 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Bayesian Structural EM Algorithm
Paper and Code
Jan 30, 2013

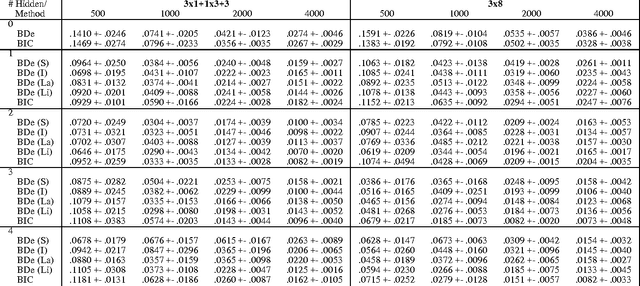
In recent years there has been a flurry of works on learning Bayesian networks from data. One of the hard problems in this area is how to effectively learn the structure of a belief network from incomplete data- that is, in the presence of missing values or hidden variables. In a recent paper, I introduced an algorithm called Structural EM that combines the standard Expectation Maximization (EM) algorithm, which optimizes parameters, with structure search for model selection. That algorithm learns networks based on penalized likelihood scores, which include the BIC/MDL score and various approximations to the Bayesian score. In this paper, I extend Structural EM to deal directly with Bayesian model selection. I prove the convergence of the resulting algorithm and show how to apply it for learning a large class of probabilistic models, including Bayesian networks and some variants thereof.