 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning with Expected Error Reduction
Nov 17, 2022Active learning has been studied extensively as a method for efficient data collection. Among the many approaches in literature, Expected Error Reduction (EER) (Roy and McCallum) has been shown to be an effective method for active learning: select the candidate sample that, in expectation, maximally decreases the error on an unlabeled set. However, EER requires the model to be retrained for every candidate sample and thus has not been widely used for modern deep neural networks due to this large computational cost. In this paper we reformulate EER under the lens of Bayesian active learning and derive a computationally efficient version that can use any Bayesian parameter sampling method (such as arXiv:1506.02142). We then compare the empirical performance of our method using Monte Carlo dropout for parameter sampling against state of the art methods in the deep active learning literature. Experiments are performed on four standard benchmark datasets and three WILDS datasets (arXiv:2012.07421). The results indicate that our method outperforms all other methods except one in the data shift scenario: a model dependent, non-information theoretic method that requires an order of magnitude higher computational cost (arXiv:1906.03671).
Proceedings of the Sixteenth Conference on Uncertainty in Artificial Intelligence (2000)
Aug 28, 2014This is the Proceedings of the Sixteenth Conference on Uncertainty in Artificial Intelligence, which was held in San Francisco, CA, June 30 - July 3, 2000
Deciding Consistency of Databases Containing Defeasible and Strict Information
Mar 27, 2013We propose a norm of consistency for a mixed set of defeasible and strict sentences, based on a probabilistic semantics. This norm establishes a clear distinction between knowledge bases depicting exceptions and those containing outright contradictions. We then define a notion of entailment based also on probabilistic considerations and provide a characterization of the relation between consistency and entailment. We derive necessary and sufficient conditions for consistency, and provide a simple decision procedure for testing consistency and deciding whether a sentence is entailed by a database. Finally, it is shown that if al1 sentences are Horn clauses, consistency and entailment can be tested in polynomial time.
Reasoning With Qualitative Probabilities Can Be Tractable
Mar 13, 2013We recently described a formalism for reasoning with if-then rules that re expressed with different levels of firmness [18]. The formalism interprets these rules as extreme conditional probability statements, specifying orders of magnitude of disbelief, which impose constraints over possible rankings of worlds. It was shown that, once we compute a priority function Z+ on the rules, the degree to which a given query is confirmed or denied can be computed in O(log n`) propositional satisfiability tests, where n is the number of rules in the knowledge base. In this paper, we show that computing Z+ requires O(n2 X log n) satisfiability tests, not an exponential number as was conjectured in [18], which reduces to polynomial complexity in the case of Horn expressions. We also show how reasoning with imprecise observations can be incorporated in our formalism and how the popular notions of belief revision and epistemic entrenchment are embodied naturally and tractably.
On the Relation between Kappa Calculus and Probabilistic Reasoning
Feb 27, 2013
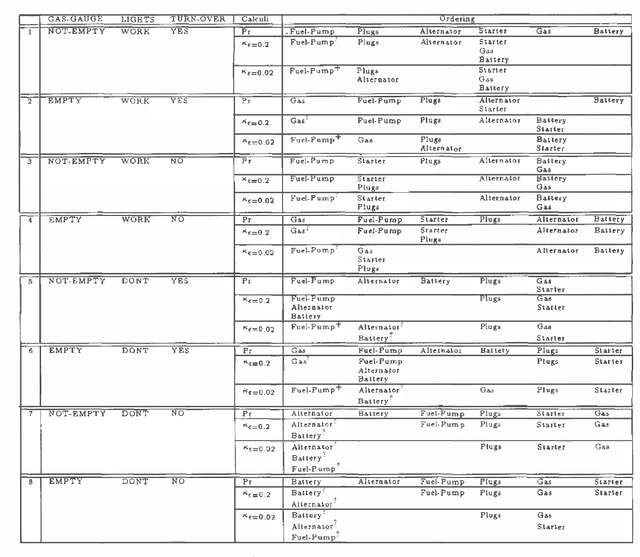


We study the connection between kappa calculus and probabilistic reasoning in diagnosis applications. Specifically, we abstract a probabilistic belief network for diagnosing faults into a kappa network and compare the ordering of faults computed using both methods. We show that, at least for the example examined, the ordering of faults coincide as long as all the causal relations in the original probabilistic network are taken into account. We also provide a formal analysis of some network structures where the two methods will differ. Both kappa rankings and infinitesimal probabilities have been used extensively to study default reasoning and belief revision. But little has been done on utilizing their connection as outlined above. This is partly because the relation between kappa and probability calculi assumes that probabilities are arbitrarily close to one (or zero). The experiments in this paper investigate this relation when this assumption is not satisfied. The reported results have important implications on the use of kappa rankings to enhance the knowledge engineering of uncertainty models.
Action Networks: A Framework for Reasoning about Actions and Change under Uncertainty
Feb 27, 2013

