 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Power and Ideology Identification in the Parliament: a Reference Dataset and Simple Baselines
May 12, 2024We introduce a dataset on political orientation and power position identification. The dataset is derived from ParlaMint, a set of comparable corpora of transcribed parliamentary speeches from 29 national and regional parliaments. We introduce the dataset, provide the reasoning behind some of the choices during its creation, present statistics on the dataset, and, using a simple classifier, some baseline results on predicting political orientation on the left-to-right axis, and on power position identification, i.e., distinguishing between the speeches delivered by governing coalition party members from those of opposition party members.
Dealing with Abbreviations in the Slovenian Biographical Lexicon
Nov 04, 2022Abbreviations present a significant challenge for NLP systems because they cause tokenization and out-of-vocabulary errors. They can also make the text less readable, especially in reference printed books, where they are extensively used. Abbreviations are especially problematic in low-resource settings, where systems are less robust to begin with. In this paper, we propose a new method for addressing the problems caused by a high density of domain-specific abbreviations in a text. We apply this method to the case of a Slovenian biographical lexicon and evaluate it on a newly developed gold-standard dataset of 51 Slovenian biographies. Our abbreviation identification method performs significantly better than commonly used ad-hoc solutions, especially at identifying unseen abbreviations. We also propose and present the results of a method for expanding the identified abbreviations in context.
MULTEXT-East
Mar 31, 2020

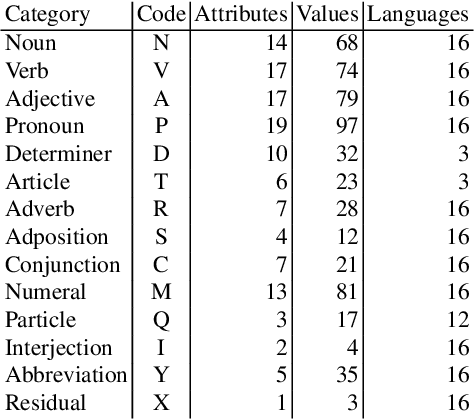

MULTEXT-East language resources, a multilingual dataset for language engineering research, focused on the morphosyntactic level of linguistic description. The MULTEXT-East dataset includes the EAGLES-based morphosyntactic specifications, morphosyntactic lexicons, and an annotated multilingual corpora. The parallel corpus, the novel "1984" by George Orwell, is sentence aligned and contains hand-validated morphosyntactic descriptions and lemmas. The resources are uniformly encoded in XML, using the Text Encoding Initiative Guidelines, TEI P5, and cover 16 languages: Bulgarian, Croatian, Czech, English, Estonian, Hungarian, Macedonian, Persian, Polish, Resian, Romanian, Russian, Serbian, Slovak, Slovene, and Ukrainian. This dataset is extensively documented, and freely available for research purposes. This case study gives a history of the development of the MULTEXT-East resources, presents their encoding and components, discusses related work and gives some conclusions.
The FRENK Datasets of Socially Unacceptable Discourse in Slovene and English
Jun 13, 2019



