 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming the Generalization Limits of SLM Finetuning for Shape-Based Extraction of Datatype and Object Properties
Nov 05, 2025Small language models (SLMs) have shown promises for relation extraction (RE) when extracting RDF triples guided by SHACL shapes focused on common datatype properties. This paper investigates how SLMs handle both datatype and object properties for a complete RDF graph extraction. We show that the key bottleneck is related to long-tail distribution of rare properties. To solve this issue, we evaluate several strategies: stratified sampling, weighted loss, dataset scaling, and template-based synthetic data augmentation. We show that the best strategy to perform equally well over unbalanced target properties is to build a training set where the number of occurrences of each property exceeds a given threshold. To enable reproducibility, we publicly released our datasets, experimental results and code. Our findings offer practical guidance for training shape-aware SLMs and highlight promising directions for future work in semantic RE.
Project SHADOW: Symbolic Higher-order Associative Deductive reasoning On Wikidata using LM probing
Aug 27, 2024We introduce SHADOW, a fine-tuned language model trained on an intermediate task using associative deductive reasoning, and measure its performance on a knowledge base construction task using Wikidata triple completion. We evaluate SHADOW on the LM-KBC 2024 challenge and show that it outperforms the baseline solution by 20% with a F1 score of 68.72%.
DSTI at LLMs4OL 2024 Task A: Intrinsic versus extrinsic knowledge for type classification
Aug 26, 2024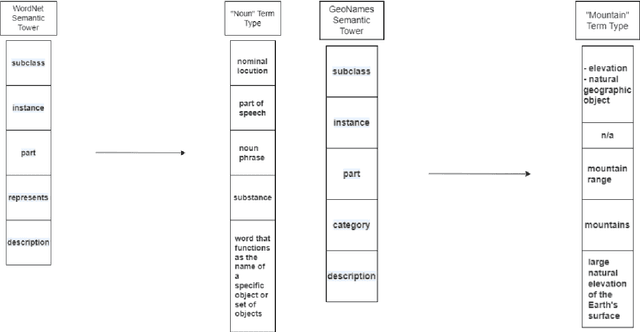



We introduce semantic towers, an extrinsic knowledge representation method, and compare it to intrinsic knowledge in large language models for ontology learning. Our experiments show a trade-off between performance and semantic grounding for extrinsic knowledge compared to a fine-tuned model intrinsic knowledge. We report our findings on the Large Language Models for Ontology Learning (LLMs4OL) 2024 challenge.
NeSy is alive and well: A LLM-driven symbolic approach for better code comment data generation and classification
Feb 25, 2024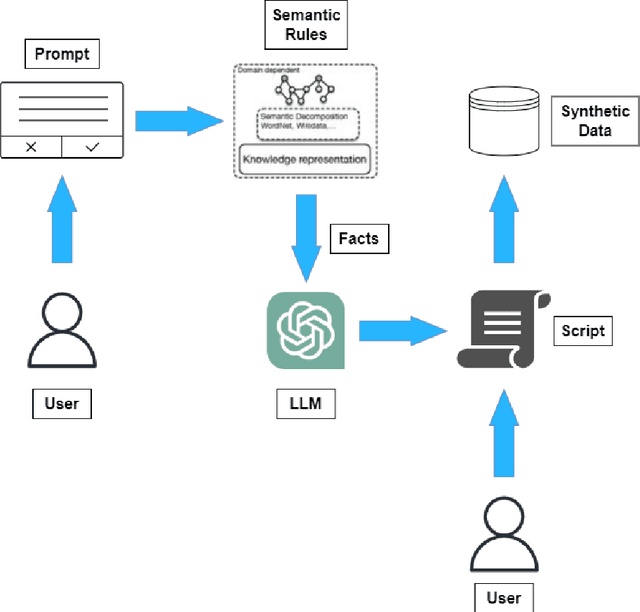
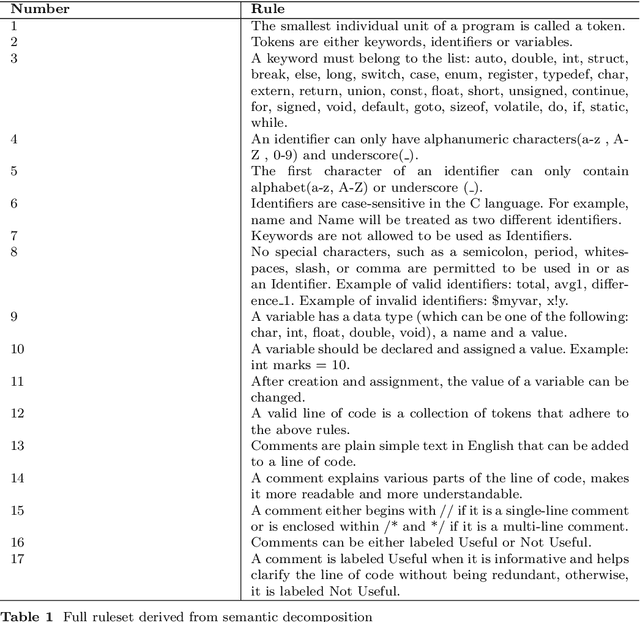
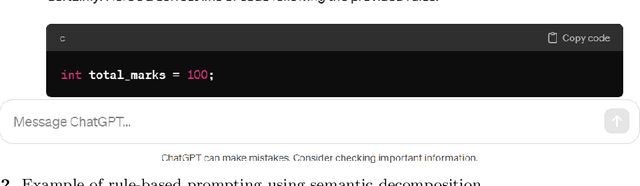

