 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYseop at FinSim-3 Shared Task 2021: Specializing Financial Domain Learning with Phrase Representations
Paper and Code
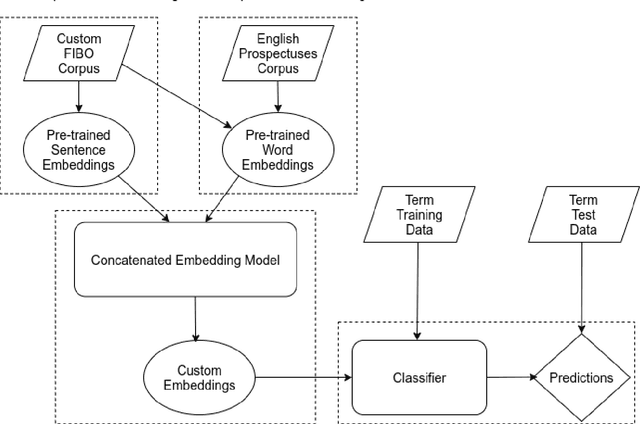

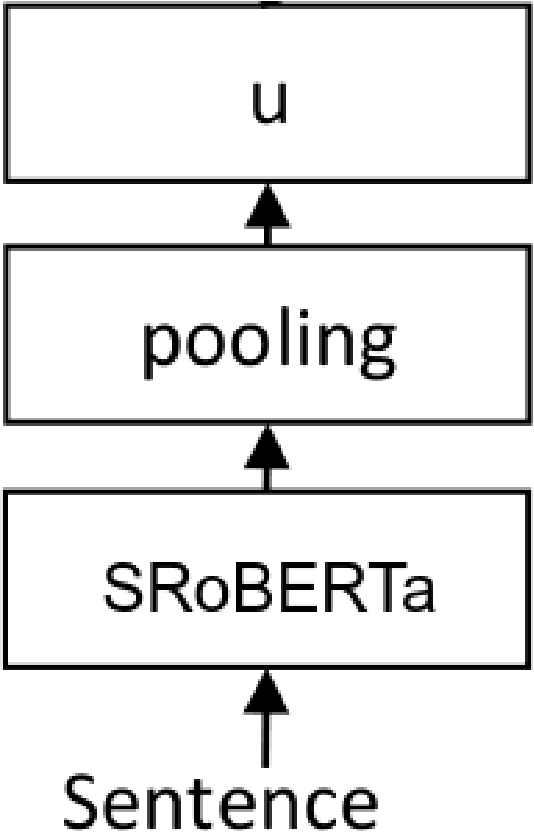

In this paper, we present our approaches for the FinSim-3 Shared Task 2021: Learning Semantic Similarities for the Financial Domain. The aim of this shared task is to correctly classify a list of given terms from the financial domain into the most relevant hypernym (or top-level) concept in an external ontology. For our system submission, we evaluate two methods: a Sentence-RoBERTa (SRoBERTa) embeddings model pre-trained on a custom corpus, and a dual word-sentence embeddings model that builds on the first method by improving the proposed baseline word embeddings construction using the FastText model to boost the classification performance. Our system ranks 2nd overall on both metrics, scoring 0.917 on Average Accuracy and 1.141 on Mean Rank.