 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMA-UNet: A Multi-Modal Asymmetric UNet Architecture for Infrared and Visible Image Fusion
Apr 27, 2024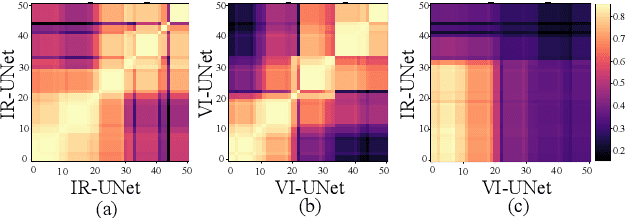
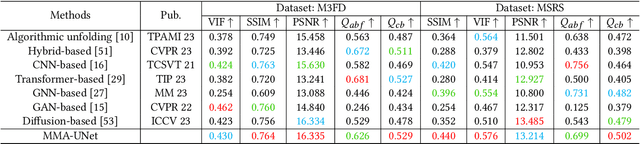
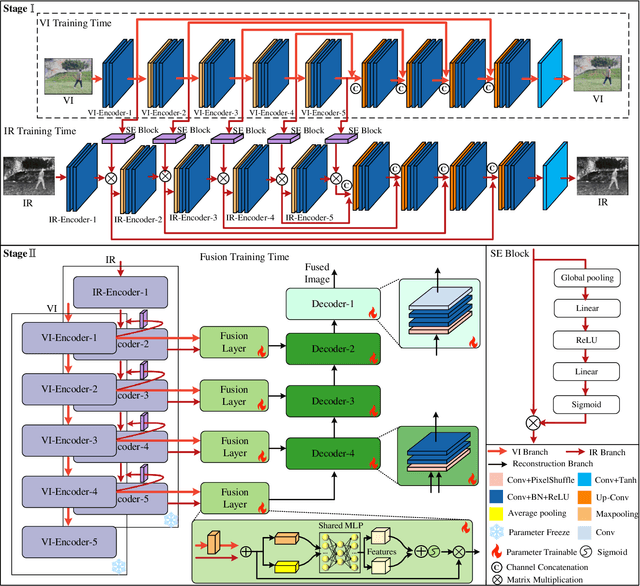
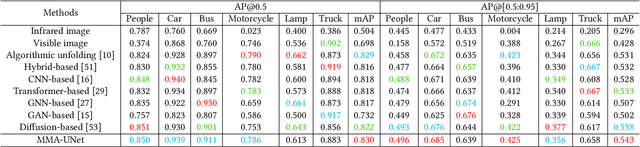
Multi-modal image fusion (MMIF) maps useful information from various modalities into the same representation space, thereby producing an informative fused image. However, the existing fusion algorithms tend to symmetrically fuse the multi-modal images, causing the loss of shallow information or bias towards a single modality in certain regions of the fusion results. In this study, we analyzed the spatial distribution differences of information in different modalities and proved that encoding features within the same network is not conducive to achieving simultaneous deep feature space alignment for multi-modal images. To overcome this issue, a Multi-Modal Asymmetric UNet (MMA-UNet) was proposed. We separately trained specialized feature encoders for different modal and implemented a cross-scale fusion strategy to maintain the features from different modalities within the same representation space, ensuring a balanced information fusion process. Furthermore, extensive fusion and downstream task experiments were conducted to demonstrate the efficiency of MMA-UNet in fusing infrared and visible image information, producing visually natural and semantically rich fusion results. Its performance surpasses that of the state-of-the-art comparison fusion methods.