 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating FrameNet-Based Semantic Modeling for Gender-Based Violence Detection in Clinical Records
Mar 18, 2026Gender-based violence (GBV) is a major public health issue, with the World Health Organization estimating that one in three women experiences physical or sexual violence by an intimate partner during her lifetime. In Brazil, although healthcare professionals are legally required to report such cases, underreporting remains significant due to difficulties in identifying abuse and limited integration between public information systems. This study investigates whether FrameNet-based semantic annotation of open-text fields in electronic medical records can support the identification of patterns of GBV. We compare the performance of an SVM classifier for GBV cases trained on (1) frame-annotated text, (2) annotated text combined with parameterized data, and (3) parameterized data alone. Quantitative and qualitative analyses show that models incorporating semantic annotation outperform categorical models, achieving over 0.3 improvement in F1 score and demonstrating that domain-specific semantic representations provide meaningful signals beyond structured demographic data. The findings support the hypothesis that semantic analysis of clinical narratives can enhance early identification strategies and support more informed public health interventions.
Frame Semantic Patterns for Identifying Underreporting of Notifiable Events in Healthcare: The Case of Gender-Based Violence
Oct 30, 2025We introduce a methodology for the identification of notifiable events in the domain of healthcare. The methodology harnesses semantic frames to define fine-grained patterns and search them in unstructured data, namely, open-text fields in e-medical records. We apply the methodology to the problem of underreporting of gender-based violence (GBV) in e-medical records produced during patients' visits to primary care units. A total of eight patterns are defined and searched on a corpus of 21 million sentences in Brazilian Portuguese extracted from e-SUS APS. The results are manually evaluated by linguists and the precision of each pattern measured. Our findings reveal that the methodology effectively identifies reports of violence with a precision of 0.726, confirming its robustness. Designed as a transparent, efficient, low-carbon, and language-agnostic pipeline, the approach can be easily adapted to other health surveillance contexts, contributing to the broader, ethical, and explainable use of NLP in public health systems.
FutureVision: A methodology for the investigation of future cognition
Feb 03, 2025



This paper presents a methodology combining multimodal semantic analysis with an eye-tracking experimental protocol to investigate the cognitive effort involved in understanding the communication of future scenarios. To demonstrate the methodology, we conduct a pilot study examining how visual fixation patterns vary during the evaluation of valence and counterfactuality in fictional ad pieces describing futuristic scenarios, using a portable eye tracker. Participants eye movements are recorded while evaluating the stimuli and describing them to a conversation partner. Gaze patterns are analyzed alongside semantic representations of the stimuli and participants descriptions, constructed from a frame semantic annotation of both linguistic and visual modalities. Preliminary results show that far-future and pessimistic scenarios are associated with longer fixations and more erratic saccades, supporting the hypothesis that fractures in the base spaces underlying the interpretation of future scenarios increase cognitive load for comprehenders.
CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
Jun 10, 2024



Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 28 countries on four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.
Lutma: a Frame-Making Tool for Collaborative FrameNet Development
May 24, 2022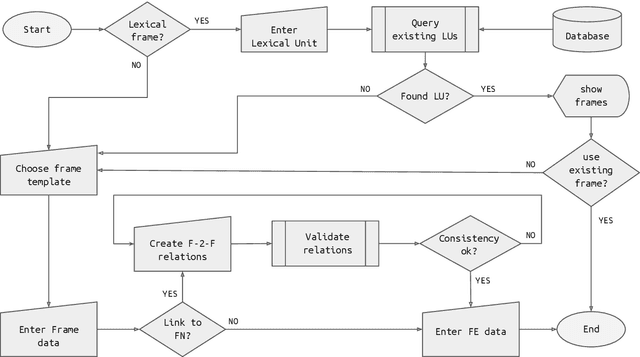
This paper presents Lutma, a collaborative, semi-constrained, tutorial-based tool for contributing frames and lexical units to the Global FrameNet initiative. The tool parameterizes the process of frame creation, avoiding consistency violations and promoting the integration of frames contributed by the community with existing frames. Lutma is structured in a wizard-like fashion so as to provide users with text and video tutorials relevant for each step in the frame creation process. We argue that this tool will allow for a sensible expansion of FrameNet coverage in terms of both languages and cultural perspectives encoded by them, positioning frames as a viable alternative for representing perspective in language models.
