ELH}^r$ based on a SAT solver, and compare its performance to a state-of-the-art learner.
On the non-efficient PAC learnability of acyclic conjunctive queries
Aug 22, 2022This note serves three purposes: (i) we provide a self-contained exposition of the fact that conjunctive queries are not efficiently learnable in the Probably-Approximately-Correct (PAC) model, paying clear attention to the complicating fact that this concept class lacks the polynomial-size fitting property, a property that is tacitly assumed in much of the computational learning theory literature; (ii) we establish a strong negative PAC learnability result that applies to many restricted classes of conjunctive queries (CQs), including acyclic CQs for a wide range of notions of "acyclicity"; (iii) we show that CQs are efficiently PAC learnable with membership queries.
Conjunctive Queries: Unique Characterizations and Exact Learnability
Aug 16, 2020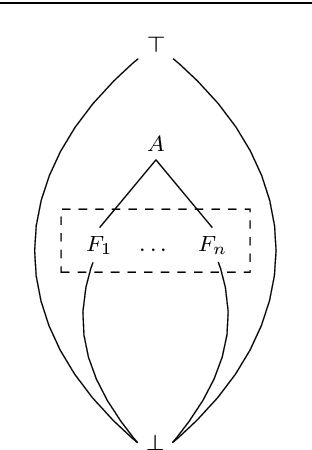



We answer the question which conjunctive queries are uniquely characterized by polynomially many positive and negative examples, and how to construct such examples efficiently. As a consequence, we obtain a new efficient exact learning algorithm for a class of conjunctive queries. At the core of our contributions lie two new polynomial-time algorithms for constructing frontiers in the homomorphism lattice of finite structures. We also discuss implications for the unique characterizability and learnability of schema mappings and of description logic concepts.
Learning Multilingual Word Embeddings Using Image-Text Data
May 29, 2019
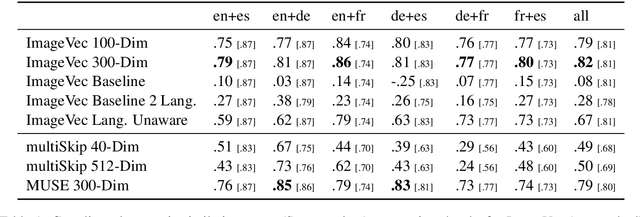
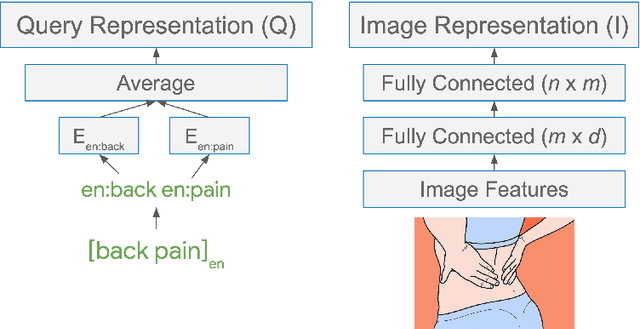
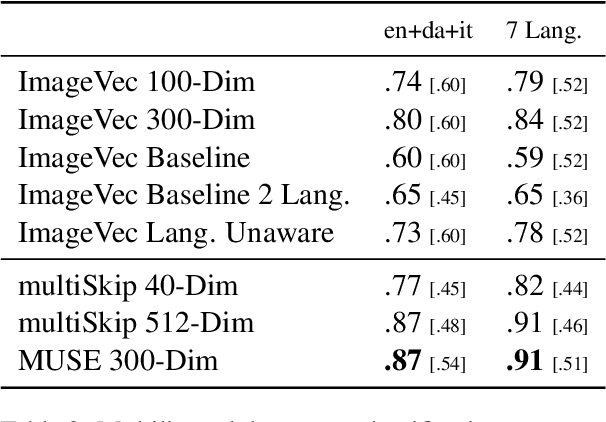
There has been significant interest recently in learning multilingual word embeddings -- in which semantically similar words across languages have similar embeddings. State-of-the-art approaches have relied on expensive labeled data, which is unavailable for low-resource languages, or have involved post-hoc unification of monolingual embeddings. In the present paper, we investigate the efficacy of multilingual embeddings learned from weakly-supervised image-text data. In particular, we propose methods for learning multilingual embeddings using image-text data, by enforcing similarity between the representations of the image and that of the text. Our experiments reveal that even without using any expensive labeled data, a bag-of-words-based embedding model trained on image-text data achieves performance comparable to the state-of-the-art on crosslingual semantic similarity tasks.
