 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Fairness of Chest X-ray Classifiers
Paper and Code
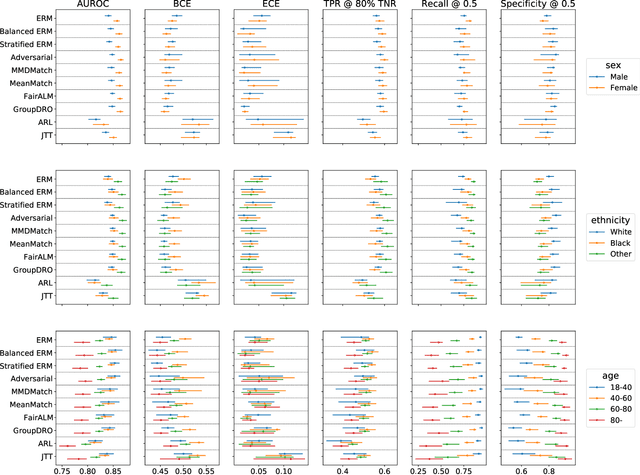
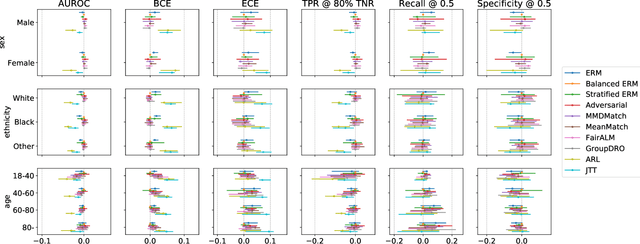
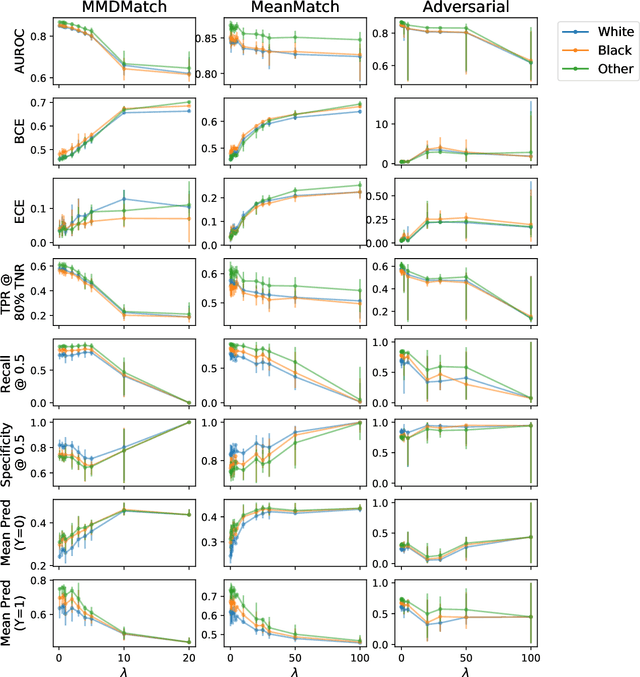
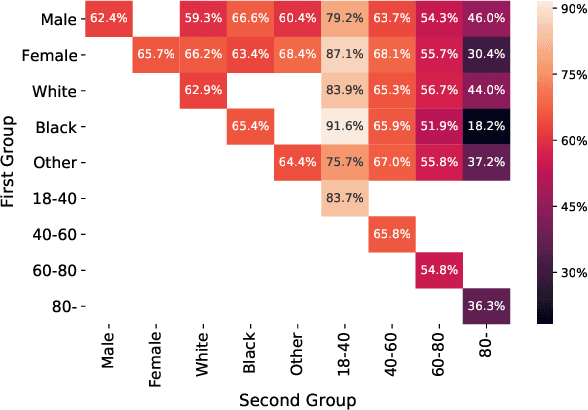
Deep learning models have reached or surpassed human-level performance in the field of medical imaging, especially in disease diagnosis using chest x-rays. However, prior work has found that such classifiers can exhibit biases in the form of gaps in predictive performance across protected groups. In this paper, we question whether striving to achieve zero disparities in predictive performance (i.e. group fairness) is the appropriate fairness definition in the clinical setting, over minimax fairness, which focuses on maximizing the performance of the worst-case group. We benchmark the performance of nine methods in improving classifier fairness across these two definitions. We find, consistent with prior work on non-clinical data, that methods which strive to achieve better worst-group performance do not outperform simple data balancing. We also find that methods which achieve group fairness do so by worsening performance for all groups. In light of these results, we discuss the utility of fairness definitions in the clinical setting, advocating for an investigation of the bias-inducing mechanisms in the underlying data generating process whenever possible.