 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProceedings of the Eighteenth Conference on Uncertainty in Artificial Intelligence (2002)
Aug 28, 2014This is the Proceedings of the Eighteenth Conference on Uncertainty in Artificial Intelligence, which was held in Alberta, Canada, August 1-4 2002
Plausibility Measures: A User's Guide
Feb 20, 2013We examine a new approach to modeling uncertainty based on plausibility measures, where a plausibility measure just associates with an event its plausibility, an element is some partially ordered set. This approach is easily seen to generalize other approaches to modeling uncertainty, such as probability measures, belief functions, and possibility measures. The lack of structure in a plausibility measure makes it easy for us to add structure on an "as needed" basis, letting us examine what is required to ensure that a plausibility measure has certain properties of interest. This gives us insight into the essential features of the properties in question, while allowing us to prove general results that apply to many approaches to reasoning about uncertainty. Plausibility measures have already proved useful in analyzing default reasoning. In this paper, we examine their "algebraic properties," analogues to the use of + and * in probability theory. An understanding of such properties will be essential if plausibility measures are to be used in practice as a representation tool.
On the Sample Complexity of Learning Bayesian Networks
Feb 13, 2013
In recent years there has been an increasing interest in learning Bayesian networks from data. One of the most effective methods for learning such networks is based on the minimum description length (MDL) principle. Previous work has shown that this learning procedure is asymptotically successful: with probability one, it will converge to the target distribution, given a sufficient number of samples. However, the rate of this convergence has been hitherto unknown. In this work we examine the sample complexity of MDL based learning procedures for Bayesian networks. We show that the number of samples needed to learn an epsilon-close approximation (in terms of entropy distance) with confidence delta is O((1/epsilon)^(4/3)log(1/epsilon)log(1/delta)loglog (1/delta)). This means that the sample complexity is a low-order polynomial in the error threshold and sub-linear in the confidence bound. We also discuss how the constants in this term depend on the complexity of the target distribution. Finally, we address questions of asymptotic minimality and propose a method for using the sample complexity results to speed up the learning process.
A Qualitative Markov Assumption and its Implications for Belief Change
Feb 13, 2013The study of belief change has been an active area in philosophy and AI. In recent years two special cases of belief change, belief revision and belief update, have been studied in detail. Roughly, revision treats a surprising observation as a sign that previous beliefs were wrong, while update treats a surprising observation as an indication that the world has changed. In general, we would expect that an agent making an observation may both want to revise some earlier beliefs and assume that some change has occurred in the world. We define a novel approach to belief change that allows us to do this, by applying ideas from probability theory in a qualitative setting. The key idea is to use a qualitative Markov assumption, which says that state transitions are independent. We show that a recent approach to modeling qualitative uncertainty using plausibility measures allows us to make such a qualitative Markov assumption in a relatively straightforward way, and show how the Markov assumption can be used to provide an attractive belief-change model.
Learning Bayesian Networks with Local Structure
Feb 13, 2013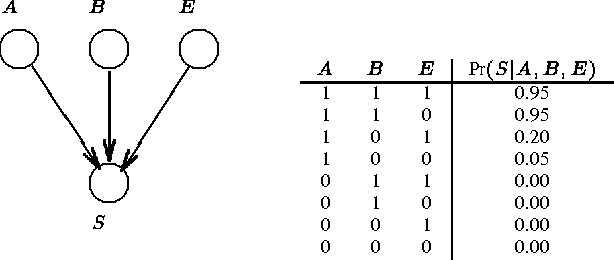


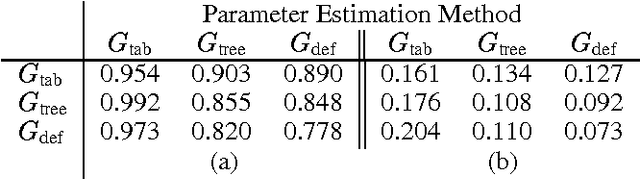
In this paper we examine a novel addition to the known methods for learning Bayesian networks from data that improves the quality of the learned networks. Our approach explicitly represents and learns the local structure in the conditional probability tables (CPTs), that quantify these networks. This increases the space of possible models, enabling the representation of CPTs with a variable number of parameters that depends on the learned local structures. The resulting learning procedure is capable of inducing models that better emulate the real complexity of the interactions present in the data. We describe the theoretical foundations and practical aspects of learning local structures, as well as an empirical evaluation of the proposed method. This evaluation indicates that learning curves characterizing the procedure that exploits the local structure converge faster than these of the standard procedure. Our results also show that networks learned with local structure tend to be more complex (in terms of arcs), yet require less parameters.
Context-Specific Independence in Bayesian Networks
Feb 13, 2013
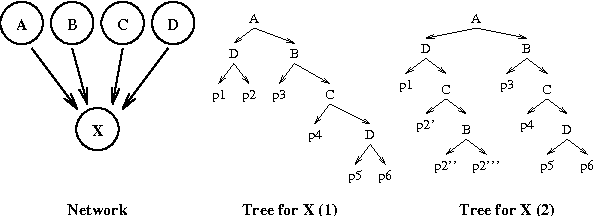
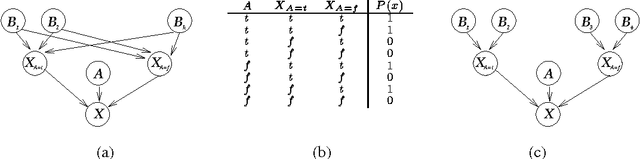

