 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovariance Prediction via Convex Optimization
Jan 29, 2021
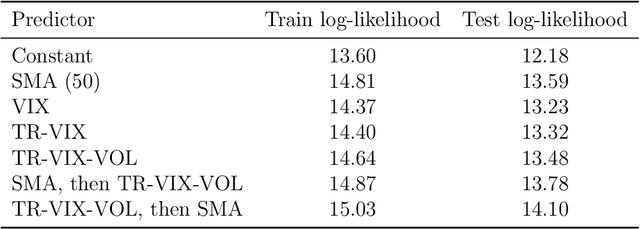
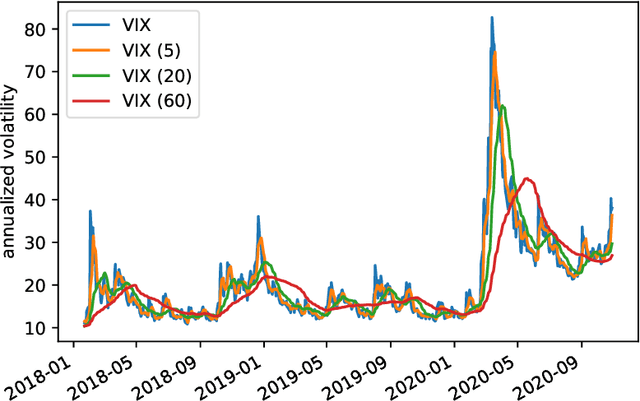
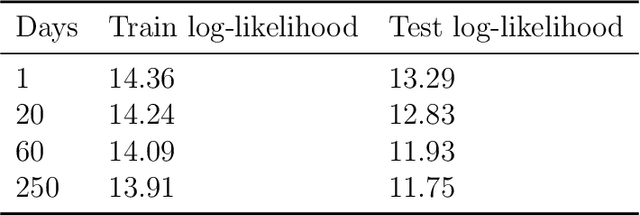
We consider the problem of predicting the covariance of a zero mean Gaussian vector, based on another feature vector. We describe a covariance predictor that has the form of a generalized linear model, i.e., an affine function of the features followed by an inverse link function that maps vectors to symmetric positive definite matrices. The log-likelihood is a concave function of the predictor parameters, so fitting the predictor involves convex optimization. Such predictors can be combined with others, or recursively applied to improve performance.
Low Rank Forecasting
Jan 29, 2021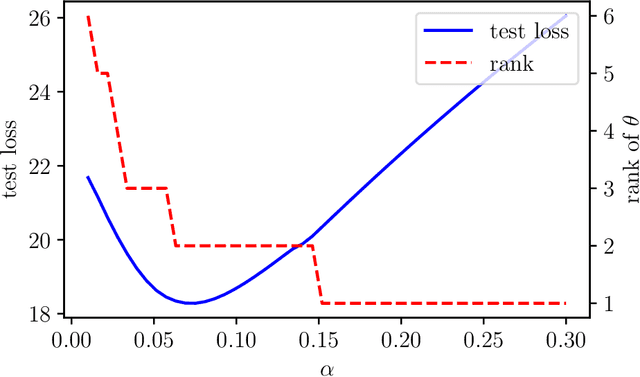
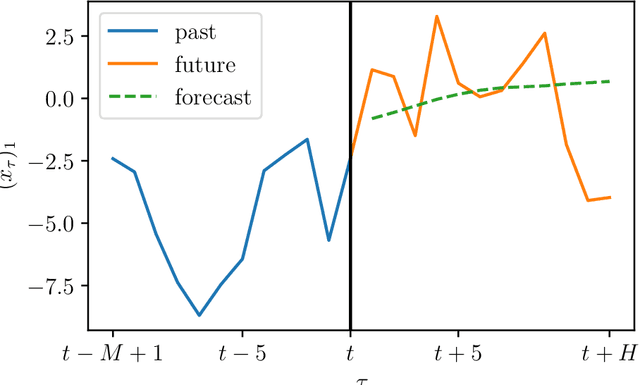
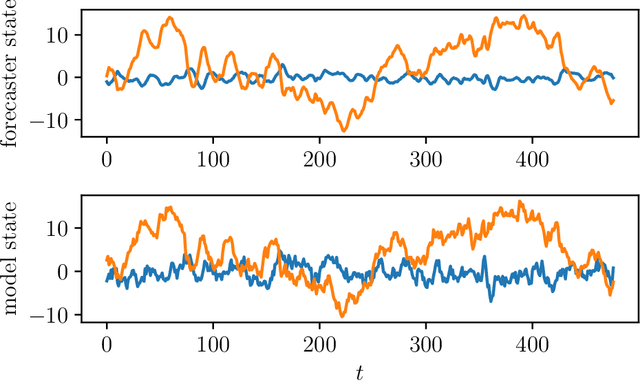
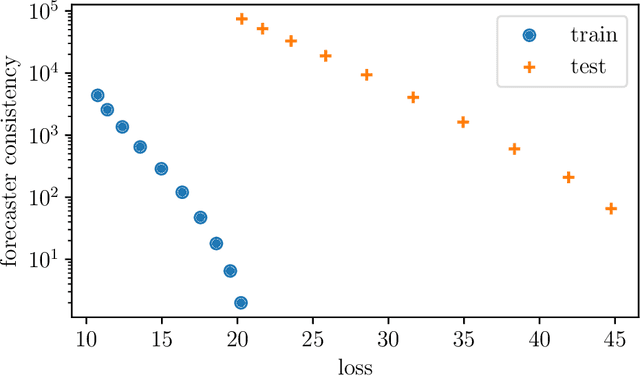
We consider the problem of forecasting multiple values of the future of a vector time series, using some past values. This problem, and related ones such as one-step-ahead prediction, have a very long history, and there are a number of well-known methods for it, including vector auto-regressive models, state-space methods, multi-task regression, and others. Our focus is on low rank forecasters, which break forecasting up into two steps: estimating a vector that can be interpreted as a latent state, given the past, and