 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Based Bayesian Exploration
Paper and Code
Jan 23, 2013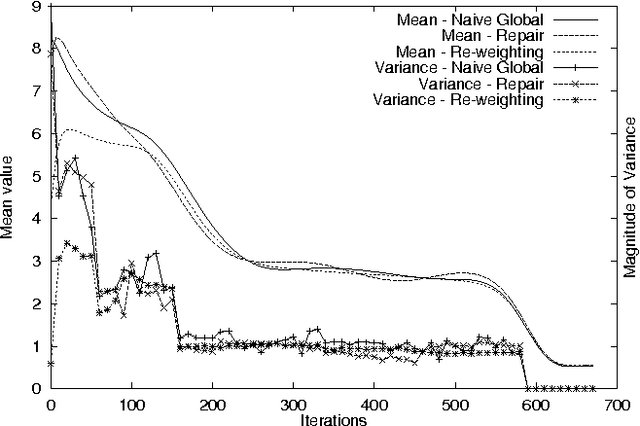
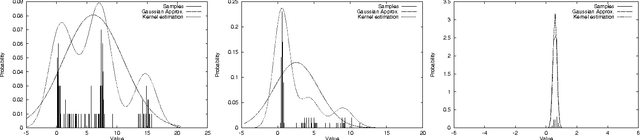
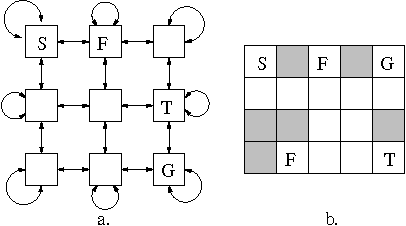
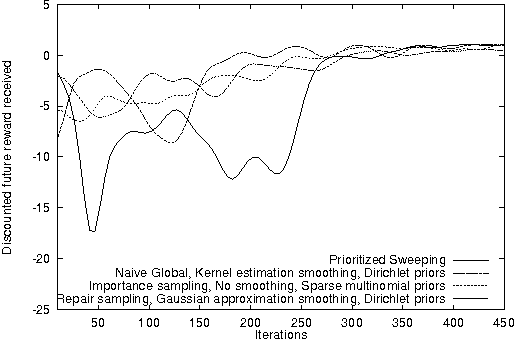
Reinforcement learning systems are often concerned with balancing exploration of untested actions against exploitation of actions that are known to be good. The benefit of exploration can be estimated using the classical notion of Value of Information - the expected improvement in future decision quality arising from the information acquired by exploration. Estimating this quantity requires an assessment of the agent's uncertainty about its current value estimates for states. In this paper we investigate ways of representing and reasoning about this uncertainty in algorithms where the system attempts to learn a model of its environment. We explicitly represent uncertainty about the parameters of the model and build probability distributions over Q-values based on these. These distributions are used to compute a myopic approximation to the value of information for each action and hence to select the action that best balances exploration and exploitation.