 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Quantized Autoencoders
Paper and Code

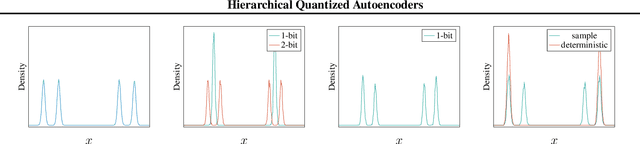
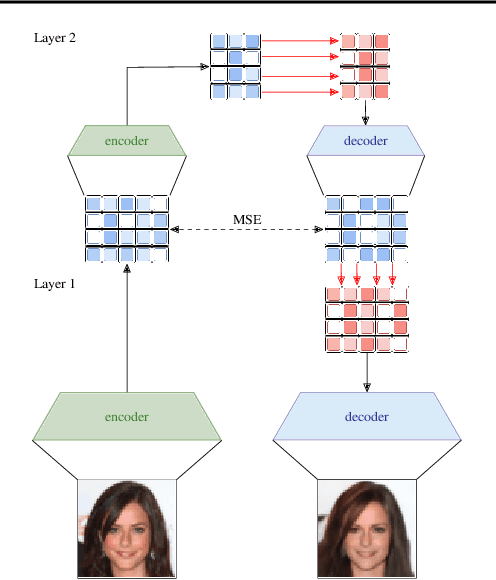
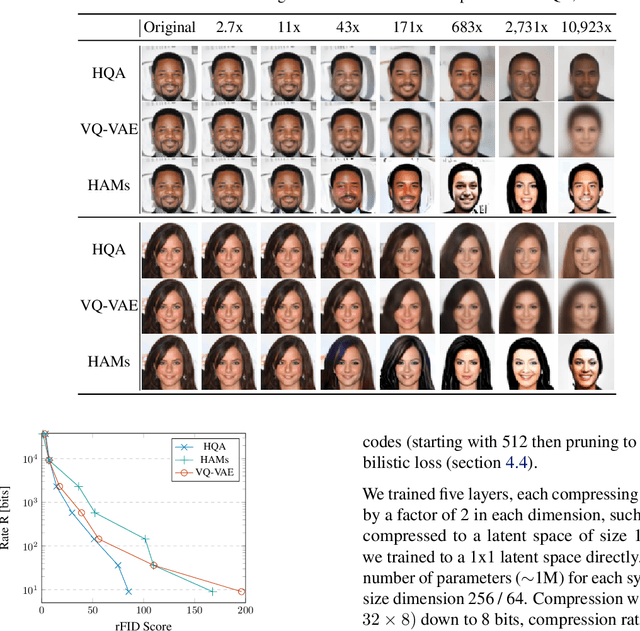
Despite progress in training neural networks for lossy image compression, current approaches fail to maintain both perceptual quality and high-level features at very low bitrates. Encouraged by recent success in learning discrete representations with Vector Quantized Variational AutoEncoders (VQ-VAEs), we motivate the use of a hierarchy of VQ-VAEs to attain high factors of compression. We show that the combination of quantization and hierarchical latent structure aids likelihood-based image compression. This leads us to introduce a more probabilistic framing of the VQ-VAE, of which previous work is a limiting case. Our hierarchy produces a Markovian series of latent variables that reconstruct high-quality images which retain semantically meaningful features. These latents can then be further used to generate realistic samples. We provide qualitative and quantitative evaluations of reconstructions and samples on the CelebA and MNIST datasets.