then estimating the future values of the time series, given the latent state estimate. We introduce the concept of forecast consistency, which means that the estimates of the same value made at different times are consistent. We formulate the forecasting problem in general form, and focus on linear forecasters, for which we propose a formulation that can be solved via convex optimization. We describe a number of extensions and variations, including nonlinear forecasters, data weighting, the inclusion of auxiliary data, and additional objective terms. We illustrate our methods with several examples.
Learning Convex Optimization Models
Jun 18, 2020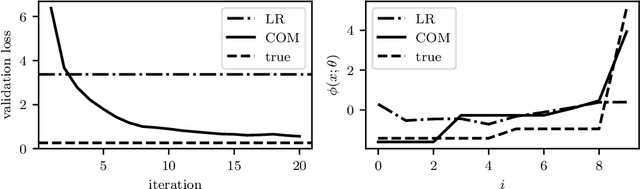
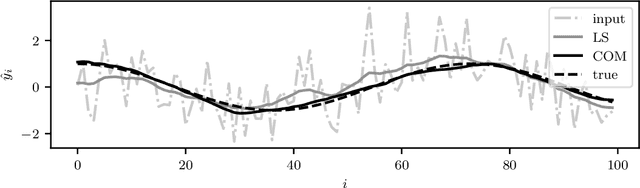
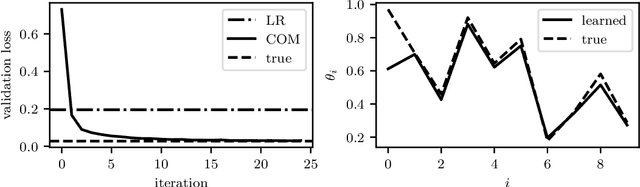
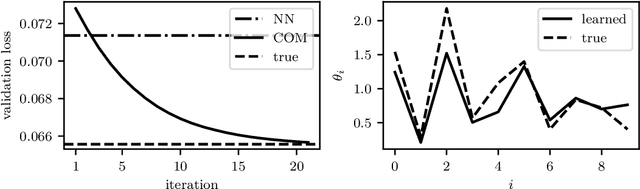
A convex optimization model predicts an output from an input by solving a convex optimization problem. The class of convex optimization models is large, and includes as special cases many well-known models like linear and logistic regression. We propose a heuristic for learning the parameters in a convex optimization model given a dataset of input-output pairs, using recently developed methods for differentiating the solution of a convex optimization problem with respect to its parameters. We describe three general classes of convex optimization models, maximum a posteriori (MAP) models, utility maximization models, and agent models, and present a numerical experiment for each.
