 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovariance-aware sampling for Diffusion Models
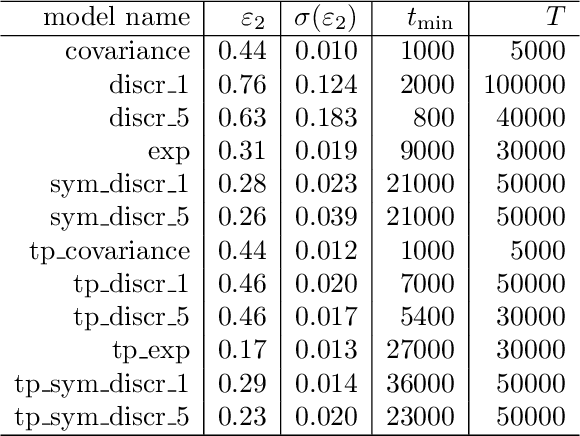
May 13, 2026We present a covariance-aware sampler that improves the quality of pixel-space Diffusion Model (DM) sampling in the few-step regime. We hypothesize that in the few-step regime samplers fail because they rely solely on the predicted mean of the reverse distribution, while our solution explicitly models the reverse-process covariance. Our method combines Tweedie's formula to estimate the covariance with an efficient, structured Fourier-space decomposition of the covariance matrix. Implemented as an extension of DDIM, our method requires only a minimal overhead: one extra Jacobian-Vector Product (JVP) per step. We demonstrate that for pixel-based DMs, our method consistently produces superior samples compared to state-of-the-art second order samplers (Heun, DPM-Solver++) and the recent aDDIM sampler, at an identical number of function evaluations (NFE).
Model Integrity when Unlearning with T2I Diffusion Models
Nov 04, 2024


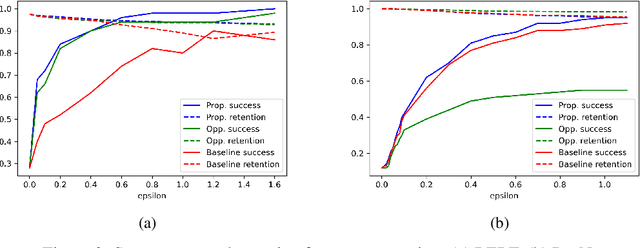
The rapid advancement of text-to-image Diffusion Models has led to their widespread public accessibility. However these models, trained on large internet datasets, can sometimes generate undesirable outputs. To mitigate this, approximate Machine Unlearning algorithms have been proposed to modify model weights to reduce the generation of specific types of images, characterized by samples from a ``forget distribution'', while preserving the model's ability to generate other images, characterized by samples from a ``retain distribution''. While these methods aim to minimize the influence of training data in the forget distribution without extensive additional computation, we point out that they can compromise the model's integrity by inadvertently affecting generation for images in the retain distribution. Recognizing the limitations of FID and CLIPScore in capturing these effects, we introduce a novel retention metric that directly assesses the perceptual difference between outputs generated by the original and the unlearned models. We then propose unlearning algorithms that demonstrate superior effectiveness in preserving model integrity compared to existing baselines. Given their straightforward implementation, these algorithms serve as valuable benchmarks for future advancements in approximate Machine Unlearning for Diffusion Models.
Gradient Sketches for Training Data Attribution and Studying the Loss Landscape
Feb 06, 2024Random projections or sketches of gradients and Hessian vector products play an essential role in applications where one needs to store many such vectors while retaining accurate information about their relative geometry. Two important scenarios are training data attribution (tracing a model's behavior to the training data), where one needs to store a gradient for each training example, and the study of the spectrum of the Hessian (to analyze the training dynamics), where one needs to store multiple Hessian vector products. While sketches that use dense matrices are easy to implement, they are memory bound and cannot be scaled to modern neural networks. Motivated by work on the intrinsic dimension of neural networks, we propose and study a design space for scalable sketching algorithms. We demonstrate the efficacy of our approach in three applications: training data attribution, the analysis of the Hessian spectrum and the computation of the intrinsic dimension when fine-tuning pre-trained language models.
