Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Stochastic Finite-State Word-Segmentation Algorithm for Chinese
May 05, 1994
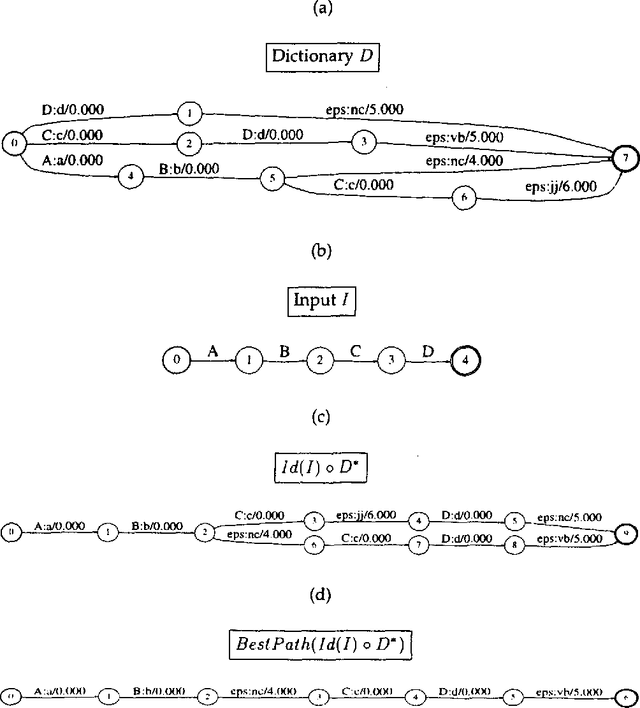
We present a stochastic finite-state model for segmenting Chinese text into dictionary entries and productively derived words, and providing pronunciations for these words; the method incorporates a class-based model in its treatment of personal names. We also evaluate the system's performance, taking into account the fact that people often do not agree on a single segmentation.
* in Proceedings of ACL 94
* To appear in Proceedings of ACL-94
* To appear in Proceedings of ACL-94
Via