 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKAS-term: Extracting Slovene Terms from Doctoral Theses via Supervised Machine Learning
Paper and Code
Jun 05, 2019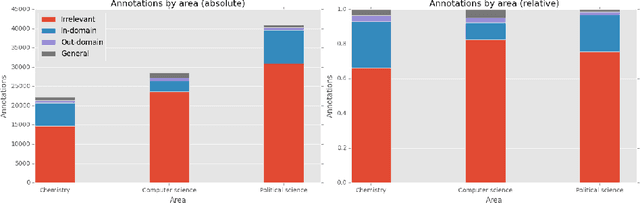
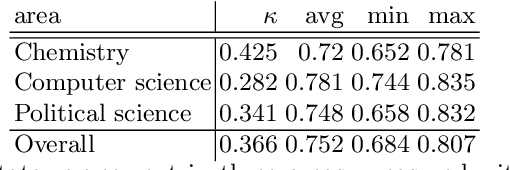
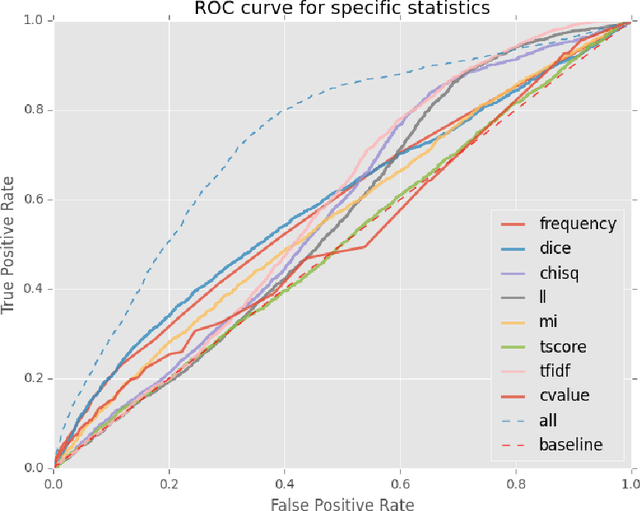
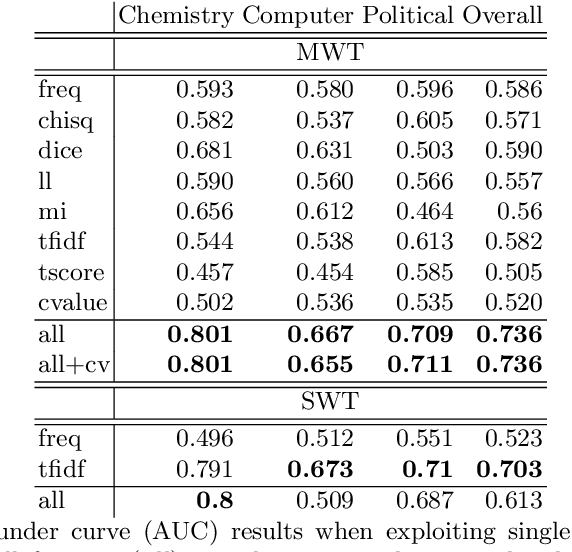
This paper presents a dataset and supervised learning experiments for term extraction from Slovene academic texts. Term candidates in the dataset were extracted via morphosyntactic patterns and annotated for their termness by four annotators. Experiments on the dataset show that most co-occurrence statistics, applied after morphosyntactic patterns and a frequency threshold, perform close to random and that the results can be significantly improved by combining, with supervised machine learning, all the seven statistic measures included in the dataset. On multi-word terms the model using all statistics obtains an AUC of 0.736 while the best single statistic produces only AUC 0.590. Among many additional candidate features, only adding multi-word morphosyntactic pattern information and length of the single-word term candidates achieves further improvements of the results.