 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning with Expected Error Reduction
Nov 17, 2022Active learning has been studied extensively as a method for efficient data collection. Among the many approaches in literature, Expected Error Reduction (EER) (Roy and McCallum) has been shown to be an effective method for active learning: select the candidate sample that, in expectation, maximally decreases the error on an unlabeled set. However, EER requires the model to be retrained for every candidate sample and thus has not been widely used for modern deep neural networks due to this large computational cost. In this paper we reformulate EER under the lens of Bayesian active learning and derive a computationally efficient version that can use any Bayesian parameter sampling method (such as arXiv:1506.02142). We then compare the empirical performance of our method using Monte Carlo dropout for parameter sampling against state of the art methods in the deep active learning literature. Experiments are performed on four standard benchmark datasets and three WILDS datasets (arXiv:2012.07421). The results indicate that our method outperforms all other methods except one in the data shift scenario: a model dependent, non-information theoretic method that requires an order of magnitude higher computational cost (arXiv:1906.03671).
Cooperative Multi-Agent Reinforcement Learning for Low-Level Wireless Communication
Jan 14, 2018
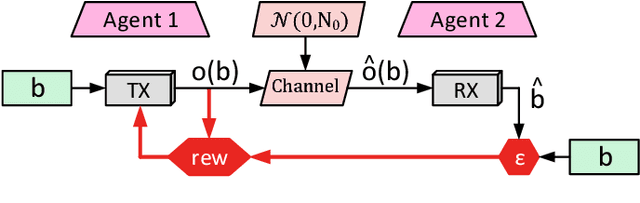
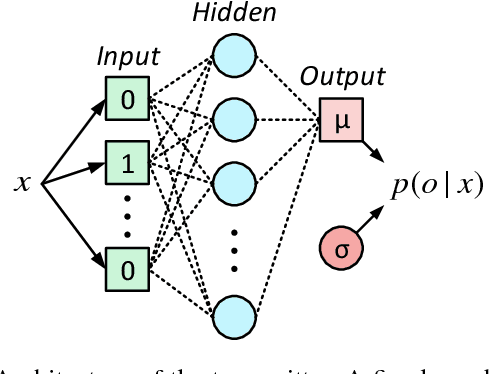
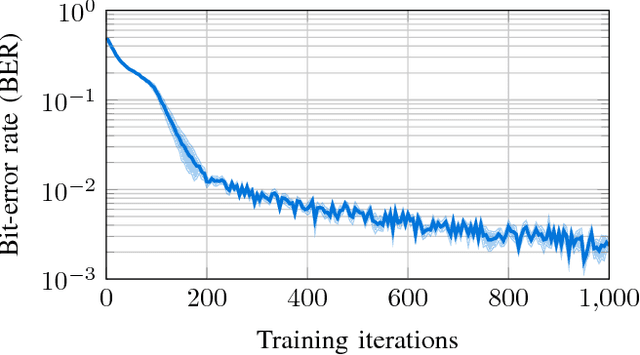
Traditional radio systems are strictly co-designed on the lower levels of the OSI stack for compatibility and efficiency. Although this has enabled the success of radio communications, it has also introduced lengthy standardization processes and imposed static allocation of the radio spectrum. Various initiatives have been undertaken by the research community to tackle the problem of artificial spectrum scarcity by both making frequency allocation more dynamic and building flexible radios to replace the static ones. There is reason to believe that just as computer vision and control have been overhauled by the introduction of machine learning, wireless communication can also be improved by utilizing similar techniques to increase the flexibility of wireless networks. In this work, we pose the problem of discovering low-level wireless communication schemes ex-nihilo between two agents in a fully decentralized fashion as a reinforcement learning problem. Our proposed approach uses policy gradients to learn an optimal bi-directional communication scheme and shows surprisingly sophisticated and intelligent learning behavior. We present the results of extensive experiments and an analysis of the fidelity of our approach.