 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrame Semantic Patterns for Identifying Underreporting of Notifiable Events in Healthcare: The Case of Gender-Based Violence
Oct 30, 2025We introduce a methodology for the identification of notifiable events in the domain of healthcare. The methodology harnesses semantic frames to define fine-grained patterns and search them in unstructured data, namely, open-text fields in e-medical records. We apply the methodology to the problem of underreporting of gender-based violence (GBV) in e-medical records produced during patients' visits to primary care units. A total of eight patterns are defined and searched on a corpus of 21 million sentences in Brazilian Portuguese extracted from e-SUS APS. The results are manually evaluated by linguists and the precision of each pattern measured. Our findings reveal that the methodology effectively identifies reports of violence with a precision of 0.726, confirming its robustness. Designed as a transparent, efficient, low-carbon, and language-agnostic pipeline, the approach can be easily adapted to other health surveillance contexts, contributing to the broader, ethical, and explainable use of NLP in public health systems.
Evaluating the Impact of LLM-Assisted Annotation in a Perspectivized Setting: the Case of FrameNet Annotation
Oct 29, 2025



The use of LLM-based applications as a means to accelerate and/or substitute human labor in the creation of language resources and dataset is a reality. Nonetheless, despite the potential of such tools for linguistic research, comprehensive evaluation of their performance and impact on the creation of annotated datasets, especially under a perspectivized approach to NLP, is still missing. This paper contributes to reduction of this gap by reporting on an extensive evaluation of the (semi-)automatization of FrameNet-like semantic annotation by the use of an LLM-based semantic role labeler. The methodology employed compares annotation time, coverage and diversity in three experimental settings: manual, automatic and semi-automatic annotation. Results show that the hybrid, semi-automatic annotation setting leads to increased frame diversity and similar annotation coverage, when compared to the human-only setting, while the automatic setting performs considerably worse in all metrics, except for annotation time.
CaMMT: Benchmarking Culturally Aware Multimodal Machine Translation
May 30, 2025



Cultural content poses challenges for machine translation systems due to the differences in conceptualizations between cultures, where language alone may fail to convey sufficient context to capture region-specific meanings. In this work, we investigate whether images can act as cultural context in multimodal translation. We introduce CaMMT, a human-curated benchmark of over 5,800 triples of images along with parallel captions in English and regional languages. Using this dataset, we evaluate five Vision Language Models (VLMs) in text-only and text+image settings. Through automatic and human evaluations, we find that visual context generally improves translation quality, especially in handling Culturally-Specific Items (CSIs), disambiguation, and correct gender usage. By releasing CaMMT, we aim to support broader efforts in building and evaluating multimodal translation systems that are better aligned with cultural nuance and regional variation.
FutureVision: A methodology for the investigation of future cognition
Feb 03, 2025



This paper presents a methodology combining multimodal semantic analysis with an eye-tracking experimental protocol to investigate the cognitive effort involved in understanding the communication of future scenarios. To demonstrate the methodology, we conduct a pilot study examining how visual fixation patterns vary during the evaluation of valence and counterfactuality in fictional ad pieces describing futuristic scenarios, using a portable eye tracker. Participants eye movements are recorded while evaluating the stimuli and describing them to a conversation partner. Gaze patterns are analyzed alongside semantic representations of the stimuli and participants descriptions, constructed from a frame semantic annotation of both linguistic and visual modalities. Preliminary results show that far-future and pessimistic scenarios are associated with longer fixations and more erratic saccades, supporting the hypothesis that fractures in the base spaces underlying the interpretation of future scenarios increase cognitive load for comprehenders.
CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
Jun 10, 2024



Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 28 countries on four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Lutma: a Frame-Making Tool for Collaborative FrameNet Development
May 24, 2022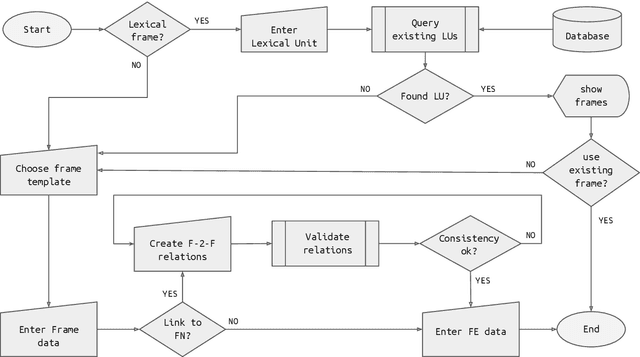
This paper presents Lutma, a collaborative, semi-constrained, tutorial-based tool for contributing frames and lexical units to the Global FrameNet initiative. The tool parameterizes the process of frame creation, avoiding consistency violations and promoting the integration of frames contributed by the community with existing frames. Lutma is structured in a wizard-like fashion so as to provide users with text and video tutorials relevant for each step in the frame creation process. We argue that this tool will allow for a sensible expansion of FrameNet coverage in terms of both languages and cultural perspectives encoded by them, positioning frames as a viable alternative for representing perspective in language models.
Charon: a FrameNet Annotation Tool for Multimodal Corpora
May 24, 2022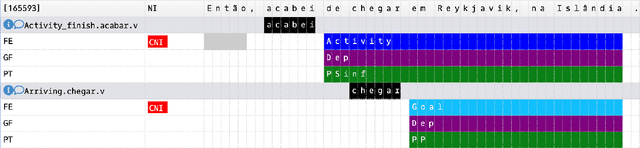
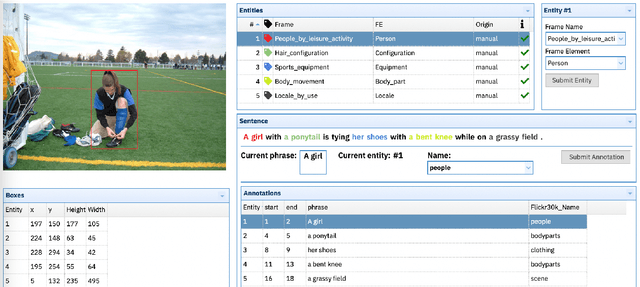
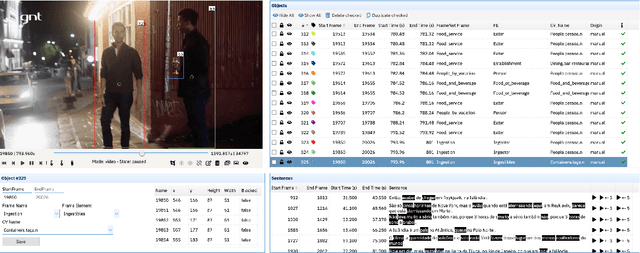
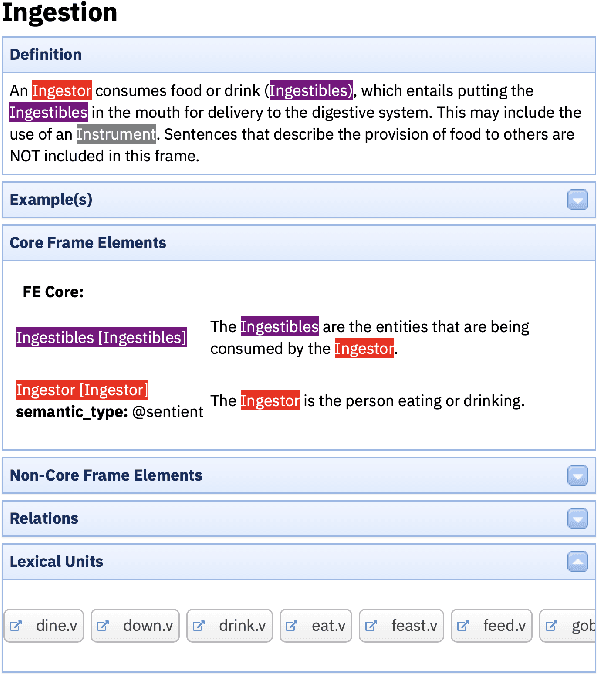
This paper presents Charon, a web tool for annotating multimodal corpora with FrameNet categories. Annotation can be made for corpora containing both static images and video sequences paired - or not - with text sequences. The pipeline features, besides the annotation interface, corpus import and pre-processing tools.
The Case for Perspective in Multimodal Datasets
May 22, 2022
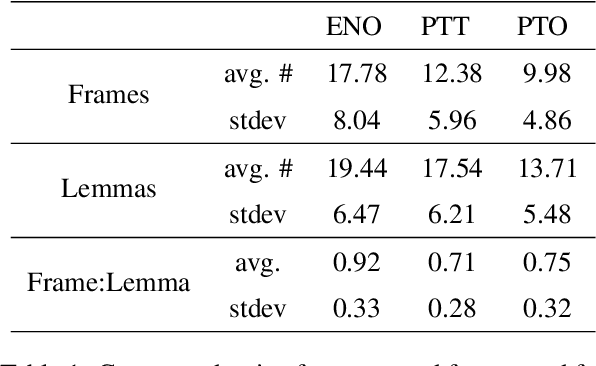
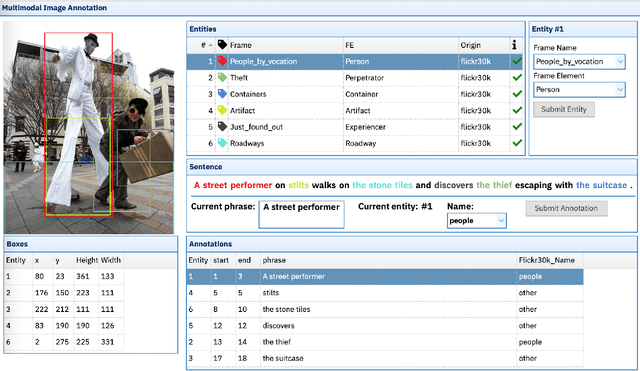
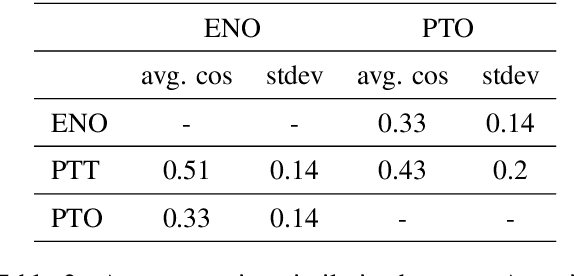
