 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTa'keed: The First Generative Fact-Checking System for Arabic Claims
Jan 25, 2024This paper introduces Ta'keed, an explainable Arabic automatic fact-checking system. While existing research often focuses on classifying claims as "True" or "False," there is a limited exploration of generating explanations for claim credibility, particularly in Arabic. Ta'keed addresses this gap by assessing claim truthfulness based on retrieved snippets, utilizing two main components: information retrieval and LLM-based claim verification. We compiled the ArFactEx, a testing gold-labelled dataset with manually justified references, to evaluate the system. The initial model achieved a promising F1 score of 0.72 in the classification task. Meanwhile, the system's generated explanations are compared with gold-standard explanations syntactically and semantically. The study recommends evaluating using semantic similarities, resulting in an average cosine similarity score of 0.76. Additionally, we explored the impact of varying snippet quantities on claim classification accuracy, revealing a potential correlation, with the model using the top seven hits outperforming others with an F1 score of 0.77.
* 9 pages, conference paper
Multi-Level Analysis and Annotation of Arabic Corpora for Text-to-Sign Language MT
May 24, 2016

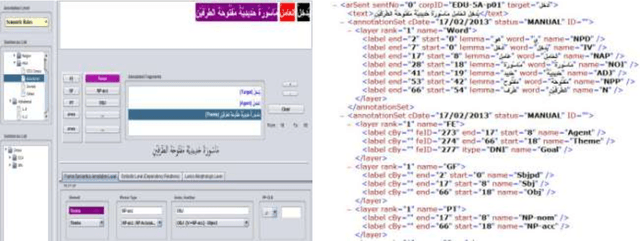
In this paper, we present an ongoing effort in lexical semantic analysis and annotation of Modern Standard Arabic (MSA) text, a semi automatic annotation tool concerned with the morphologic, syntactic, and semantic levels of description.
A Comparative Study of Machine Learning Methods for Verbal Autopsy Text Classification
Feb 18, 2014
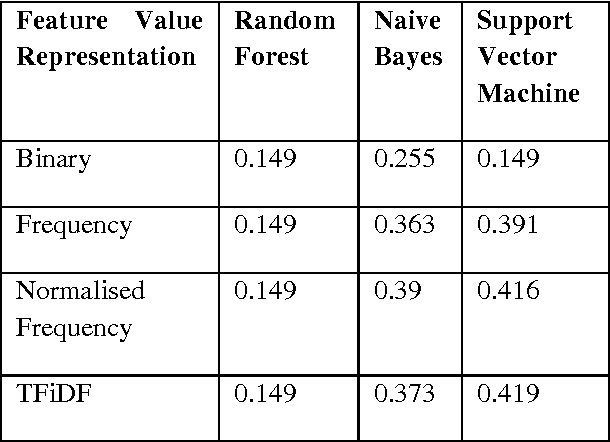
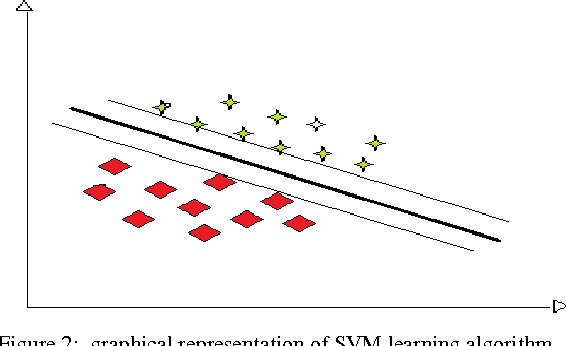
A Verbal Autopsy is the record of an interview about the circumstances of an uncertified death. In developing countries, if a death occurs away from health facilities, a field-worker interviews a relative of the deceased about the circumstances of the death; this Verbal Autopsy can be reviewed off-site. We report on a comparative study of the processes involved in Text Classification applied to classifying Cause of Death: feature value representation; machine learning classification algorithms; and feature reduction strategies in order to identify the suitable approaches applicable to the classification of Verbal Autopsy text. We demonstrate that normalised term frequency and the standard TFiDF achieve comparable performance across a number of classifiers. The results also show Support Vector Machine is superior to other classification algorithms employed in this research. Finally, we demonstrate the effectiveness of employing a "locally-semi-supervised" feature reduction strategy in order to increase performance accuracy.
* 10 pages
Automatic Extraction of Tagset Mappings from Parallel-Annotated Corpora
Jun 08, 1995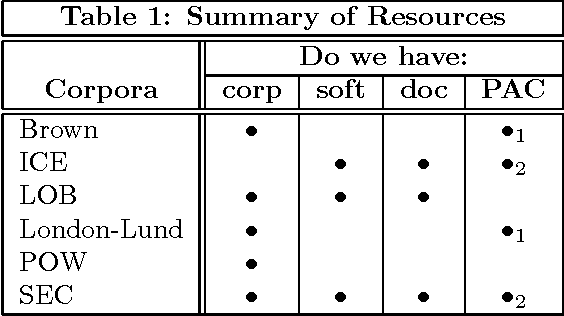
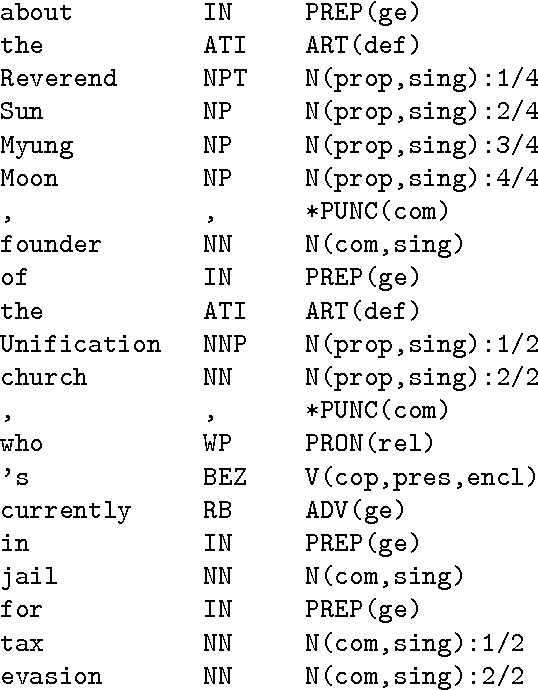
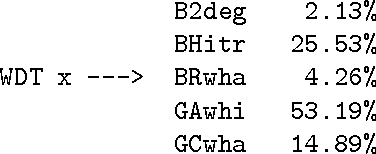
This paper describes some of the recent work of project AMALGAM (automatic mapping among lexico-grammatical annotation models). We are investigating ways to map between the leading corpus annotation schemes in order to improve their resuability. Collation of all the included corpora into a single large annotated corpus will provide a more detailed language model to be developed for tasks such as speech and handwriting recognition. In particular, we focus here on a method of extracting mappings from corpora that have been annotated according to more than one annotation scheme.