 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Neural Argumentative Stance Classification in Controversial Topics with Emotion-Lexicon Features
Feb 26, 2026Argumentation mining comprises several subtasks, among which stance classification focuses on identifying the standpoint expressed in an argumentative text toward a specific target topic. While arguments-especially about controversial topics-often appeal to emotions, most prior work has not systematically incorporated explicit, fine-grained emotion analysis to improve performance on this task. In particular, prior research on stance classification has predominantly utilized non-argumentative texts and has been restricted to specific domains or topics, limiting generalizability. We work on five datasets from diverse domains encompassing a range of controversial topics and present an approach for expanding the Bias-Corrected NRC Emotion Lexicon using DistilBERT embeddings, which we feed into a Neural Argumentative Stance Classification model. Our method systematically expands the emotion lexicon through contextualized embeddings to identify emotionally charged terms not previously captured in the lexicon. Our expanded NRC lexicon (eNRC) improves over the baseline across all five datasets (up to +6.2 percentage points in F1 score), outperforms the original NRC on four datasets (up to +3.0), and surpasses the LLM-based approach on nearly all corpora. We provide all resources-including eNRC, the adapted corpora, and model architecture-to enable other researchers to build upon our work.
Automated Neural Patent Landscaping in the Small Data Regime
Jul 10, 2024
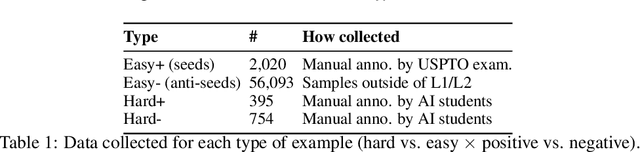


Patent landscaping is the process of identifying all patents related to a particular technological area, and is important for assessing various aspects of the intellectual property context. Traditionally, constructing patent landscapes is intensely laborious and expensive, and the rapid expansion of patenting activity in recent decades has driven an increasing need for efficient and effective automated patent landscaping approaches. In particular, it is critical that we be able to construct patent landscapes using a minimal number of labeled examples, as labeling patents for a narrow technology area requires highly specialized (and hence expensive) technical knowledge. We present an automated neural patent landscaping system that demonstrates significantly improved performance on difficult examples (0.69 $F_1$ on 'hard' examples, versus 0.6 for previously reported systems), and also significant improvements with much less training data (overall 0.75 $F_1$ on as few as 24 examples). Furthermore, in evaluating such automated landscaping systems, acquiring good data is challenge; we demonstrate a higher-quality training data generation procedure by merging Abood and Feltenberger's (2018) "seed/anti-seed" approach with active learning to collect difficult labeled examples near the decision boundary. Using this procedure we created a new dataset of labeled AI patents for training and testing. As in prior work we compare our approach with a number of baseline systems, and we release our code and data for others to build upon.
Finding Trolls Under Bridges: Preliminary Work on a Motif Detector
Apr 12, 2022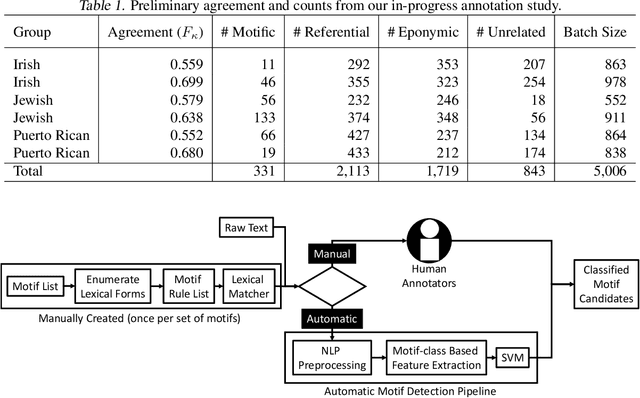

