 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge(Re)construing Meaning in NLP
May 18, 2020Human speakers have an extensive toolkit of ways to express themselves. In this paper, we engage with an idea largely absent from discussions of meaning in natural language understanding--namely, that the way something is expressed reflects different ways of conceptualizing or construing the information being conveyed. We first define this phenomenon more precisely, drawing on considerable prior work in theoretical cognitive semantics and psycholinguistics. We then survey some dimensions of construed meaning and show how insights from construal could inform theoretical and practical work in NLP.
A task in a suit and a tie: paraphrase generation with semantic augmentation
Oct 31, 2018
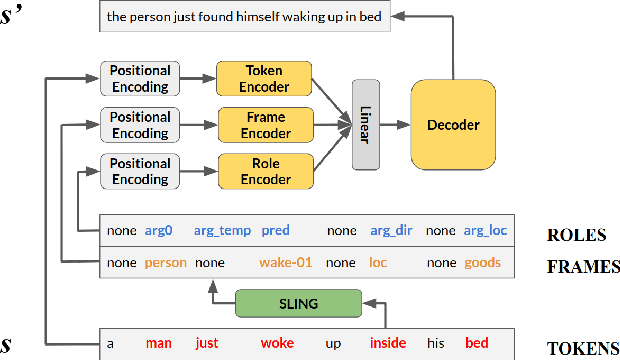

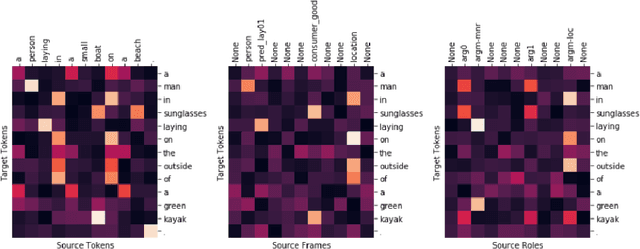
Paraphrasing is rooted in semantics. We show the effectiveness of transformers (Vaswani et al. 2017) for paraphrase generation and further improvements by incorporating PropBank labels via a multi-encoder. Evaluating on MSCOCO and WikiAnswers, we find that transformers are fast and effective, and that semantic augmentation for both transformers and LSTMs leads to sizable 2-3 point gains in BLEU, METEOR and TER. More importantly, we find surprisingly large gains on human evaluations compared to previous models. Nevertheless, manual inspection of generated paraphrases reveals ample room for improvement: even our best model produces human-acceptable paraphrases for only 28% of captions from the CHIA dataset (Sharma et al. 2018), and it fails spectacularly on sentences from Wikipedia. Overall, these results point to the potential for incorporating semantics in the task while highlighting the need for stronger evaluation.
A Stochastic Finite-State Word-Segmentation Algorithm for Chinese
May 05, 1994
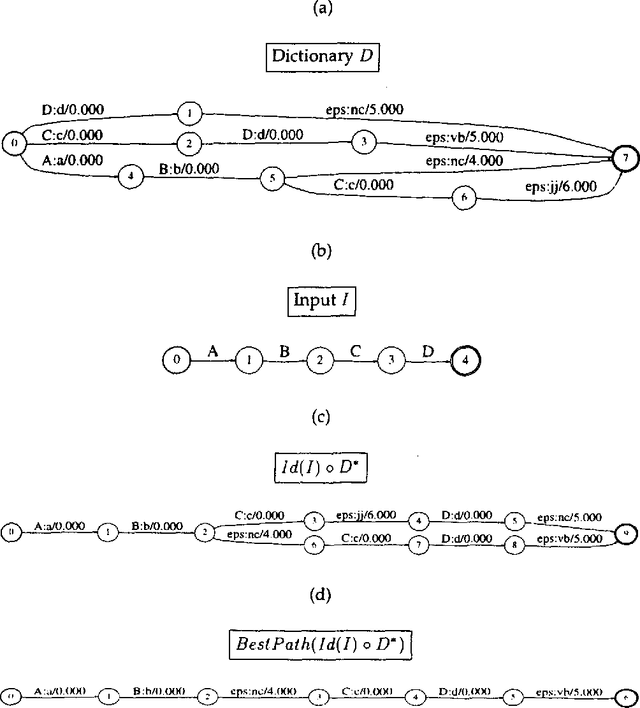
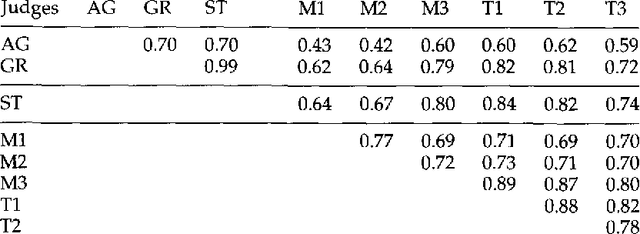
We present a stochastic finite-state model for segmenting Chinese text into dictionary entries and productively derived words, and providing pronunciations for these words; the method incorporates a class-based model in its treatment of personal names. We also evaluate the system's performance, taking into account the fact that people often do not agree on a single segmentation.
* To appear in Proceedings of ACL-94