Charon: a FrameNet Annotation Tool for Multimodal Corpora
May 24, 2022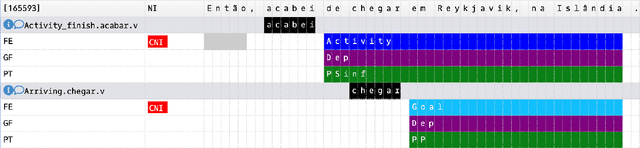
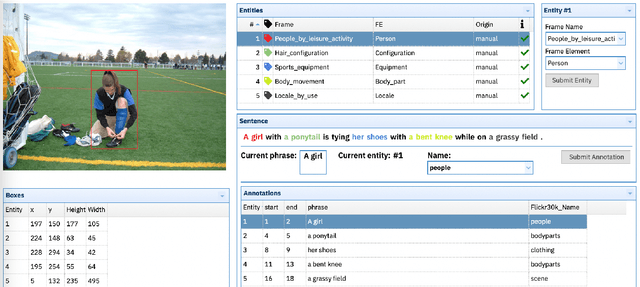
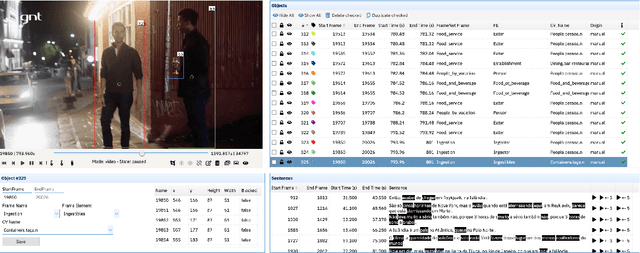
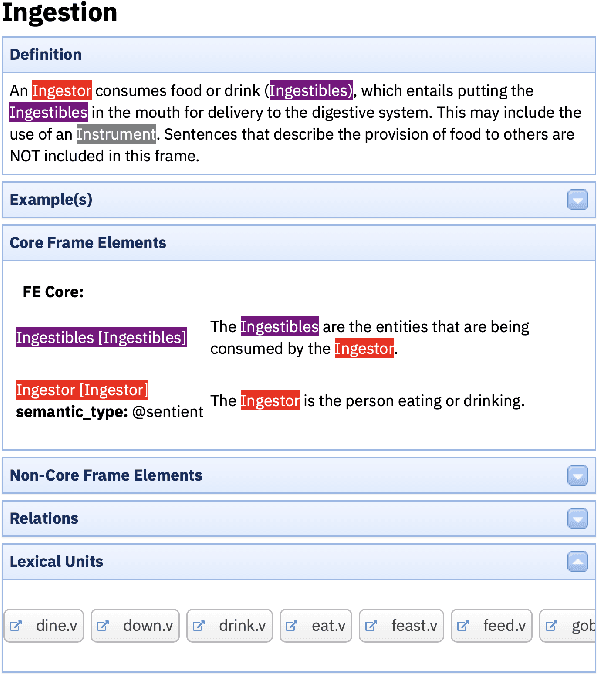
This paper presents Charon, a web tool for annotating multimodal corpora with FrameNet categories. Annotation can be made for corpora containing both static images and video sequences paired - or not - with text sequences. The pipeline features, besides the annotation interface, corpus import and pre-processing tools.
The Case for Perspective in Multimodal Datasets
May 22, 2022
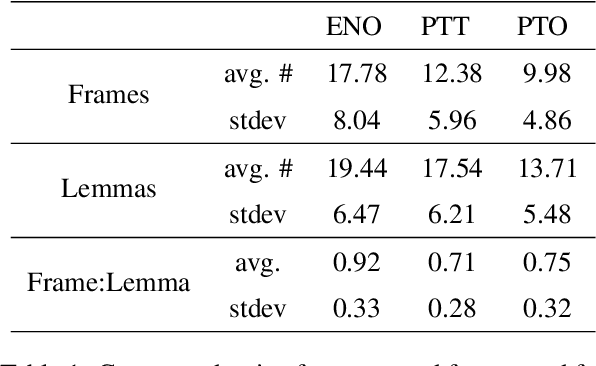
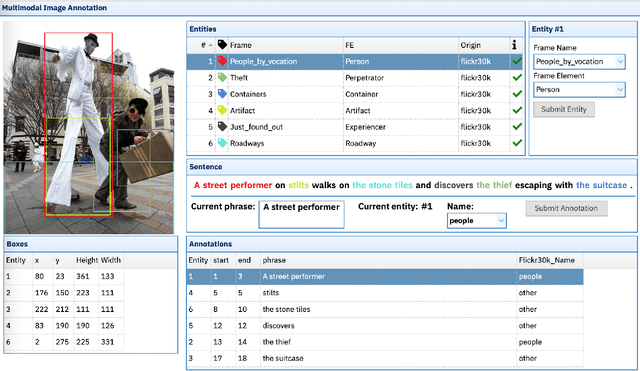
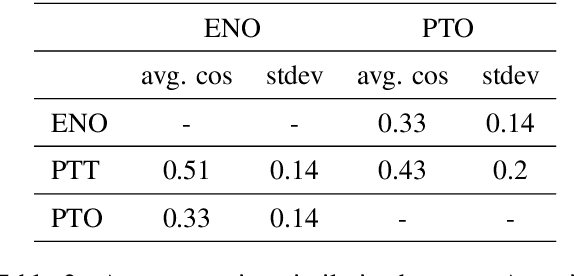
This paper argues in favor of the adoption of annotation practices for multimodal datasets that recognize and represent the inherently perspectivized nature of multimodal communication. To support our claim, we present a set of annotation experiments in which FrameNet annotation is applied to the Multi30k and the Flickr 30k Entities datasets. We assess the cosine similarity between the semantic representations derived from the annotation of both pictures and captions for frames. Our findings indicate that: (i) frame semantic similarity between captions of the same picture produced in different languages is sensitive to whether the caption is a translation of another caption or not, and (ii) picture annotation for semantic frames is sensitive to whether the image is annotated in presence of a caption or not.