Optimal Representative Sample Weighting
May 18, 2020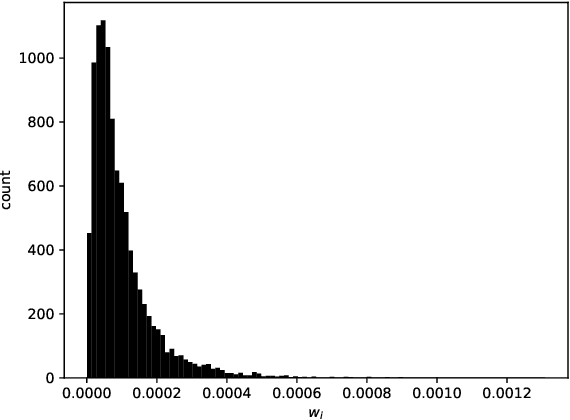

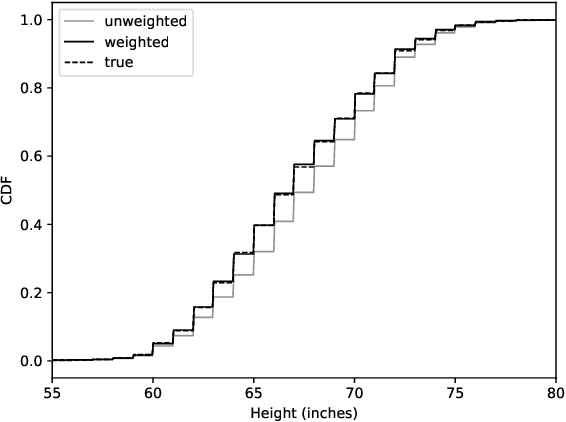
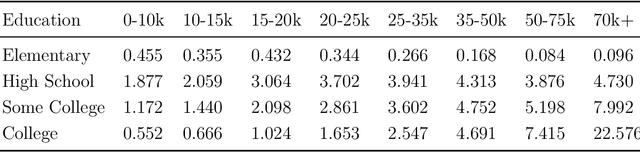
We consider the problem of assigning weights to a set of samples or data records, with the goal of achieving a representative weighting, which happens when certain sample averages of the data are close to prescribed values. We frame the problem of finding representative sample weights as an optimization problem, which in many cases is convex and can be efficiently solved. Our formulation includes as a special case the selection of a fixed number of the samples, with equal weights, i.e., the problem of selecting a smaller representative subset of the samples. While this problem is combinatorial and not convex, heuristic methods based on convex optimization seem to perform very well. We describe rsw, an open-source implementation of the ideas described in this paper, and apply it to a skewed sample of the CDC BRFSS dataset.
Learning Convex Optimization Control Policies
Dec 19, 2019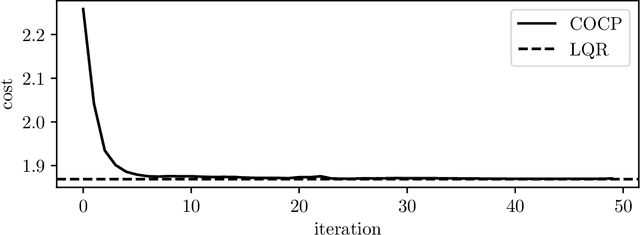
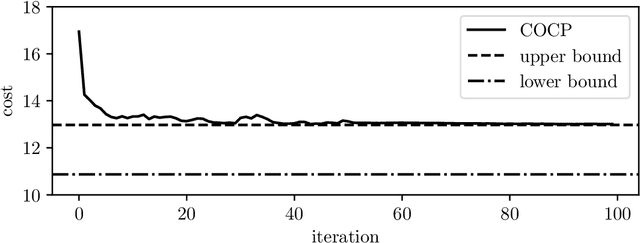
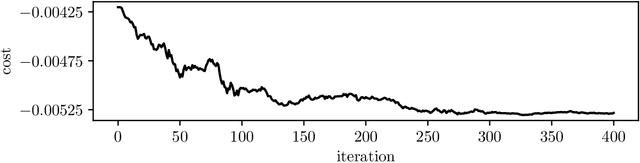
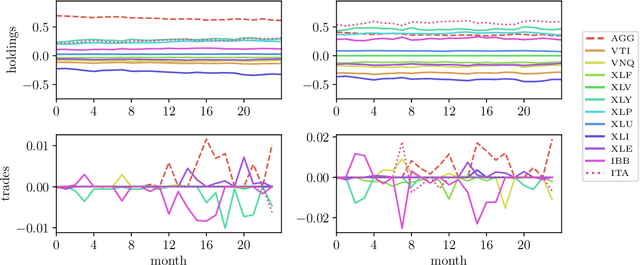
Many control policies used in various applications determine the input or action by solving a convex optimization problem that depends on the current state and some parameters. Common examples of such convex optimization control policies (COCPs) include the linear quadratic regulator (LQR), convex model predictive control (MPC), and convex control-Lyapunov or approximate dynamic programming (ADP) policies. These types of control policies are tuned by varying the parameters in the optimization problem, such as the LQR weights, to obtain good performance, judged by application-specific metrics. Tuning is often done by hand, or by simple methods such as a crude grid search. In this paper we propose a method to automate this process, by adjusting the parameters using an approximate gradient of the performance metric with respect to the parameters. Our method relies on recently developed methods that can efficiently evaluate the derivative of the solution of a convex optimization problem with respect to its parameters. We illustrate our method on several examples.
