 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndividual predictions matter: Assessing the effect of data ordering in training fine-tuned CNNs for medical imaging
Dec 08, 2019
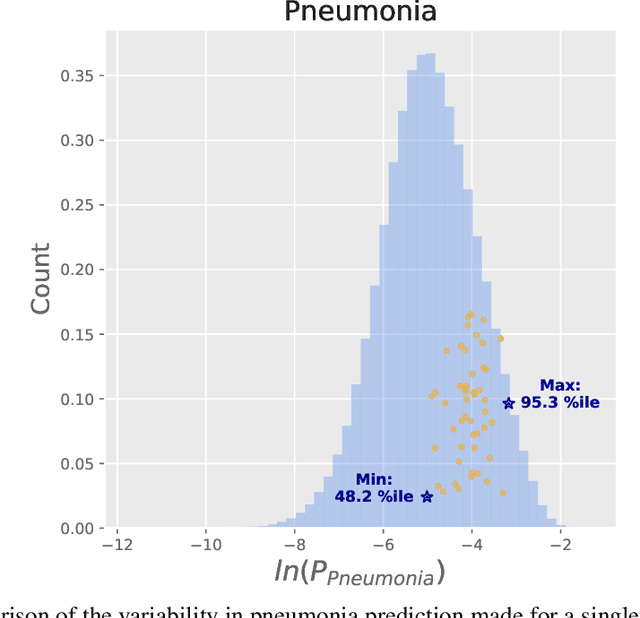
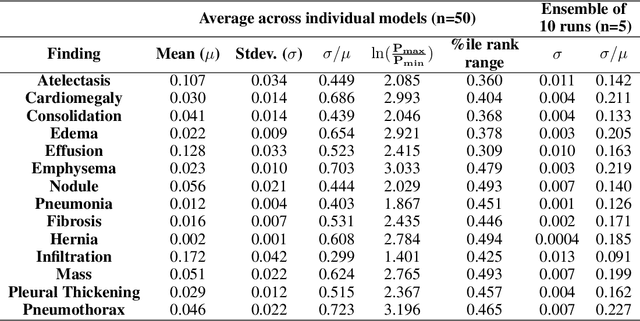
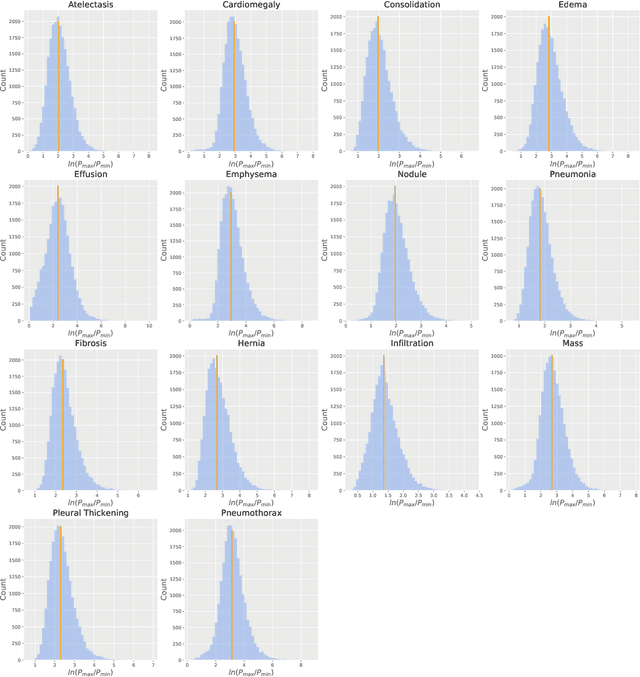
We reproduced the results of CheXNet with fixed hyperparameters and 50 different random seeds to identify 14 finding in chest radiographs (x-rays). Because CheXNet fine-tunes a pre-trained DenseNet, the random seed affects the ordering of the batches of training data but not the initialized model weights. We found substantial variability in predictions for the same radiograph across model runs (mean ln[(maximum probability)/(minimum probability)] 2.45, coefficient of variation 0.543). This individual radiograph-level variability was not fully reflected in the variability of AUC on a large test set. Averaging predictions from 10 models reduced variability by nearly 70% (mean coefficient of variation from 0.543 to 0.169, t-test 15.96, p-value < 0.0001). We encourage researchers to be aware of the potential variability of CNNs and ensemble predictions from multiple models to minimize the effect this variability may have on the care of individual patients when these models are deployed clinically.