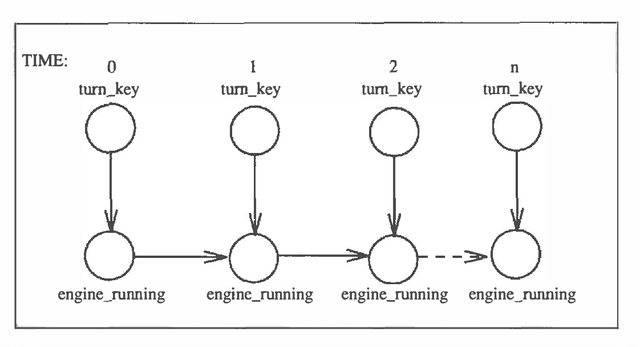

This work proposes action networks as a semantically well-founded framework for reasoning about actions and change under uncertainty. Action networks add two primitives to probabilistic causal networks: controllable variables and persistent variables. Controllable variables allow the representation of actions as directly setting the value of specific events in the domain, subject to preconditions. Persistent variables provide a canonical model of persistence according to which both the state of a variable and the causal mechanism dictating its value persist over time unless intervened upon by an action (or its consequences). Action networks also allow different methods for quantifying the uncertainty in causal relationships, which go beyond traditional probabilistic quantification. This paper describes both recent results and work in progress.
Fast Belief Update Using Order-of-Magnitude Probabilities
Feb 20, 2013We present an algorithm, called Predict, for updating beliefs in causal networks quantified with order-of-magnitude probabilities. The algorithm takes advantage of both the structure and the quantification of the network and presents a polynomial asymptotic complexity. Predict exhibits a conservative behavior in that it is always sound but not always complete. We provide sufficient conditions for completeness and present algorithms for testing these conditions and for computing a complete set of plausible values. We propose Predict as an efficient method to estimate probabilistic values and illustrate its use in conjunction with two known algorithms for probabilistic inference. Finally, we describe an application of Predict to plan evaluation, present experimental results, and discuss issues regarding its use with conditional logics of belief, and in the characterization of irrelevance.
Learning Bayesian Networks with Local Structure
Feb 13, 2013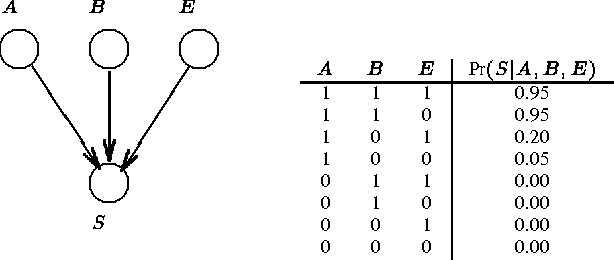


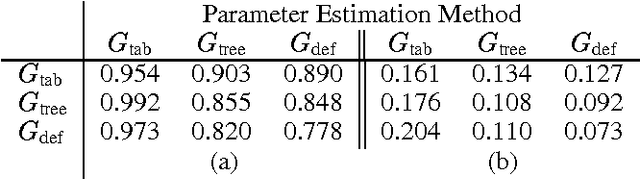
In this paper we examine a novel addition to the known methods for learning Bayesian networks from data that improves the quality of the learned networks. Our approach explicitly represents and learns the local structure in the conditional probability tables (CPTs), that quantify these networks. This increases the space of possible models, enabling the representation of CPTs with a variable number of parameters that depends on the learned local structures. The resulting learning procedure is capable of inducing models that better emulate the real complexity of the interactions present in the data. We describe the theoretical foundations and practical aspects of learning local structures, as well as an empirical evaluation of the proposed method. This evaluation indicates that learning curves characterizing the procedure that exploits the local structure converge faster than these of the standard procedure. Our results also show that networks learned with local structure tend to be more complex (in terms of arcs), yet require less parameters.
Context-Specific Independence in Bayesian Networks
Feb 13, 2013
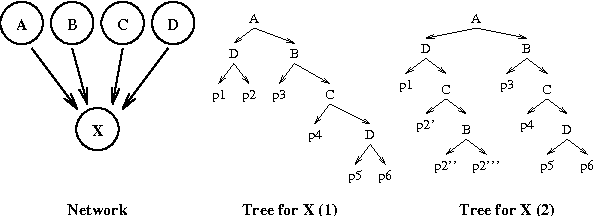