Motifs are distinctive recurring elements found in folklore that have significance as communicative devices in news, literature, press releases, and propaganda. Motifs concisely imply a large constellation of culturally-relevant information, and their broad usage suggests their cognitive importance as touchstones of cultural knowledge, making their detection a worthy step toward culturally-aware natural language processing tasks. Until now, folklorists and others interested in motifs have only extracted motifs from narratives manually. We present a preliminary report on the development of a system for automatically detecting motifs. We briefly describe an annotation effort to produce data for training motif detection, which is on-going. We describe our in-progress architecture in detail, which aims to capture, in part, how people determine whether or not a motif candidate is being used in a motific way. This description includes a test of an off-the-shelf metaphor detector as a feature for motif detection, which achieves a F1 of 0.35 on motifs and a macro-average F1 of 0.21 across four categories which we assign to motif candidates.
The ABBE Corpus: Animate Beings Being Emotional
Jan 25, 2022


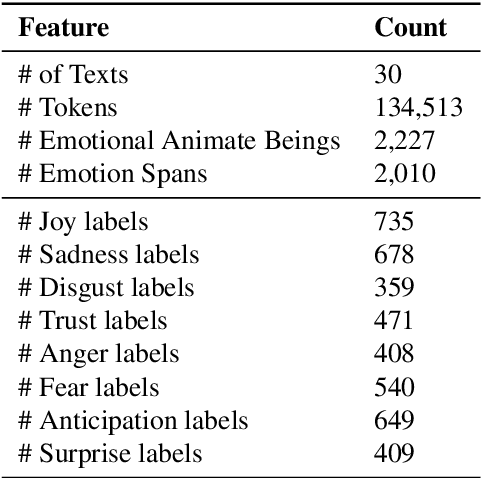
Emotion detection is an established NLP task of demonstrated utility for text understanding. However, basic emotion detection leaves out key information, namely, who is experiencing the emotion in question. For example, it may be the author, the narrator, or a character; or the emotion may correspond to something the audience is supposed to feel, or even be unattributable to a specific being, e.g., when emotions are being discussed per se. We provide the ABBE corpus -- Animate Beings Being Emotional -- a new double-annotated corpus of texts that captures this key information for one class of emotion experiencer, namely, animate beings in the world described by the text. Such a corpus is useful for developing systems that seek to model or understand this specific type of expressed emotion. Our corpus contains 30 chapters, comprising 134,513 words, drawn from the Corpus of English Novels, and contains 2,010 unique emotion expressions attributable to 2,227 animate beings. The emotion expressions are categorized according to Plutchik's 8-category emotion model, and the overall inter-annotator agreement for the annotations was 0.83 Cohen's Kappa, indicating excellent agreement. We describe in detail our annotation scheme and procedure, and also release the corpus for use by other researchers.
Overview of Annotation Creation: Processes & Tools
Feb 18, 2016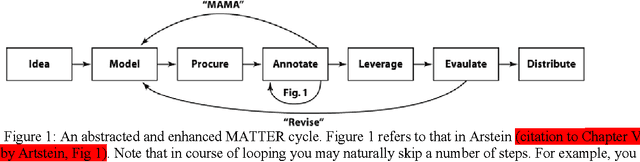
Creating linguistic annotations requires more than just a reliable annotation scheme. Annotation can be a complex endeavour potentially involving many people, stages, and tools. This chapter outlines the process of creating end-to-end linguistic annotations, identifying specific tasks that researchers often perform. Because tool support is so central to achieving high quality, reusable annotations with low cost, the focus is on identifying capabilities that are necessary or useful for annotation tools, as well as common problems these tools present that reduce their utility. Although examples of specific tools are provided in many cases, this chapter concentrates more on abstract capabilities and problems because new tools appear continuously, while old tools disappear into disuse or disrepair. The two core capabilities tools must have are support for the chosen annotation scheme and the ability to work on the language under study. Additional capabilities are organized into three categories: those that are widely provided; those that often useful but found in only a few tools; and those that have as yet little or no available tool support.