Deep Learning Predicts Hip Fracture using Confounding Patient and Healthcare Variables
Nov 08, 2018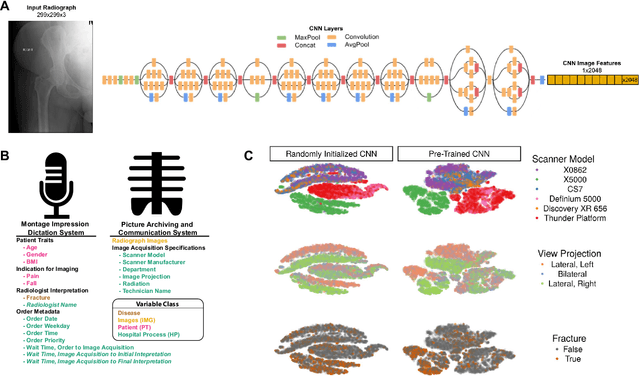
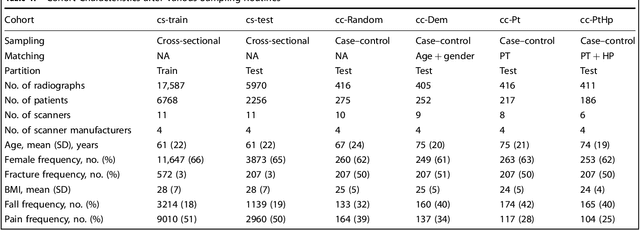
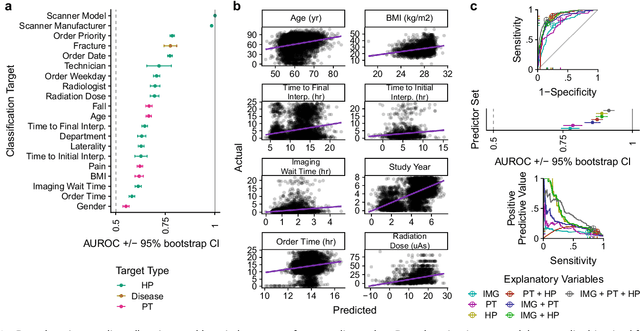
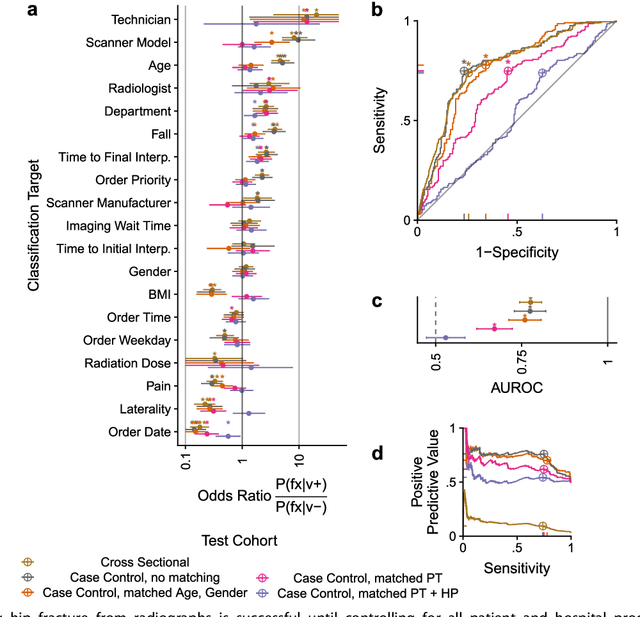
Hip fractures are a leading cause of death and disability among older adults. Hip fractures are also the most commonly missed diagnosis on pelvic radiographs. Computer-Aided Diagnosis (CAD) algorithms have shown promise for helping radiologists detect fractures, but the image features underpinning their predictions are notoriously difficult to understand. In this study, we trained deep learning models on 17,587 radiographs to classify fracture, five patient traits, and 14 hospital process variables. All 20 variables could be predicted from a radiograph (p < 0.05), with the best performances on scanner model (AUC=1.00), scanner brand (AUC=0.98), and whether the order was marked "priority" (AUC=0.79). Fracture was predicted moderately well from the image (AUC=0.78) and better when combining image features with patient data (AUC=0.86, p=2e-9) or patient data plus hospital process features (AUC=0.91, p=1e-21). The model performance on a test set with matched patient variables was significantly lower than a random test set (AUC=0.67, p=0.003); and when the test set was matched on patient and image acquisition variables, the model performed randomly (AUC=0.52, 95% CI 0.46-0.58), indicating that these variables were the main source of the model's predictive ability overall. We also used Naive Bayes to combine evidence from image models with patient and hospital data and found their inclusion improved performance, but that this approach was nevertheless inferior to directly modeling all variables. If CAD algorithms are inexplicably leveraging patient and process variables in their predictions, it is unclear how radiologists should interpret their predictions in the context of other known patient data. Further research is needed to illuminate deep learning decision processes so that computers and clinicians can effectively cooperate.