Bayesian networks provide a language for qualitatively representing the conditional independence properties of a distribution. This allows a natural and compact representation of the distribution, eases knowledge acquisition, and supports effective inference algorithms. It is well-known, however, that there are certain independencies that we cannot capture qualitatively within the Bayesian network structure: independencies that hold only in certain contexts, i.e., given a specific assignment of values to certain variables. In this paper, we propose a formal notion of context-specific independence (CSI), based on regularities in the conditional probability tables (CPTs) at a node. We present a technique, analogous to (and based on) d-separation, for determining when such independence holds in a given network. We then focus on a particular qualitative representation scheme - tree-structured CPTs - for capturing CSI. We suggest ways in which this representation can be used to support effective inference algorithms. In particular, we present a structural decomposition of the resulting network which can improve the performance of clustering algorithms, and an alternative algorithm based on cutset conditioning.
Image Segmentation in Video Sequences: A Probabilistic Approach
Feb 06, 2013

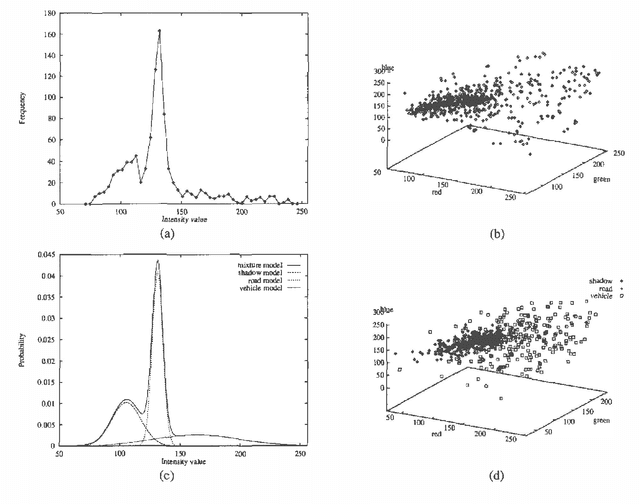

"Background subtraction" is an old technique for finding moving objects in a video sequence for example, cars driving on a freeway. The idea is that subtracting the current image from a timeaveraged background image will leave only nonstationary objects. It is, however, a crude approximation to the task of classifying each pixel of the current image; it fails with slow-moving objects and does not distinguish shadows from moving objects. The basic idea of this paper is that we can classify each pixel using a model of how that pixel looks when it is part of different classes. We learn a mixture-of-Gaussians classification model for each pixel using an unsupervised technique- an efficient, incremental version of EM. Unlike the standard image-averaging approach, this automatically updates the mixture component for each class according to likelihood of membership; hence slow-moving objects are handled perfectly. Our approach also identifies and eliminates shadows much more effectively than other techniques such as thresholding. Application of this method as part of the Roadwatch traffic surveillance project is expected to result in significant improvements in vehicle identification and tracking.
Sequential Update of Bayesian Network Structure
Feb 06, 2013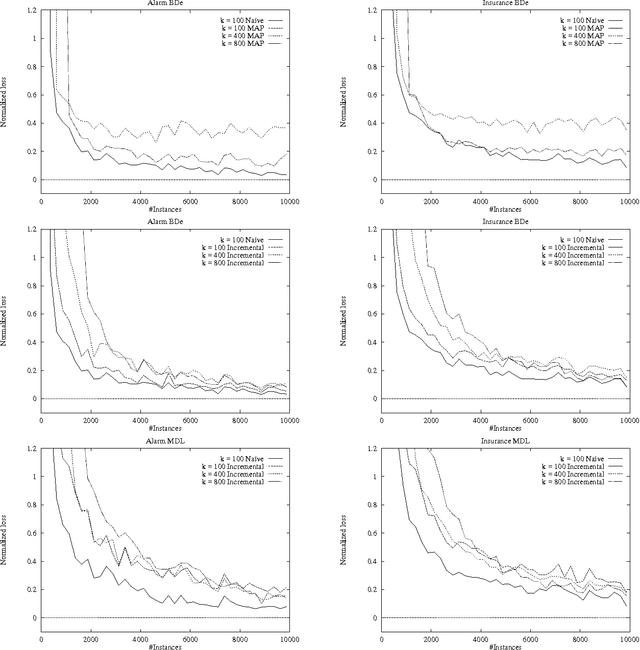
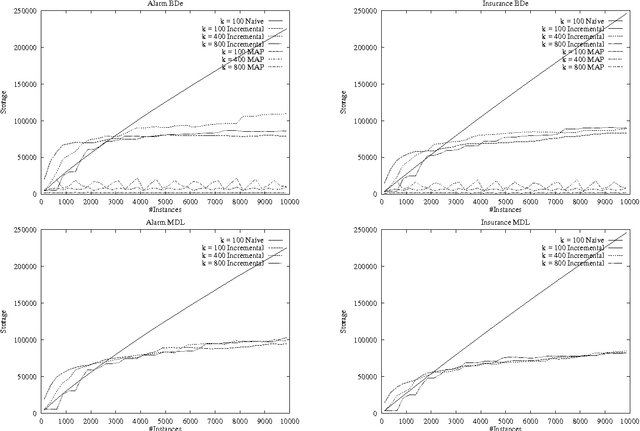
