 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLutma: a Frame-Making Tool for Collaborative FrameNet Development
May 24, 2022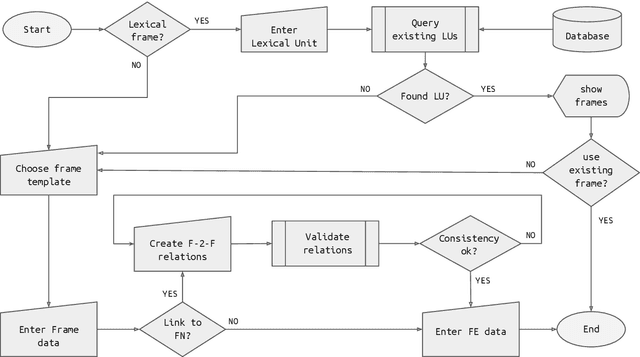
This paper presents Lutma, a collaborative, semi-constrained, tutorial-based tool for contributing frames and lexical units to the Global FrameNet initiative. The tool parameterizes the process of frame creation, avoiding consistency violations and promoting the integration of frames contributed by the community with existing frames. Lutma is structured in a wizard-like fashion so as to provide users with text and video tutorials relevant for each step in the frame creation process. We argue that this tool will allow for a sensible expansion of FrameNet coverage in terms of both languages and cultural perspectives encoded by them, positioning frames as a viable alternative for representing perspective in language models.
The Case for Perspective in Multimodal Datasets
May 22, 2022
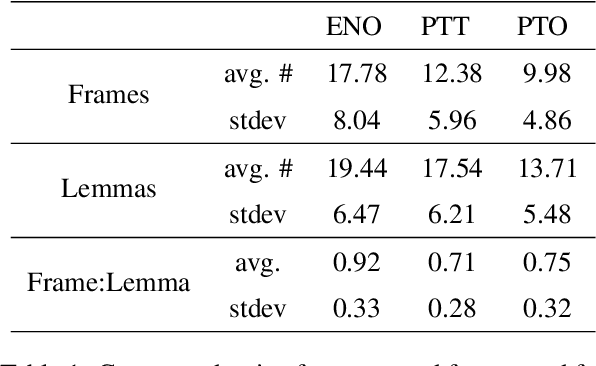
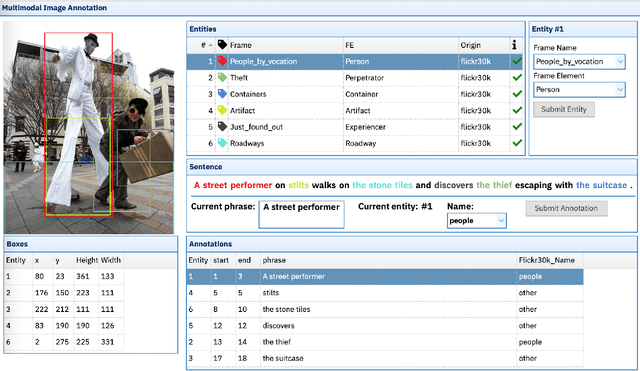
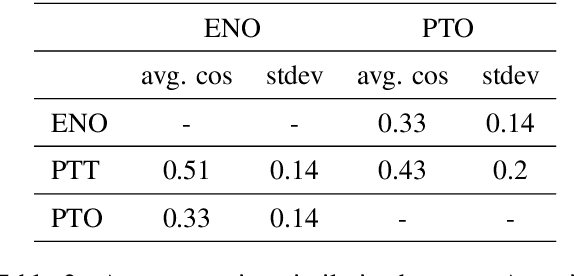
This paper argues in favor of the adoption of annotation practices for multimodal datasets that recognize and represent the inherently perspectivized nature of multimodal communication. To support our claim, we present a set of annotation experiments in which FrameNet annotation is applied to the Multi30k and the Flickr 30k Entities datasets. We assess the cosine similarity between the semantic representations derived from the annotation of both pictures and captions for frames. Our findings indicate that: (i) frame semantic similarity between captions of the same picture produced in different languages is sensitive to whether the caption is a translation of another caption or not, and (ii) picture annotation for semantic frames is sensitive to whether the image is annotated in presence of a caption or not.
Domain Adaptation in Neural Machine Translation using a Qualia-Enriched FrameNet
Feb 21, 2022
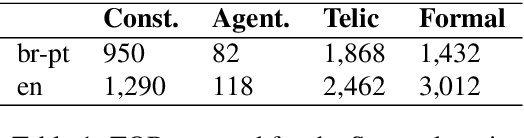

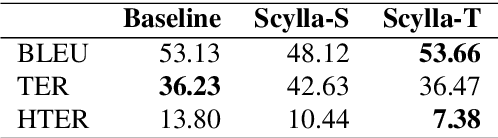
In this paper we present Scylla, a methodology for domain adaptation of Neural Machine Translation (NMT) systems that make use of a multilingual FrameNet enriched with qualia relations as an external knowledge base. Domain adaptation techniques used in NMT usually require fine-tuning and in-domain training data, which may pose difficulties for those working with lesser-resourced languages and may also lead to performance decay of the NMT system for out-of-domain sentences. Scylla does not require fine-tuning of the NMT model, avoiding the risk of model over-fitting and consequent decrease in performance for out-of-domain translations. Two versions of Scylla are presented: one using the source sentence as input, and another one using the target sentence. We evaluate Scylla in comparison to a state-of-the-art commercial NMT system in an experiment in which 50 sentences from the Sports domain are translated from Brazilian Portuguese to English. The two versions of Scylla significantly outperform the baseline commercial system in HTER.