Minimizing a Sum of Clipped Convex Functions
Oct 29, 2019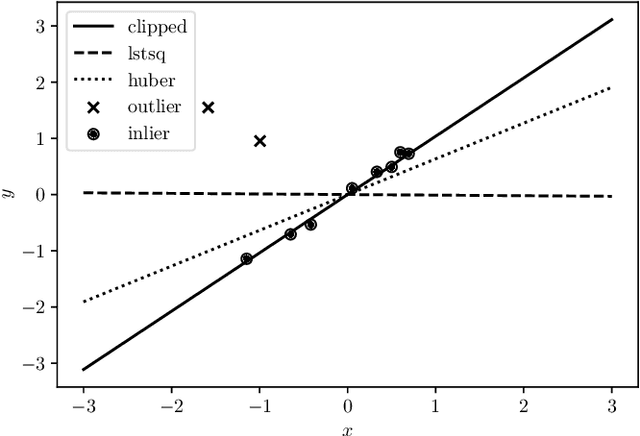
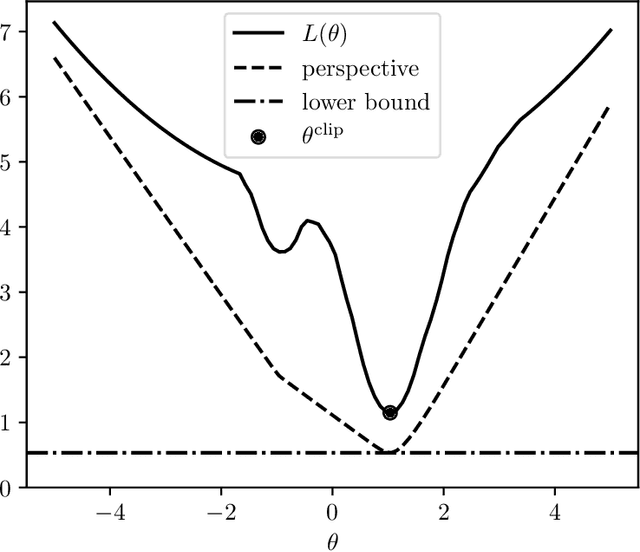
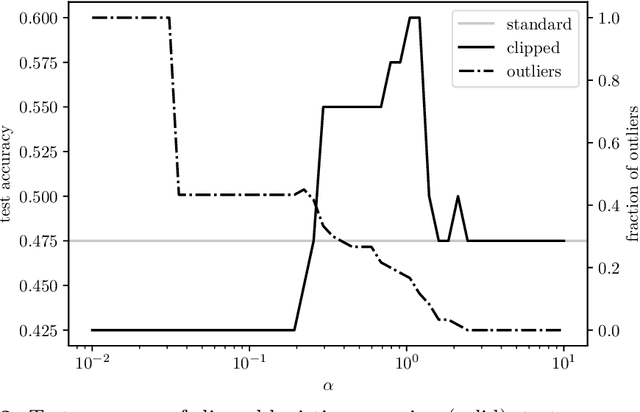
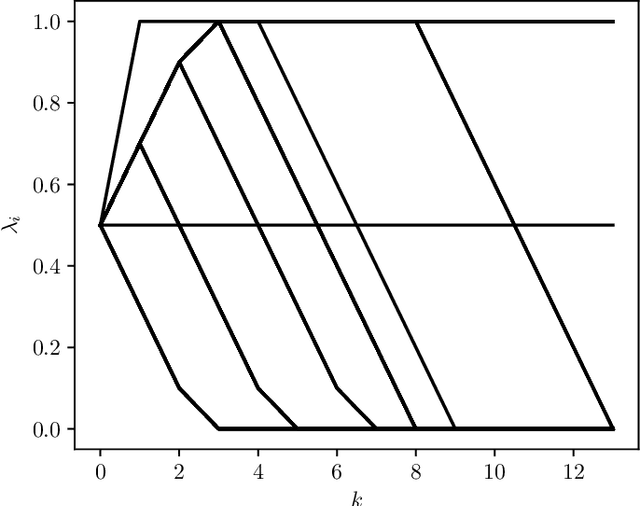
We consider the problem of minimizing a sum of clipped convex functions; applications include clipped empirical risk minimization and clipped control. While the problem of minimizing the sum of clipped convex functions is NP-hard, we present some heuristics for approximately solving instances of these problems. These heuristics can be used to find good, if not global, solutions and appear to work well in practice. We also describe an alternative formulation, based on the perspective transformation, which makes the problem amenable to mixed-integer convex programming and yields computationally tractable lower bounds. We illustrate one of our heuristic methods by applying it to various examples and use the perspective transformation to certify that the solutions are relatively close to the global optimum. This paper is accompanied by an open-source implementation.
Differentiable Convex Optimization Layers
Oct 28, 2019

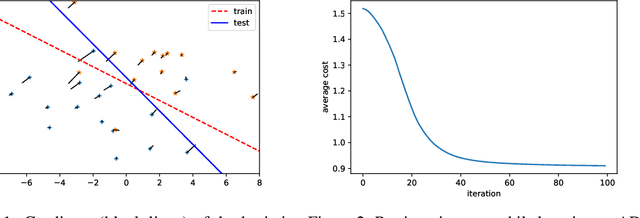
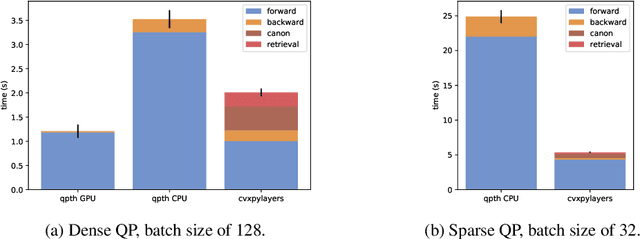
Recent work has shown how to embed differentiable optimization problems (that is, problems whose solutions can be backpropagated through) as layers within deep learning architectures. This method provides a useful inductive bias for certain problems, but existing software for differentiable optimization layers is rigid and difficult to apply to new settings. In this paper, we propose an approach to differentiating through disciplined convex programs, a subclass of convex optimization problems used by domain-specific languages (DSLs) for convex optimization. We introduce disciplined parametrized programming, a subset of disciplined convex programming, and we show that every disciplined parametrized program can be represented as the composition of an affine map from parameters to problem data, a solver, and an affine map from the solver's solution to a solution of the original problem (a new form we refer to as affine-solver-affine form). We then demonstrate how to efficiently differentiate through each of these components, allowing for end-to-end analytical differentiation through the entire convex program. We implement our methodology in version 1.1 of CVXPY, a popular Python-embedded DSL for convex optimization, and additionally implement differentiable layers for disciplined convex programs in PyTorch and TensorFlow 2.0. Our implementation significantly lowers the barrier to using convex optimization problems in differentiable programs. We present applications in linear machine learning models and in stochastic control, and we show that our layer is competitive (in execution time) compared to specialized differentiable solvers from past work.