Theoretical and Practical Perspectives on what Influence Functions Do
May 26, 2023


Influence functions (IF) have been seen as a technique for explaining model predictions through the lens of the training data. Their utility is assumed to be in identifying training examples "responsible" for a prediction so that, for example, correcting a prediction is possible by intervening on those examples (removing or editing them) and retraining the model. However, recent empirical studies have shown that the existing methods of estimating IF predict the leave-one-out-and-retrain effect poorly. In order to understand the mismatch between the theoretical promise and the practical results, we analyse five assumptions made by IF methods which are problematic for modern-scale deep neural networks and which concern convexity, numeric stability, training trajectory and parameter divergence. This allows us to clarify what can be expected theoretically from IF. We show that while most assumptions can be addressed successfully, the parameter divergence poses a clear limitation on the predictive power of IF: influence fades over training time even with deterministic training. We illustrate this theoretical result with BERT and ResNet models. Another conclusion from the theoretical analysis is that IF are still useful for model debugging and correcting even though some of the assumptions made in prior work do not hold: using natural language processing and computer vision tasks, we verify that mis-predictions can be successfully corrected by taking only a few fine-tuning steps on influential examples.
Cross-Lingual Supervision improves Large Language Models Pre-training
May 19, 2023The recent rapid progress in pre-training Large Language Models has relied on using self-supervised language modeling objectives like next token prediction or span corruption. On the other hand, Machine Translation Systems are mostly trained using cross-lingual supervision that requires aligned data between source and target languages. We demonstrate that pre-training Large Language Models on a mixture of a self-supervised Language Modeling objective and the supervised Machine Translation objective, therefore including cross-lingual parallel data during pre-training, yields models with better in-context learning abilities. As pre-training is a very resource-intensive process and a grid search on the best mixing ratio between the two objectives is prohibitively expensive, we propose a simple yet effective strategy to learn it during pre-training.
Scaling Up Influence Functions
Dec 06, 2021
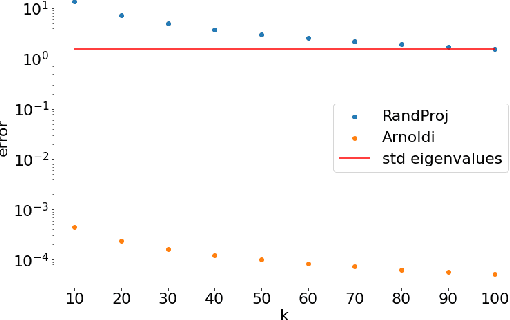
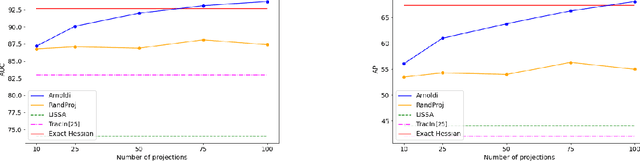
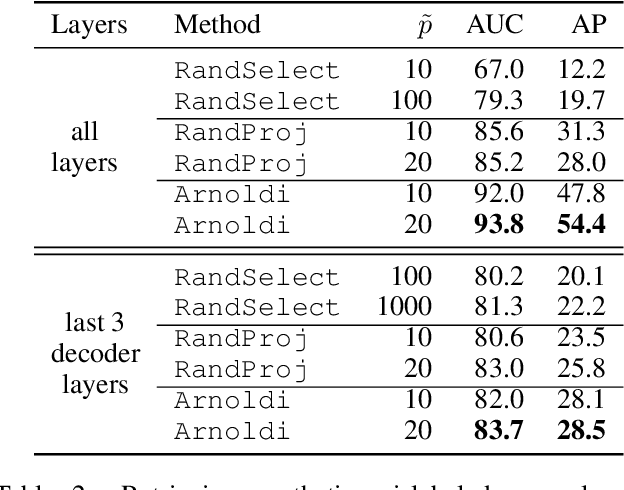
We address efficient calculation of influence functions for tracking predictions back to the training data. We propose and analyze a new approach to speeding up the inverse Hessian calculation based on Arnoldi iteration. With this improvement, we achieve, to the best of our knowledge, the first successful implementation of influence functions that scales to full-size (language and vision) Transformer models with several hundreds of millions of parameters. We evaluate our approach on image classification and sequence-to-sequence tasks with tens to a hundred of millions of training examples. Our code will be available at https://github.com/google-research/jax-influence.