Confounding variables can degrade generalization performance of radiological deep learning models
Jul 13, 2018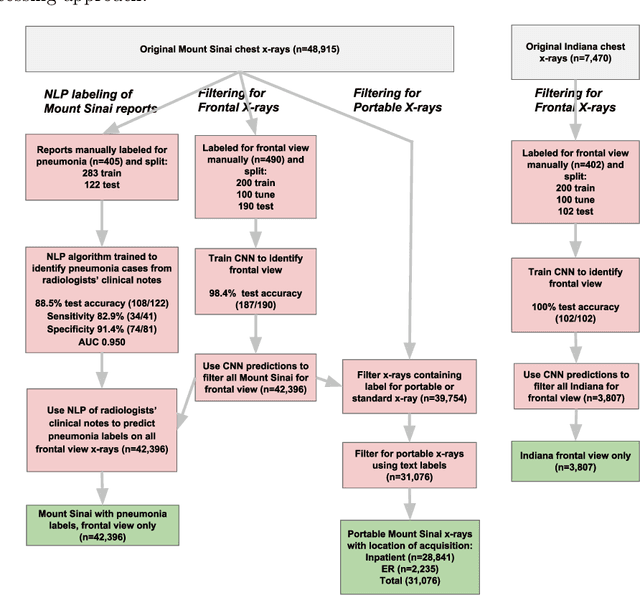
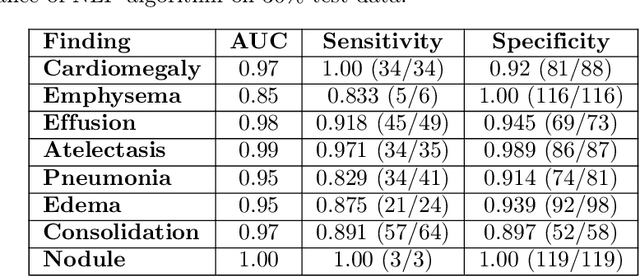
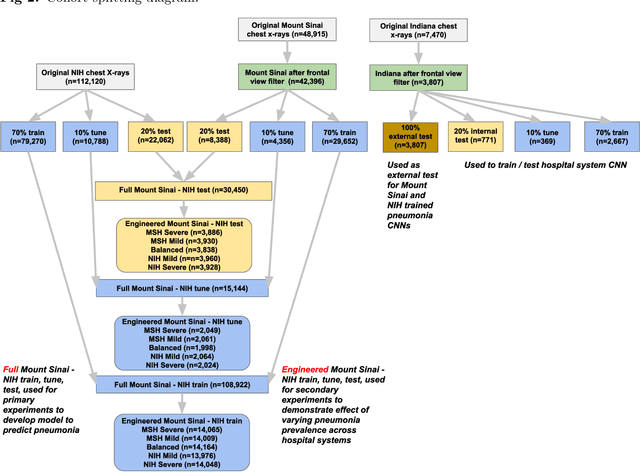
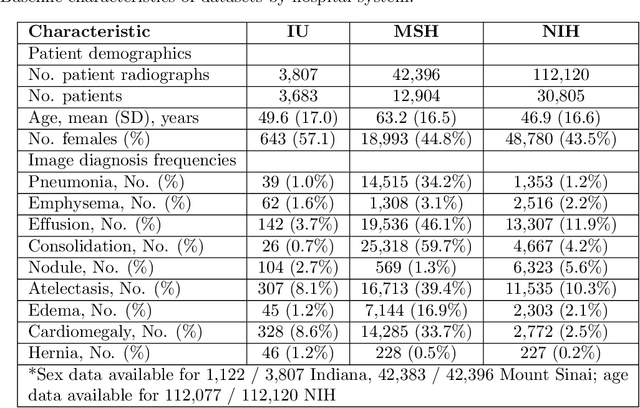
Early results in using convolutional neural networks (CNNs) on x-rays to diagnose disease have been promising, but it has not yet been shown that models trained on x-rays from one hospital or one group of hospitals will work equally well at different hospitals. Before these tools are used for computer-aided diagnosis in real-world clinical settings, we must verify their ability to generalize across a variety of hospital systems. A cross-sectional design was used to train and evaluate pneumonia screening CNNs on 158,323 chest x-rays from NIH (n=112,120 from 30,805 patients), Mount Sinai (42,396 from 12,904 patients), and Indiana (n=3,807 from 3,683 patients). In 3 / 5 natural comparisons, performance on chest x-rays from outside hospitals was significantly lower than on held-out x-rays from the original hospital systems. CNNs were able to detect where an x-ray was acquired (hospital system, hospital department) with extremely high accuracy and calibrate predictions accordingly. The performance of CNNs in diagnosing diseases on x-rays may reflect not only their ability to identify disease-specific imaging findings on x-rays, but also their ability to exploit confounding information. Estimates of CNN performance based on test data from hospital systems used for model training may overstate their likely real-world performance.