We present a neuro-symbolic (NeSy) workflow combining a symbolic-based learning technique with a large language model (LLM) agent to generate synthetic data for code comment classification in the C programming language. We also show how generating controlled synthetic data using this workflow fixes some of the notable weaknesses of LLM-based generation and increases the performance of classical machine learning models on the code comment classification task. Our best model, a Neural Network, achieves a Macro-F1 score of 91.412% with an increase of 1.033% after data augmentation.
PSYCHIC: A Neuro-Symbolic Framework for Knowledge Graph Question-Answering Grounding
Oct 19, 2023The Scholarly Question Answering over Linked Data (Scholarly QALD) at The International Semantic Web Conference (ISWC) 2023 challenge presents two sub-tasks to tackle question answering (QA) over knowledge graphs (KGs). We answer the KGQA over DBLP (DBLP-QUAD) task by proposing a neuro-symbolic (NS) framework based on PSYCHIC, an extractive QA model capable of identifying the query and entities related to a KG question. Our system achieved a F1 score of 00.18% on question answering and came in third place for entity linking (EL) with a score of 71.00%.
A ML-LLM pairing for better code comment classification
Oct 13, 2023The "Information Retrieval in Software Engineering (IRSE)" at FIRE 2023 shared task introduces code comment classification, a challenging task that pairs a code snippet with a comment that should be evaluated as either useful or not useful to the understanding of the relevant code. We answer the code comment classification shared task challenge by providing a two-fold evaluation: from an algorithmic perspective, we compare the performance of classical machine learning systems and complement our evaluations from a data-driven perspective by generating additional data with the help of large language model (LLM) prompting to measure the potential increase in performance. Our best model, which took second place in the shared task, is a Neural Network with a Macro-F1 score of 88.401% on the provided seed data and a 1.5% overall increase in performance on the data generated by the LLM.
* 10 pages, 2 figures, 2 tables, accepted for the Information Retrieval in Software Engineering track at the Forum for Information Retrieval Evaluation 2023
The Path to Autonomous Learners
Nov 04, 2022



In this paper, we present a new theoretical approach for enabling domain knowledge acquisition by intelligent systems. We introduce a hybrid model that starts with minimal input knowledge in the form of an upper ontology of concepts, stores and reasons over this knowledge through a knowledge graph database and learns new information through a Logic Neural Network. We study the behavior of this architecture when handling new data and show that the final system is capable of enriching its current knowledge as well as extending it to new domains.
Yseop at FinSim-3 Shared Task 2021: Specializing Financial Domain Learning with Phrase Representations
Aug 21, 2021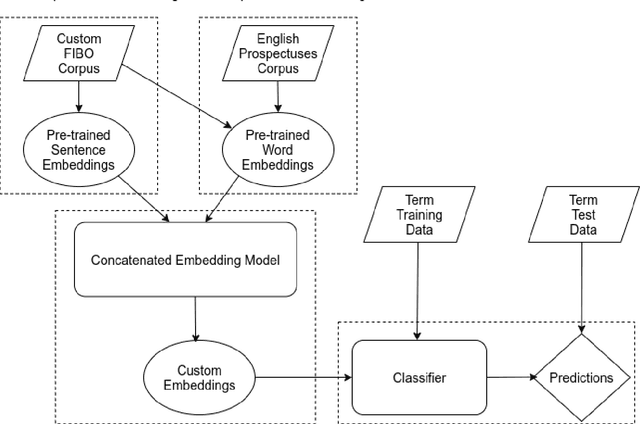