In this paper we present datasets of Facebook comment threads to mainstream media posts in Slovene and English developed inside the Slovene national project FRENK which cover two topics, migrants and LGBT, and are manually annotated for different types of socially unacceptable discourse (SUD). The main advantages of these datasets compared to the existing ones are identical sampling procedures, producing comparable data across languages and an annotation schema that takes into account six types of SUD and five targets at which SUD is directed. We describe the sampling and annotation procedures, and analyze the annotation distributions and inter-annotator agreements. We consider this dataset to be an important milestone in understanding and combating SUD for both languages.
KAS-term: Extracting Slovene Terms from Doctoral Theses via Supervised Machine Learning
Jun 05, 2019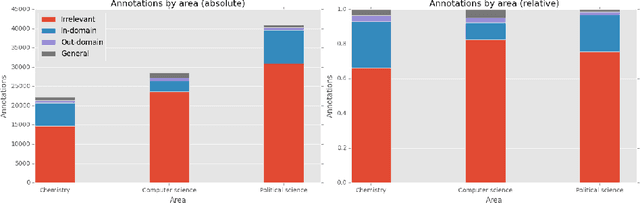
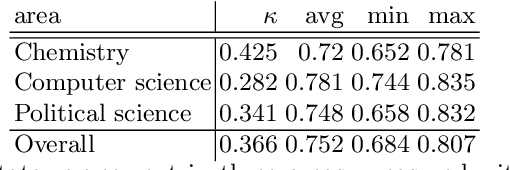
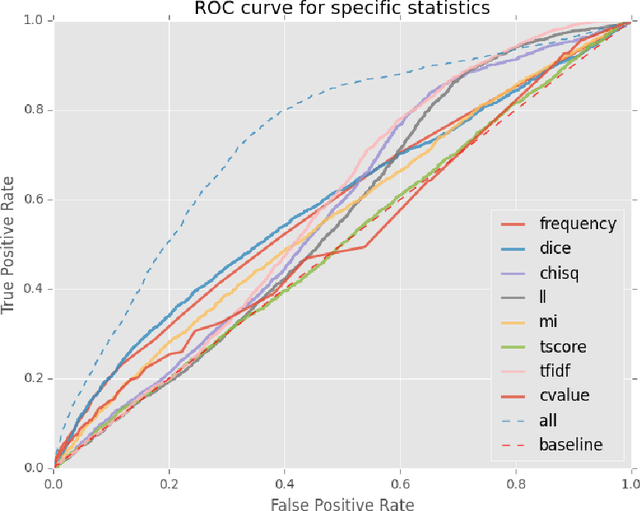
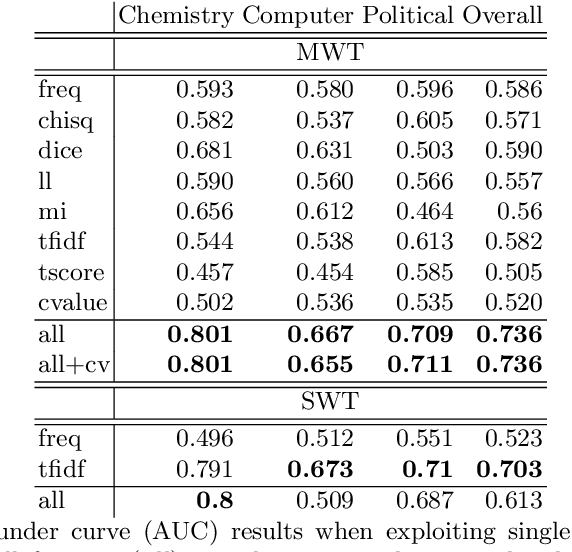
This paper presents a dataset and supervised learning experiments for term extraction from Slovene academic texts. Term candidates in the dataset were extracted via morphosyntactic patterns and annotated for their termness by four annotators. Experiments on the dataset show that most co-occurrence statistics, applied after morphosyntactic patterns and a frequency threshold, perform close to random and that the results can be significantly improved by combining, with supervised machine learning, all the seven statistic measures included in the dataset. On multi-word terms the model using all statistics obtains an AUC of 0.736 while the best single statistic produces only AUC 0.590. Among many additional candidate features, only adding multi-word morphosyntactic pattern information and length of the single-word term candidates achieves further improvements of the results.
Overview of Annotation Creation: Processes & Tools
Feb 18, 2016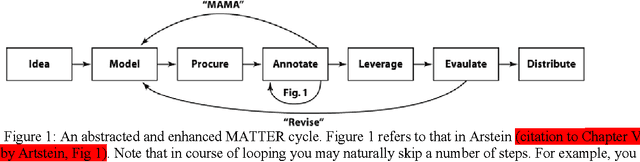
Creating linguistic annotations requires more than just a reliable annotation scheme. Annotation can be a complex endeavour potentially involving many people, stages, and tools. This chapter outlines the process of creating end-to-end linguistic annotations, identifying specific tasks that researchers often perform. Because tool support is so central to achieving high quality, reusable annotations with low cost, the focus is on identifying capabilities that are necessary or useful for annotation tools, as well as common problems these tools present that reduce their utility. Although examples of specific tools are provided in many cases, this chapter concentrates more on abstract capabilities and problems because new tools appear continuously, while old tools disappear into disuse or disrepair. The two core capabilities tools must have are support for the chosen annotation scheme and the ability to work on the language under study. Additional capabilities are organized into three categories: those that are widely provided; those that often useful but found in only a few tools; and those that have as yet little or no available tool support.