A Distributed Method for Fitting Laplacian Regularized Stratified Models
Apr 26, 2019
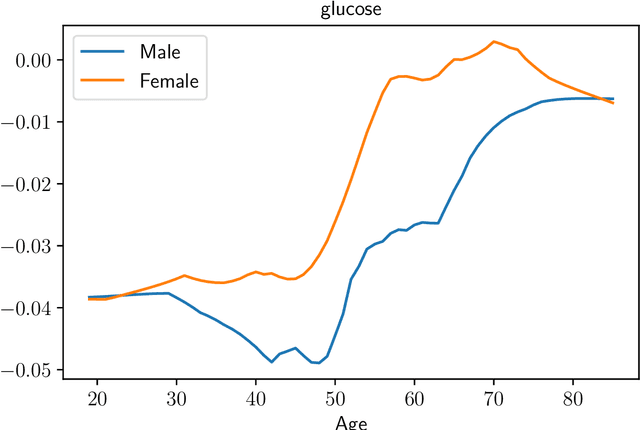
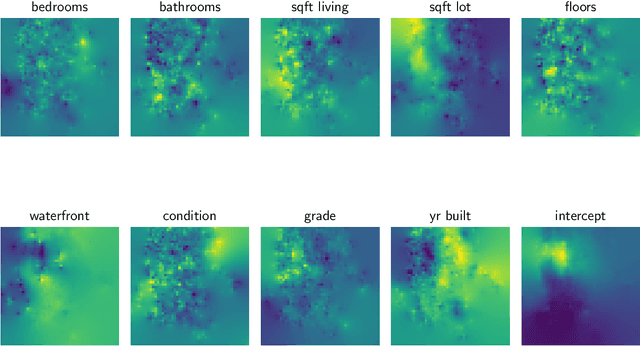
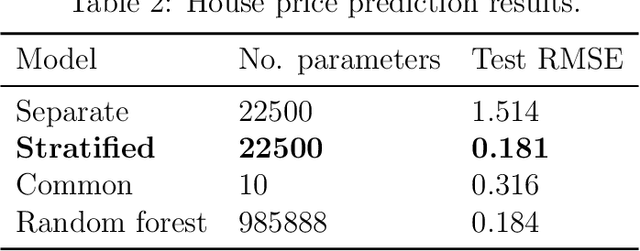
Stratified models are models that depend in an arbitrary way on a set of selected categorical features, and depend linearly on the other features. In a basic and traditional formulation a separate model is fit for each value of the categorical feature, using only the data that has the specific categorical value. To this formulation we add Laplacian regularization, which encourages the model parameters for neighboring categorical values to be similar. Laplacian regularization allows us to specify one or more weighted graphs on the stratification feature values. For example, stratifying over the days of the week, we can specify that the Sunday model parameter should be close to the Saturday and Monday model parameters. The regularization improves the performance of the model over the traditional stratified model, since the model for each value of the categorical `borrows strength' from its neighbors. In particular, it produces a model even for categorical values that did not appear in the training data set. We propose an efficient distributed method for fitting stratified models, based on the alternating direction method of multipliers (ADMM). When the fitting loss functions are convex, the stratified model fitting problem is convex, and our method computes the global minimizer of the loss plus regularization; in other cases it computes a local minimizer. The method is very efficient, and naturally scales to large data sets or numbers of stratified feature values. We illustrate our method with a variety of examples.
Least Squares Auto-Tuning
Apr 10, 2019
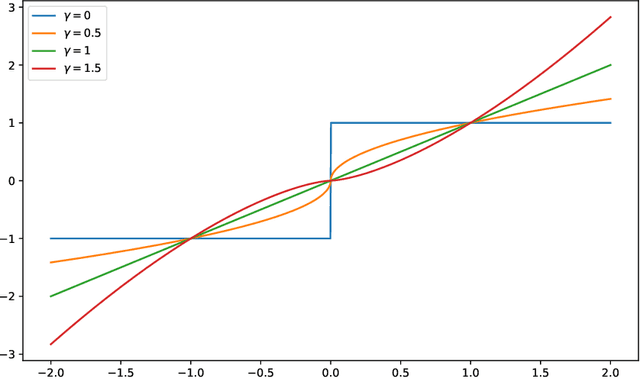


Least squares is by far the simplest and most commonly applied computational method in many fields. In almost all applications, the least squares objective is rarely the true objective. We account for this discrepancy by parametrizing the least squares problem and automatically adjusting these parameters using an optimization algorithm. We apply our method, which we call least squares auto-tuning, to data fitting.