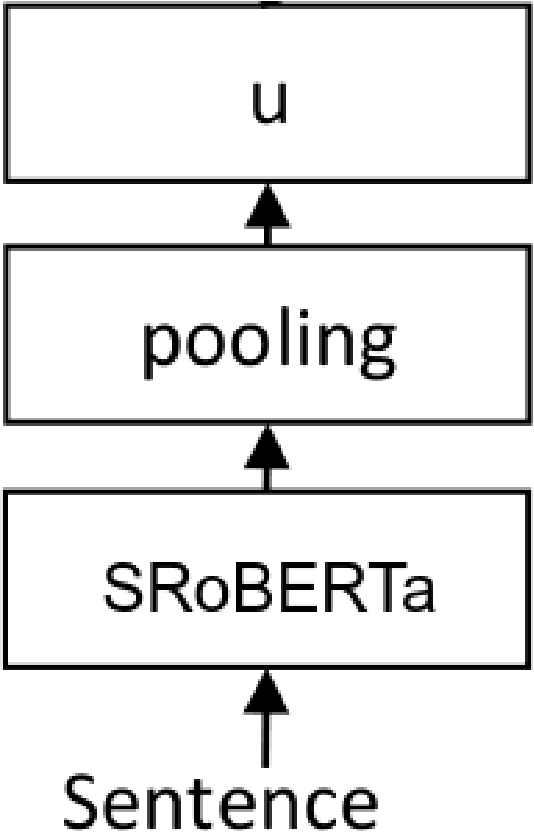

In this paper, we present our approaches for the FinSim-3 Shared Task 2021: Learning Semantic Similarities for the Financial Domain. The aim of this shared task is to correctly classify a list of given terms from the financial domain into the most relevant hypernym (or top-level) concept in an external ontology. For our system submission, we evaluate two methods: a Sentence-RoBERTa (SRoBERTa) embeddings model pre-trained on a custom corpus, and a dual word-sentence embeddings model that builds on the first method by improving the proposed baseline word embeddings construction using the FastText model to boost the classification performance. Our system ranks 2nd overall on both metrics, scoring 0.917 on Average Accuracy and 1.141 on Mean Rank.
Financial Document Causality Detection Shared Task (FinCausal 2020)
Dec 04, 2020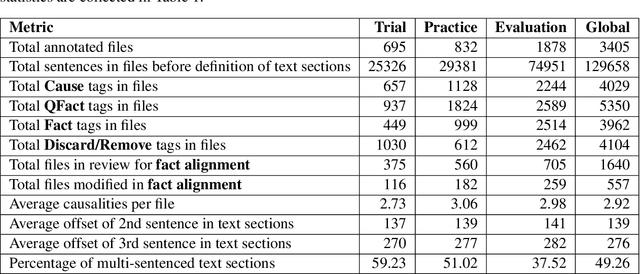



We present the FinCausal 2020 Shared Task on Causality Detection in Financial Documents and the associated FinCausal dataset, and discuss the participating systems and results. Two sub-tasks are proposed: a binary classification task (Task 1) and a relation extraction task (Task 2). A total of 16 teams submitted runs across the two Tasks and 13 of them contributed with a system description paper. This workshop is associated to the Joint Workshop on Financial Narrative Processing and MultiLing Financial Summarisation (FNP-FNS 2020), held at The 28th International Conference on Computational Linguistics (COLING'2020), Barcelona, Spain on September 12, 2020.
Data Processing and Annotation Schemes for FinCausal Shared Task
Dec 04, 2020
This document explains the annotation schemes used to label the data for the FinCausal Shared Task (Mariko et al., 2020). This task is associated to the Joint Workshop on Financial Narrative Processing and MultiLing Financial Summarisation (FNP-FNS 2020), to be held at The 28th International Conference on Computational Linguistics (COLING'2020), on December 12, 2020.