 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFutureVision: A methodology for the investigation of future cognition
Feb 03, 2025



This paper presents a methodology combining multimodal semantic analysis with an eye-tracking experimental protocol to investigate the cognitive effort involved in understanding the communication of future scenarios. To demonstrate the methodology, we conduct a pilot study examining how visual fixation patterns vary during the evaluation of valence and counterfactuality in fictional ad pieces describing futuristic scenarios, using a portable eye tracker. Participants eye movements are recorded while evaluating the stimuli and describing them to a conversation partner. Gaze patterns are analyzed alongside semantic representations of the stimuli and participants descriptions, constructed from a frame semantic annotation of both linguistic and visual modalities. Preliminary results show that far-future and pessimistic scenarios are associated with longer fixations and more erratic saccades, supporting the hypothesis that fractures in the base spaces underlying the interpretation of future scenarios increase cognitive load for comprehenders.
The Case for Perspective in Multimodal Datasets
May 22, 2022
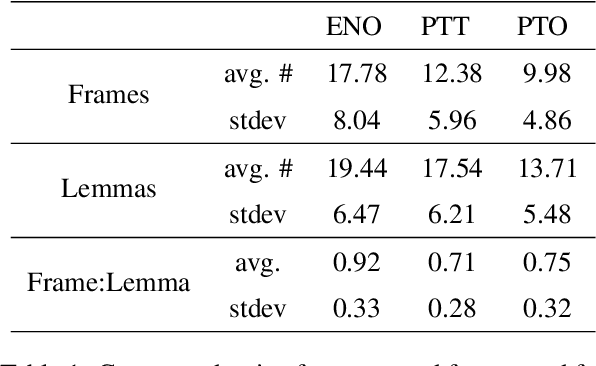
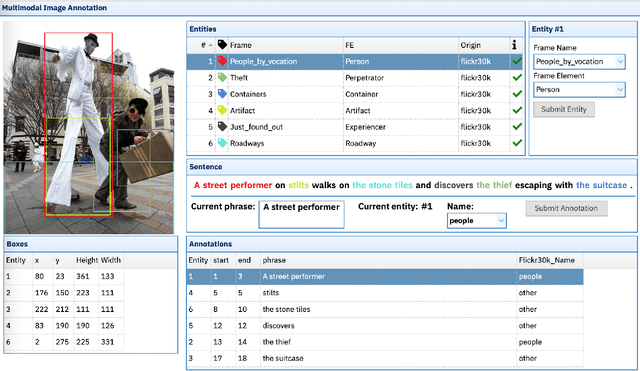
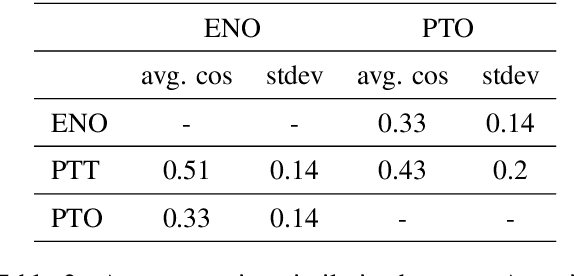
This paper argues in favor of the adoption of annotation practices for multimodal datasets that recognize and represent the inherently perspectivized nature of multimodal communication. To support our claim, we present a set of annotation experiments in which FrameNet annotation is applied to the Multi30k and the Flickr 30k Entities datasets. We assess the cosine similarity between the semantic representations derived from the annotation of both pictures and captions for frames. Our findings indicate that: (i) frame semantic similarity between captions of the same picture produced in different languages is sensitive to whether the caption is a translation of another caption or not, and (ii) picture annotation for semantic frames is sensitive to whether the image is annotated in presence of a caption or not.