Declarative Statistical Modeling with Datalog
Jan 05, 2015

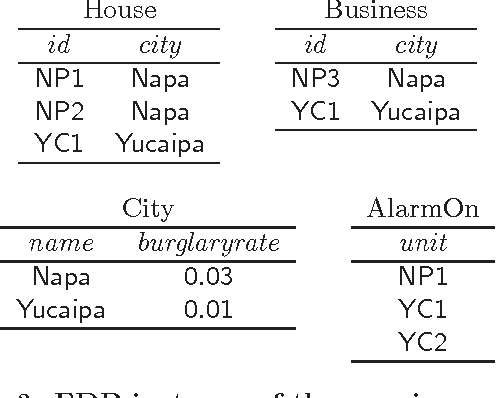
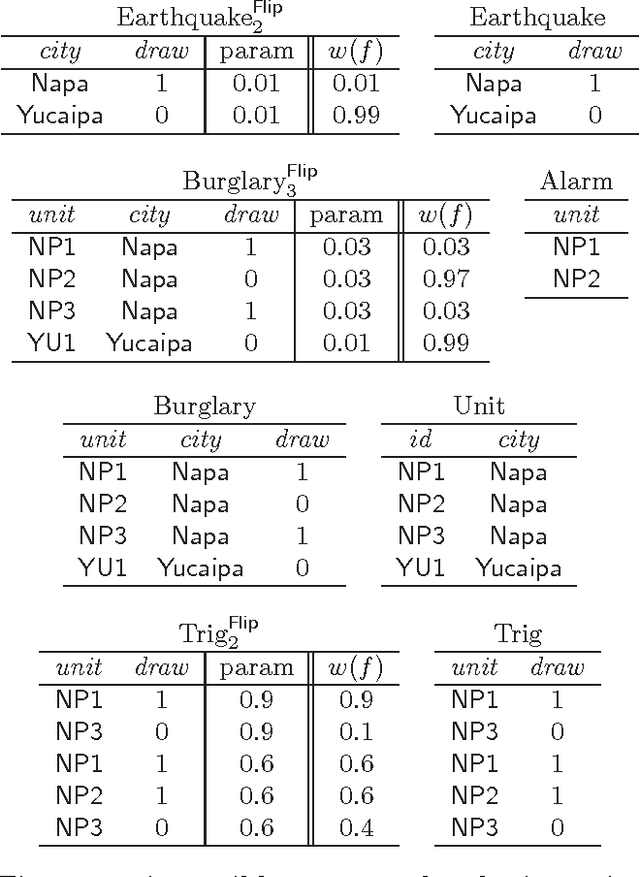
Formalisms for specifying statistical models, such as probabilistic-programming languages, typically consist of two components: a specification of a stochastic process (the prior), and a specification of observations that restrict the probability space to a conditional subspace (the posterior). Use cases of such formalisms include the development of algorithms in machine learning and artificial intelligence. We propose and investigate a declarative framework for specifying statistical models on top of a database, through an appropriate extension of Datalog. By virtue of extending Datalog, our framework offers a natural integration with the database, and has a robust declarative semantics. Our Datalog extension provides convenient mechanisms to include numerical probability functions; in particular, conclusions of rules may contain values drawn from such functions. The semantics of a program is a probability distribution over the possible outcomes of the input database with respect to the program; these outcomes are minimal solutions with respect to a related program with existentially quantified variables in conclusions. Observations are naturally incorporated by means of integrity constraints over the extensional and intensional relations. We focus on programs that use discrete numerical distributions, but even then the space of possible outcomes may be uncountable (as a solution can be infinite). We define a probability measure over possible outcomes by applying the known concept of cylinder sets to a probabilistic chase procedure. We show that the resulting semantics is robust under different chases. We also identify conditions guaranteeing that all possible outcomes are finite (and then the probability space is discrete). We argue that the framework we propose retains the purely declarative nature of Datalog, and allows for natural specifications of statistical models.
Ontology-based Data Access: A Study through Disjunctive Datalog, CSP, and MMSNP
Jun 06, 2013
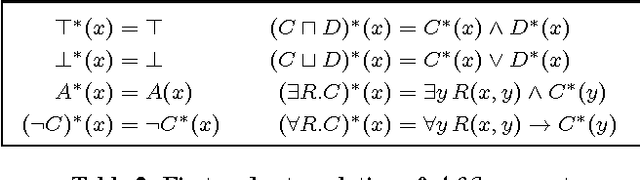
Ontology-based data access is concerned with querying incomplete data sources in the presence of domain-specific knowledge provided by an ontology. A central notion in this setting is that of an ontology-mediated query, which is a database query coupled with an ontology. In this paper, we study several classes of ontology-mediated queries, where the database queries are given as some form of conjunctive query and the ontologies are formulated in description logics or other relevant fragments of first-order logic, such as the guarded fragment and the unary-negation fragment. The contributions of the paper are three-fold. First, we characterize the expressive power of ontology-mediated queries in terms of fragments of disjunctive datalog. Second, we establish intimate connections between ontology-mediated queries and constraint satisfaction problems (CSPs) and their logical generalization, MMSNP formulas. Third, we exploit these connections to obtain new results regarding (i) first-order rewritability and datalog-rewritability of ontology-mediated queries, (ii) P/NP dichotomies for ontology-mediated queries, and (iii) the query containment problem for ontology-mediated queries.