 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMD3: Language Model Data Density Dependence
May 10, 2024



We develop a methodology for analyzing language model task performance at the individual example level based on training data density estimation. Experiments with paraphrasing as a controlled intervention on finetuning data demonstrate that increasing the support in the training distribution for specific test queries results in a measurable increase in density, which is also a significant predictor of the performance increase caused by the intervention. Experiments with pretraining data demonstrate that we can explain a significant fraction of the variance in model perplexity via density measurements. We conclude that our framework can provide statistical evidence of the dependence of a target model's predictions on subsets of its training data, and can more generally be used to characterize the support (or lack thereof) in the training data for a given test task.
Model-Based Bayesian Exploration
Jan 23, 2013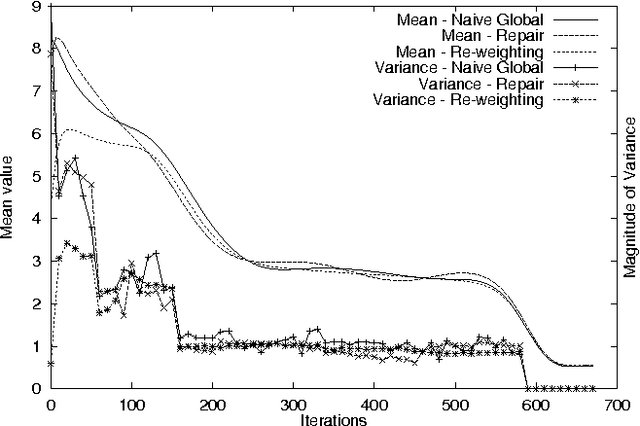
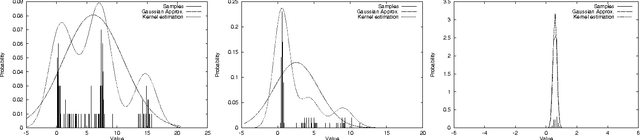
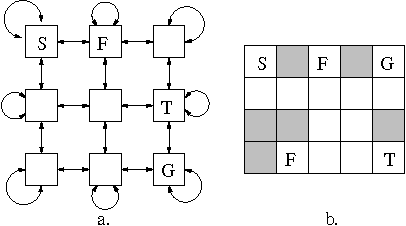
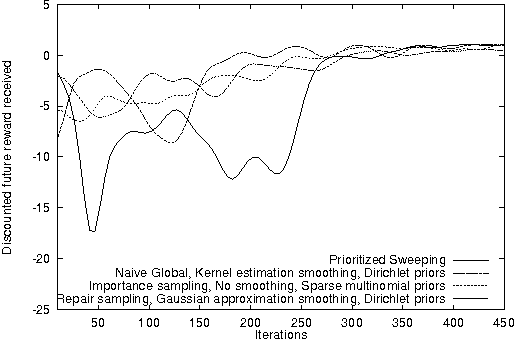
Reinforcement learning systems are often concerned with balancing exploration of untested actions against exploitation of actions that are known to be good. The benefit of exploration can be estimated using the classical notion of Value of Information - the expected improvement in future decision quality arising from the information acquired by exploration. Estimating this quantity requires an assessment of the agent's uncertainty about its current value estimates for states. In this paper we investigate ways of representing and reasoning about this uncertainty in algorithms where the system attempts to learn a model of its environment. We explicitly represent uncertainty about the parameters of the model and build probability distributions over Q-values based on these. These distributions are used to compute a myopic approximation to the value of information for each action and hence to select the action that best balances exploration and exploitation.
A compact, hierarchical Q-function decomposition
Jun 27, 2012
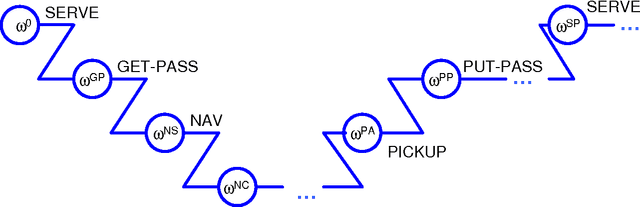
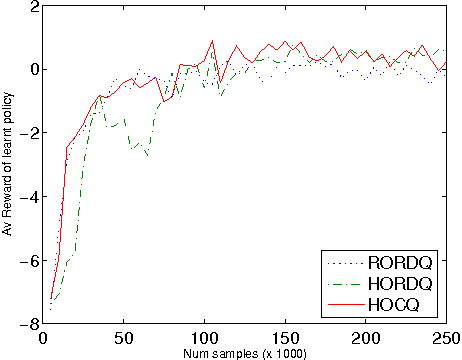
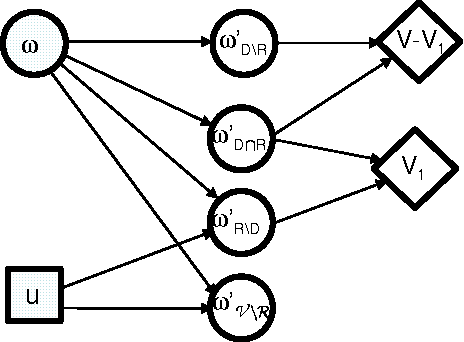
Previous work in hierarchical reinforcement learning has faced a dilemma: either ignore the values of different possible exit states from a subroutine, thereby risking suboptimal behavior, or represent those values explicitly thereby incurring a possibly large representation cost because exit values refer to nonlocal aspects of the world (i.e., all subsequent rewards). This paper shows that, in many cases, one can avoid both of these problems. The solution is based on recursively decomposing the exit value function in terms of Q-functions at higher levels of the hierarchy. This leads to an intuitively appealing runtime architecture in which a parent subroutine passes to its child a value function on the exit states and the child reasons about how its choices affect the exit value. We also identify structural conditions on the value function and transition distributions that allow much more concise representations of exit state distributions, leading to further state abstraction. In essence, the only variables whose exit values need be considered are those that the parent cares about and the child affects. We demonstrate the utility of our algorithms on a series of increasingly complex environments.