 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInductive biases, pretraining and fine-tuning jointly account for brain responses to speech
Paper and Code
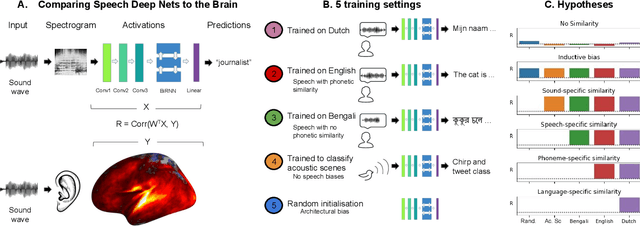
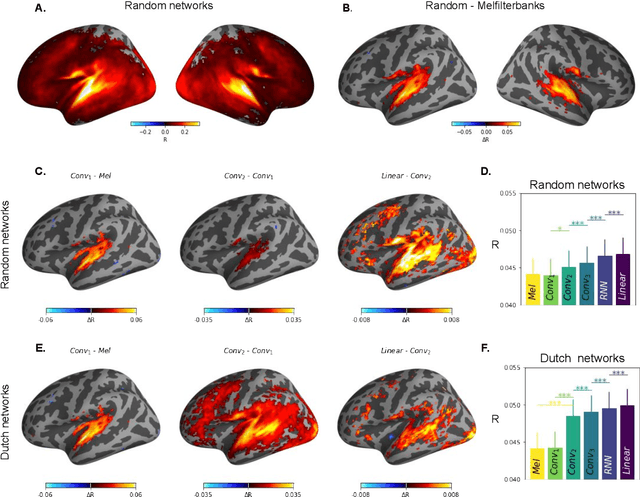
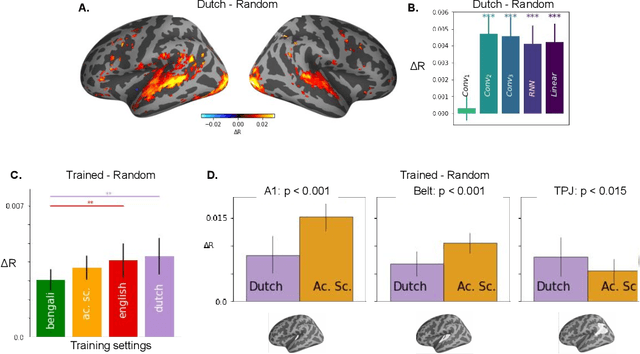
Our ability to comprehend speech remains, to date, unrivaled by deep learning models. This feat could result from the brain's ability to fine-tune generic sound representations for speech-specific processes. To test this hypothesis, we compare i) five types of deep neural networks to ii) human brain responses elicited by spoken sentences and recorded in 102 Dutch subjects using functional Magnetic Resonance Imaging (fMRI). Each network was either trained on an acoustics scene classification, a speech-to-text task (based on Bengali, English, or Dutch), or not trained. The similarity between each model and the brain is assessed by correlating their respective activations after an optimal linear projection. The differences in brain-similarity across networks revealed three main results. First, speech representations in the brain can be accounted for by random deep networks. Second, learning to classify acoustic scenes leads deep nets to increase their brain similarity. Third, learning to process phonetically-related speech inputs (i.e., Dutch vs English) leads deep nets to reach higher levels of brain-similarity than learning to process phonetically-distant speech inputs (i.e. Dutch vs Bengali). Together, these results suggest that the human brain fine-tunes its heavily-trained auditory hierarchy to learn to process speech.