There is an obvious need for improving the performance and accuracy of a Bayesian network as new data is observed. Because of errors in model construction and changes in the dynamics of the domains, we cannot afford to ignore the information in new data. While sequential update of parameters for a fixed structure can be accomplished using standard techniques, sequential update of network structure is still an open problem. In this paper, we investigate sequential update of Bayesian networks were both parameters and structure are expected to change. We introduce a new approach that allows for the flexible manipulation of the tradeoff between the quality of the learned networks and the amount of information that is maintained about past observations. We formally describe our approach including the necessary modifications to the scoring functions for learning Bayesian networks, evaluate its effectiveness through an empirical study, and extend it to the case of missing data.
Learning the Structure of Dynamic Probabilistic Networks
Jan 30, 2013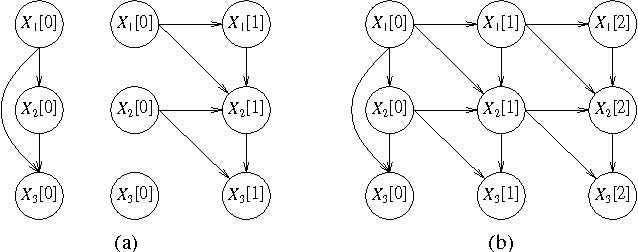

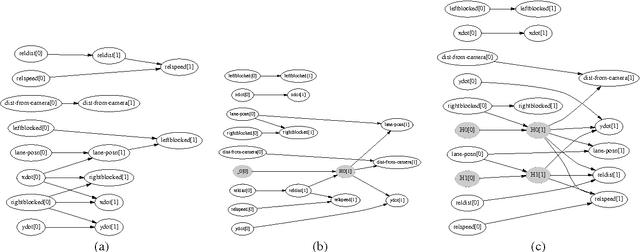

Dynamic probabilistic networks are a compact representation of complex stochastic processes. In this paper we examine how to learn the structure of a DPN from data. We extend structure scoring rules for standard probabilistic networks to the dynamic case, and show how to search for structure when some of the variables are hidden. Finally, we examine two applications where such a technology might be useful: predicting and classifying dynamic behaviors, and learning causal orderings in biological processes. We provide empirical results that demonstrate the applicability of our methods in both domains.
The Bayesian Structural EM Algorithm
Jan 30, 2013

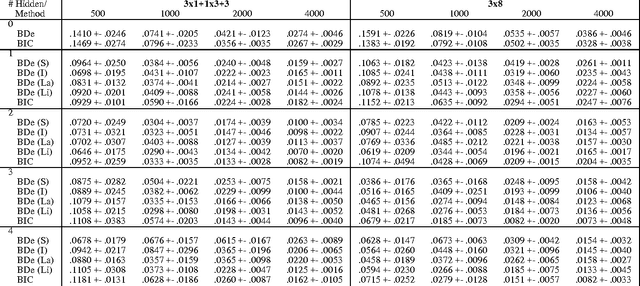
In recent years there has been a flurry of works on learning Bayesian networks from data. One of the hard problems in this area is how to effectively learn the structure of a belief network from incomplete data- that is, in the presence of missing values or hidden variables. In a recent paper, I introduced an algorithm called Structural EM that combines the standard Expectation Maximization (EM) algorithm, which optimizes parameters, with structure search for model selection. That algorithm learns networks based on penalized likelihood scores, which include the BIC/MDL score and various approximations to the Bayesian score. In this paper, I extend Structural EM to deal directly with Bayesian model selection. I prove the convergence of the resulting algorithm and show how to apply it for learning a large class of probabilistic models, including Bayesian networks and some variants thereof.