Bayesian networks provide a language for qualitatively representing the conditional independence properties of a distribution. This allows a natural and compact representation of the distribution, eases knowledge acquisition, and supports effective inference algorithms. It is well-known, however, that there are certain independencies that we cannot capture qualitatively within the Bayesian network structure: independencies that hold only in certain contexts, i.e., given a specific assignment of values to certain variables. In this paper, we propose a formal notion of context-specific independence (CSI), based on regularities in the conditional probability tables (CPTs) at a node. We present a technique, analogous to (and based on) d-separation, for determining when such independence holds in a given network. We then focus on a particular qualitative representation scheme - tree-structured CPTs - for capturing CSI. We suggest ways in which this representation can be used to support effective inference algorithms. In particular, we present a structural decomposition of the resulting network which can improve the performance of clustering algorithms, and an alternative algorithm based on cutset conditioning.
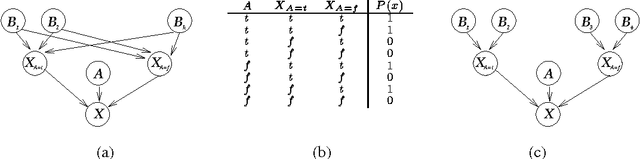
Sequential Update of Bayesian Network Structure
Feb 06, 2013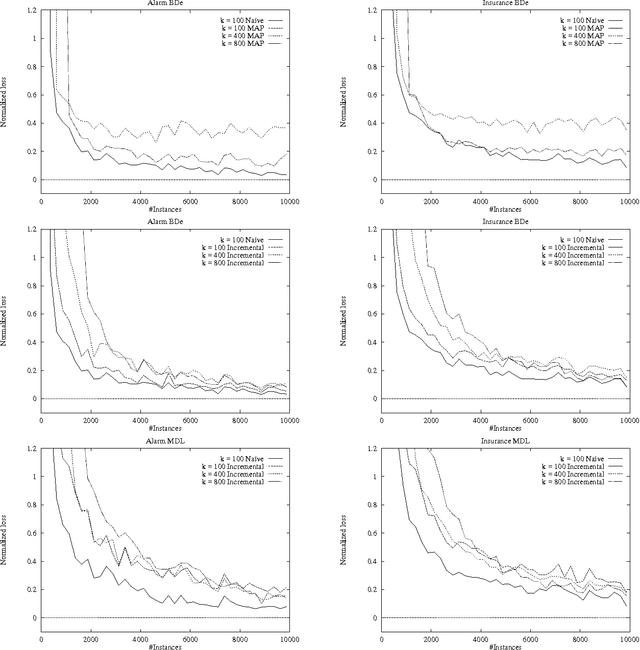
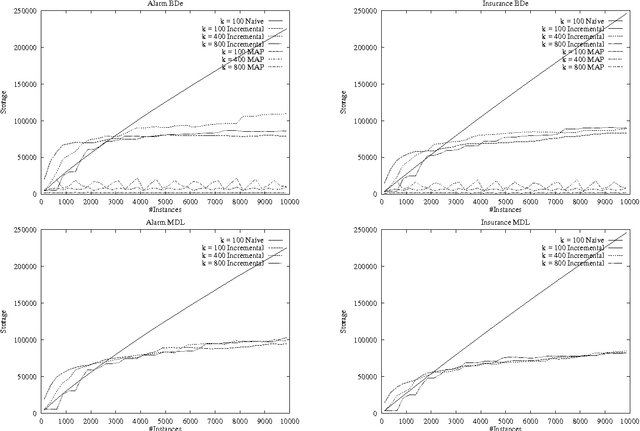
There is an obvious need for improving the performance and accuracy of a Bayesian network as new data is observed. Because of errors in model construction and changes in the dynamics of the domains, we cannot afford to ignore the information in new data. While sequential update of parameters for a fixed structure can be accomplished using standard techniques, sequential update of network structure is still an open problem. In this paper, we investigate sequential update of Bayesian networks were both parameters and structure are expected to change. We introduce a new approach that allows for the flexible manipulation of the tradeoff between the quality of the learned networks and the amount of information that is maintained about past observations. We formally describe our approach including the necessary modifications to the scoring functions for learning Bayesian networks, evaluate its effectiveness through an empirical study, and extend it to the case of missing data.