 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerturbed examples reveal invariances shared by language models
Paper and Code
Nov 07, 2023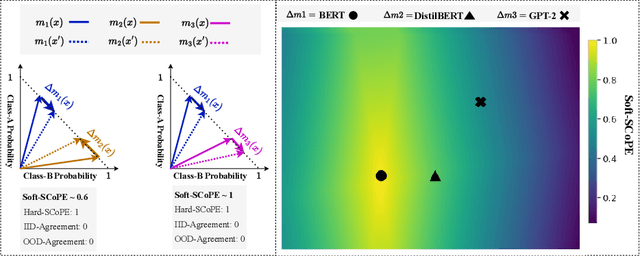
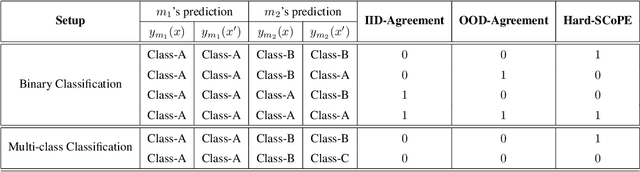
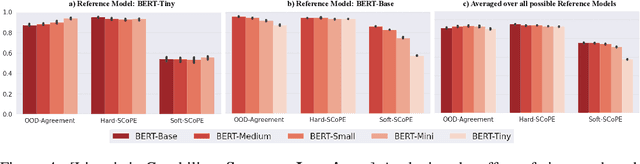
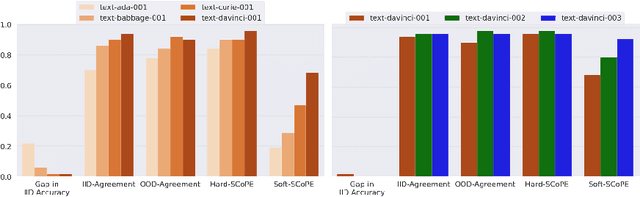
An explosion of work in language is leading to ever-increasing numbers of available natural language processing models, with little understanding of how new models compare to better-understood models. One major reason for this difficulty is saturating benchmark datasets, which may not reflect well differences in model performance in the wild. In this work, we propose a novel framework for comparing two natural language processing models by revealing their shared invariance to interpretable input perturbations that are designed to target a specific linguistic capability (e.g., Synonym-Invariance, Typo-Invariance). Via experiments on models from within the same and across different architecture families, this framework offers a number of insights about how changes in models (e.g., distillation, increase in size, amount of pre-training) affect multiple well-defined linguistic capabilities. Furthermore, we also demonstrate how our framework can enable evaluation of the invariances shared between models that are available as commercial black-box APIs (e.g., InstructGPT family) and models that are relatively better understood (e.g., GPT-2). Across several experiments, we observe that large language models share many of the invariances encoded by models of various sizes, whereas the invariances encoded by large language models are only shared by other large models. Possessing a wide variety of invariances may be a key reason for the recent successes of large language models, and our framework can shed light on the types of invariances that are retained by or emerge in new models.