Distributed Function Minimization in Apache Spark
Sep 17, 2019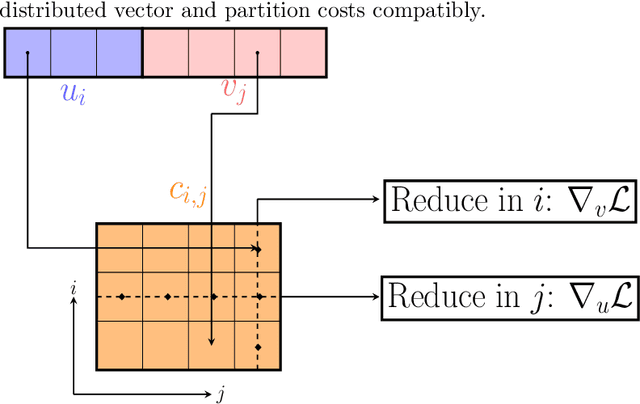
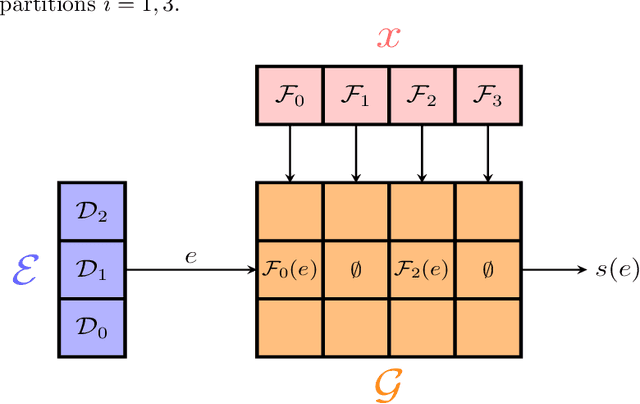
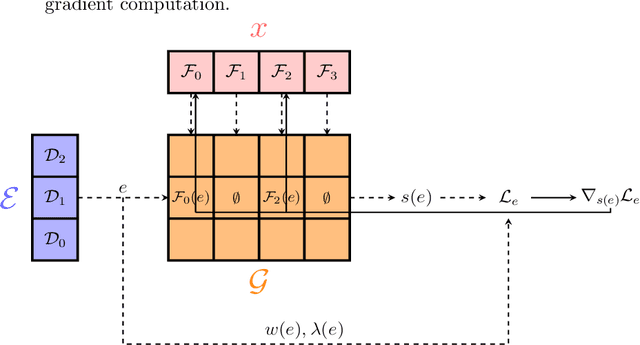

We report on an open-source implementation for distributed function minimization on top of Apache Spark by using gradient and quasi-Newton methods. We show-case it with an application to Optimal Transport and some scalability tests on classification and regression problems.
Learning to Transport with Neural Networks
Aug 04, 2019

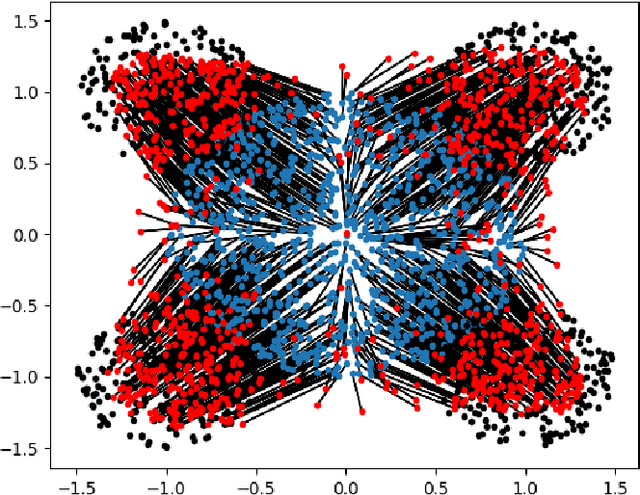
We compare several approaches to learn an Optimal Map, represented as a neural network, between probability distributions. The approaches fall into two categories: ``Heuristics'' and approaches with a more sound mathematical justification, motivated by the dual of the Kantorovitch problem. Among the algorithms we consider a novel approach involving dynamic flows and reductions of Optimal Transport to supervised learning.
Optimality of the final model found via Stochastic Gradient Descent
Oct 22, 2018We study convergence properties of Stochastic Gradient Descent (SGD) for convex objectives without assumptions on smoothness or strict convexity. We consider the question of establishing that with high probability the objective evaluated at the candidate minimizer returned by SGD is close to the minimal value of the objective. We compare this result concerning the final candidate minimzer (i.e. the final model parameters learned after all gradient steps) to the online learning techniques of [Zin03] that take a rolling average of the model parameters at the different steps of SGD.