This paper argues in favor of the adoption of annotation practices for multimodal datasets that recognize and represent the inherently perspectivized nature of multimodal communication. To support our claim, we present a set of annotation experiments in which FrameNet annotation is applied to the Multi30k and the Flickr 30k Entities datasets. We assess the cosine similarity between the semantic representations derived from the annotation of both pictures and captions for frames. Our findings indicate that: (i) frame semantic similarity between captions of the same picture produced in different languages is sensitive to whether the caption is a translation of another caption or not, and (ii) picture annotation for semantic frames is sensitive to whether the image is annotated in presence of a caption or not.
Domain Adaptation in Neural Machine Translation using a Qualia-Enriched FrameNet
Feb 21, 2022
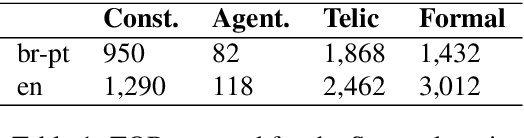

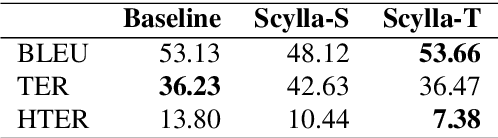
In this paper we present Scylla, a methodology for domain adaptation of Neural Machine Translation (NMT) systems that make use of a multilingual FrameNet enriched with qualia relations as an external knowledge base. Domain adaptation techniques used in NMT usually require fine-tuning and in-domain training data, which may pose difficulties for those working with lesser-resourced languages and may also lead to performance decay of the NMT system for out-of-domain sentences. Scylla does not require fine-tuning of the NMT model, avoiding the risk of model over-fitting and consequent decrease in performance for out-of-domain translations. Two versions of Scylla are presented: one using the source sentence as input, and another one using the target sentence. We evaluate Scylla in comparison to a state-of-the-art commercial NMT system in an experiment in which 50 sentences from the Sports domain are translated from Brazilian Portuguese to English. The two versions of Scylla significantly outperform the baseline commercial system in HTER.