Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Extraction of Tagset Mappings from Parallel-Annotated Corpora
Jun 08, 1995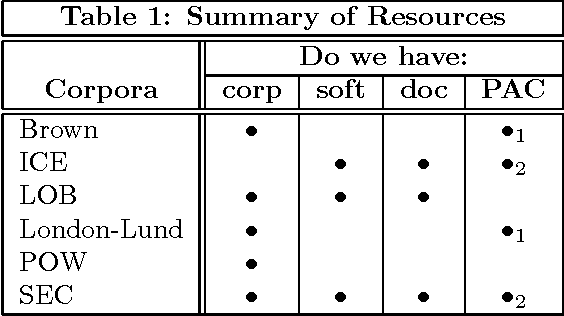
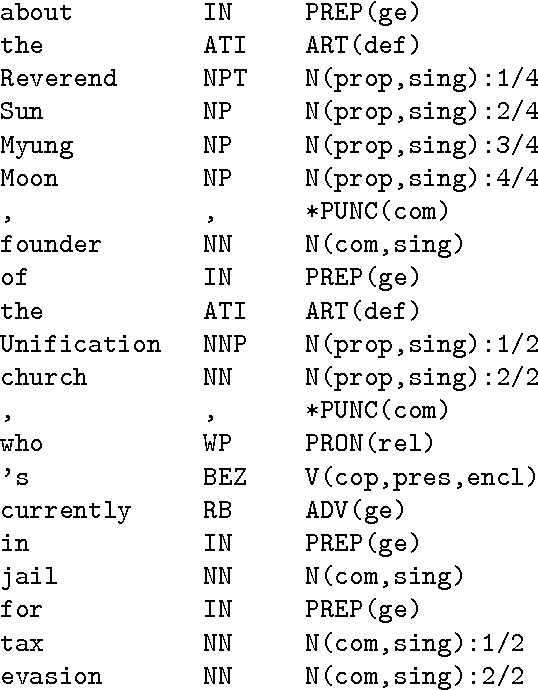
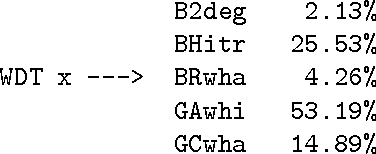
This paper describes some of the recent work of project AMALGAM (automatic mapping among lexico-grammatical annotation models). We are investigating ways to map between the leading corpus annotation schemes in order to improve their resuability. Collation of all the included corpora into a single large annotated corpus will provide a more detailed language model to be developed for tasks such as speech and handwriting recognition. In particular, we focus here on a method of extracting mappings from corpora that have been annotated according to more than one annotation scheme.
* 8 pages, LaTeX, uses EACL95 style file: aclap.sty
Via