 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretation of Intracardiac Electrograms Through Textual Representations
Feb 02, 2024



Understanding the irregular electrical activity of atrial fibrillation (AFib) has been a key challenge in electrocardiography. For serious cases of AFib, catheter ablations are performed to collect intracardiac electrograms (EGMs). EGMs offer intricately detailed and localized electrical activity of the heart and are an ideal modality for interpretable cardiac studies. Recent advancements in artificial intelligence (AI) has allowed some works to utilize deep learning frameworks to interpret EGMs during AFib. Additionally, language models (LMs) have shown exceptional performance in being able to generalize to unseen domains, especially in healthcare. In this study, we are the first to leverage pretrained LMs for finetuning of EGM interpolation and AFib classification via masked language modeling. We formulate the EGM as a textual sequence and present competitive performances on AFib classification compared against other representations. Lastly, we provide a comprehensive interpretability study to provide a multi-perspective intuition of the model's behavior, which could greatly benefit the clinical use.
Finding Trolls Under Bridges: Preliminary Work on a Motif Detector
Apr 12, 2022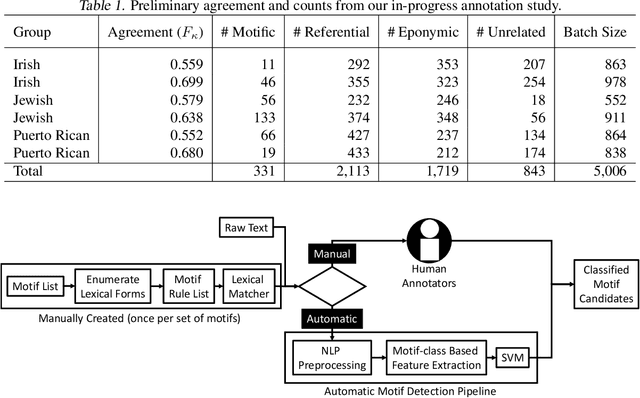

Motifs are distinctive recurring elements found in folklore that have significance as communicative devices in news, literature, press releases, and propaganda. Motifs concisely imply a large constellation of culturally-relevant information, and their broad usage suggests their cognitive importance as touchstones of cultural knowledge, making their detection a worthy step toward culturally-aware natural language processing tasks. Until now, folklorists and others interested in motifs have only extracted motifs from narratives manually. We present a preliminary report on the development of a system for automatically detecting motifs. We briefly describe an annotation effort to produce data for training motif detection, which is on-going. We describe our in-progress architecture in detail, which aims to capture, in part, how people determine whether or not a motif candidate is being used in a motific way. This description includes a test of an off-the-shelf metaphor detector as a feature for motif detection, which achieves a F1 of 0.35 on motifs and a macro-average F1 of 0.21 across four categories which we assign to motif candidates.