 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-SRL: A Parallel Cross-Lingual Semantic Role Labeling Dataset
Paper and Code
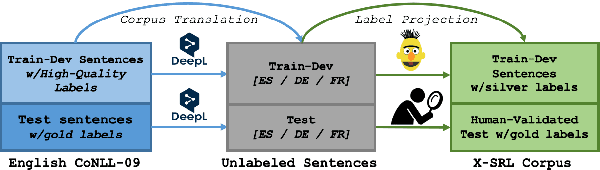

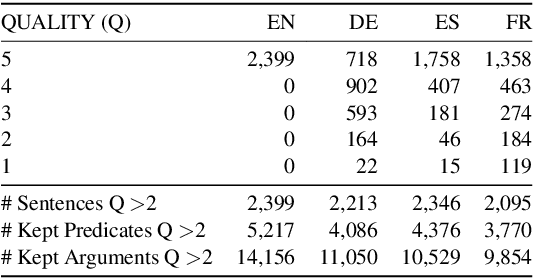
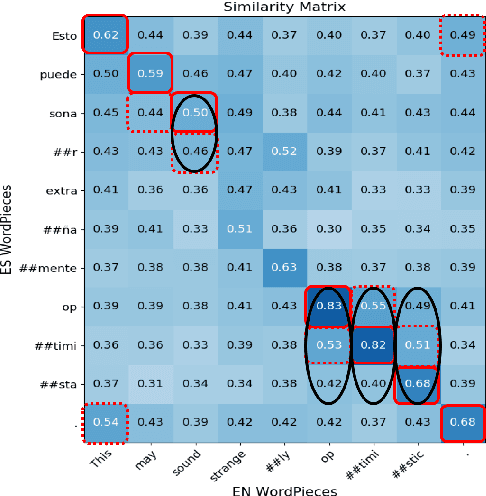
Even though SRL is researched for many languages, major improvements have mostly been obtained for English, for which more resources are available. In fact, existing multilingual SRL datasets contain disparate annotation styles or come from different domains, hampering generalization in multilingual learning. In this work, we propose a method to automatically construct an SRL corpus that is parallel in four languages: English, French, German, Spanish, with unified predicate and role annotations that are fully comparable across languages. We apply high-quality machine translation to the English CoNLL-09 dataset and use multilingual BERT to project its high-quality annotations to the target languages. We include human-validated test sets that we use to measure the projection quality, and show that projection is denser and more precise than a strong baseline. Finally, we train different SOTA models on our novel corpus for mono- and multilingual SRL, showing that the multilingual annotations improve performance especially for the weaker languages.