 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefining Admissible Rewards for High Confidence Policy Evaluation
Paper and Code
May 30, 2019

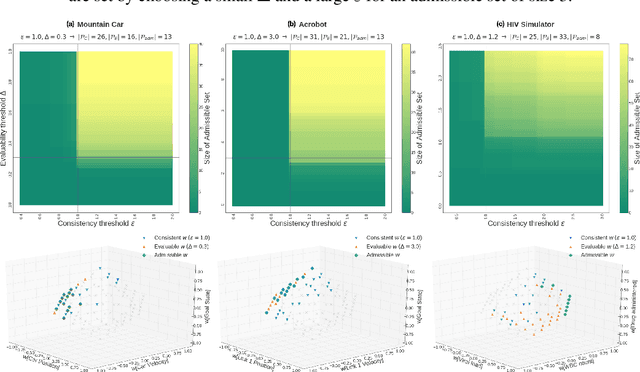

A key impediment to reinforcement learning (RL) in real applications with limited, batch data is defining a reward function that reflects what we implicitly know about reasonable behaviour for a task and allows for robust off-policy evaluation. In this work, we develop a method to identify an admissible set of reward functions for policies that (a) do not diverge too far from past behaviour, and (b) can be evaluated with high confidence, given only a collection of past trajectories. Together, these ensure that we propose policies that we trust to be implemented in high-risk settings. We demonstrate our approach to reward design on synthetic domains as well as in a critical care context, for a reward that consolidates clinical objectives to learn a policy for weaning patients from mechanical ventilation.