Learning Probabilistic Trajectory Models of Aircraft in Terminal Airspace from Position Data
Oct 22, 2018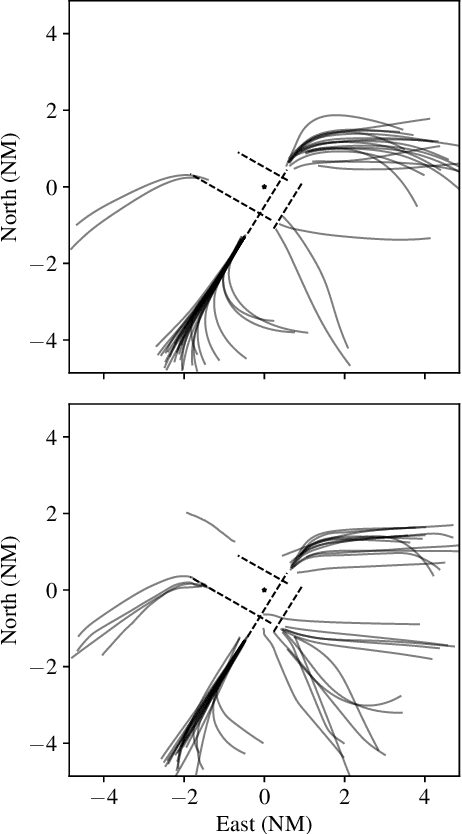
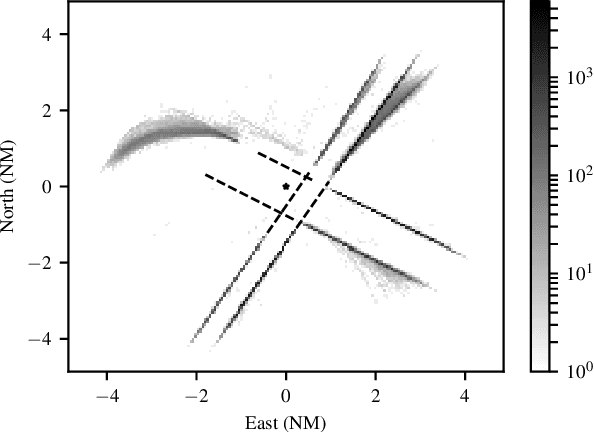
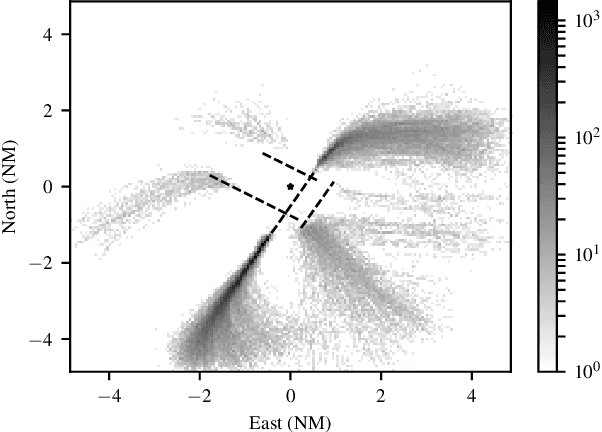
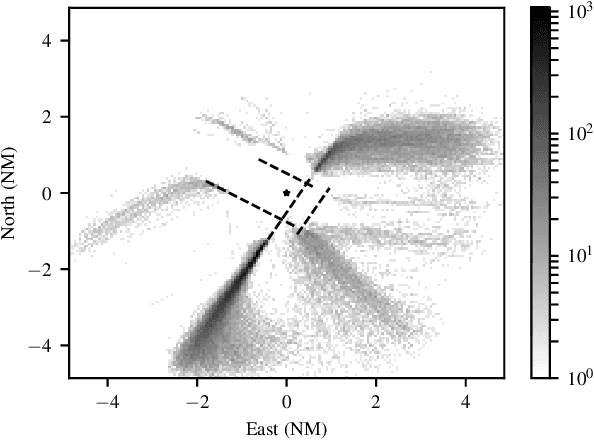
Models for predicting aircraft motion are an important component of modern aeronautical systems. These models help aircraft plan collision avoidance maneuvers and help conduct offline performance and safety analyses. In this article, we develop a method for learning a probabilistic generative model of aircraft motion in terminal airspace, the controlled airspace surrounding a given airport. The method fits the model based on a historical dataset of radar-based position measurements of aircraft landings and takeoffs at that airport. We find that the model generates realistic trajectories, provides accurate predictions, and captures the statistical properties of aircraft trajectories. Furthermore, the model trains quickly, is compact, and allows for efficient real-time inference.