 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteraction-Guided Two-Branch Image Dehazing Network
Oct 14, 2024
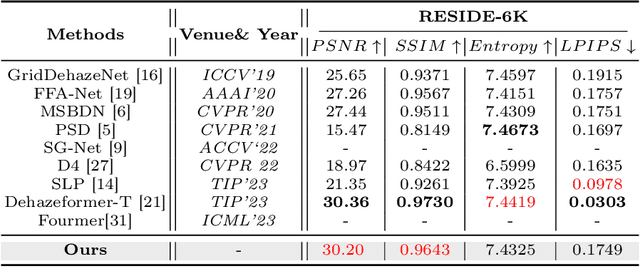
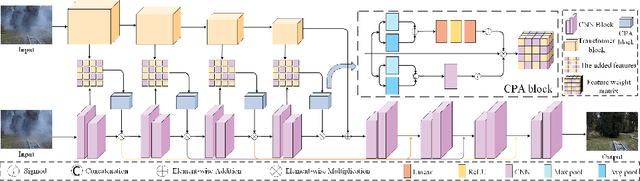
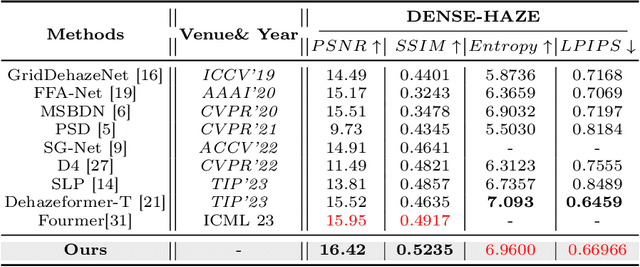
Image dehazing aims to restore clean images from hazy ones. Convolutional Neural Networks (CNNs) and Transformers have demonstrated exceptional performance in local and global feature extraction, respectively, and currently represent the two mainstream frameworks in image dehazing. In this paper, we propose a novel dual-branch image dehazing framework that guides CNN and Transformer components interactively. We reconsider the complementary characteristics of CNNs and Transformers by leveraging the differential relationships between global and local features for interactive guidance. This approach enables the capture of local feature positions through global attention maps, allowing the CNN to focus solely on feature information at effective positions. The single-branch Transformer design ensures the network's global information recovery capability. Extensive experiments demonstrate that our proposed method yields competitive qualitative and quantitative evaluation performance on both synthetic and real public datasets. Codes are available at https://github.com/Feecuin/Two-Branch-Dehazing
MMA-UNet: A Multi-Modal Asymmetric UNet Architecture for Infrared and Visible Image Fusion
Apr 27, 2024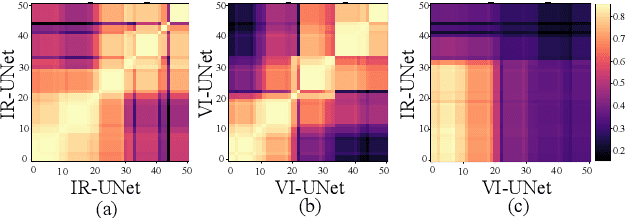
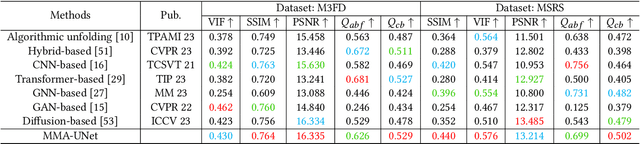
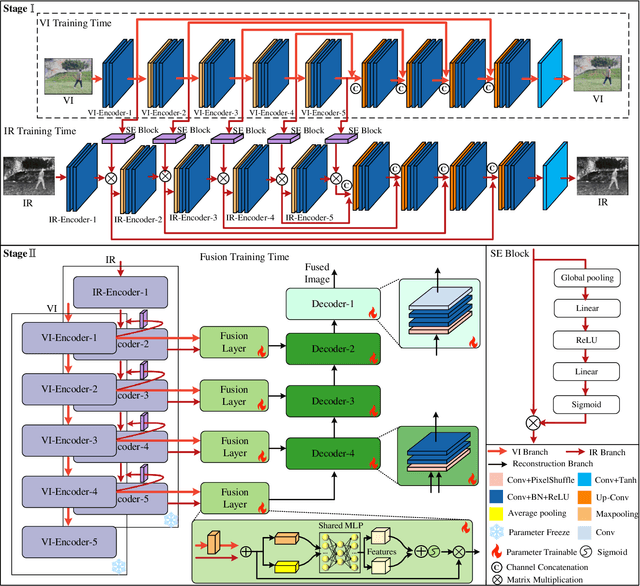
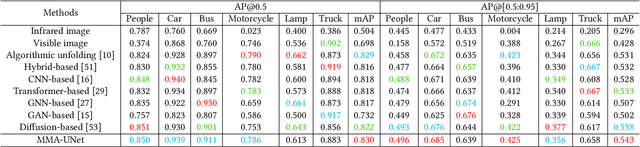
Multi-modal image fusion (MMIF) maps useful information from various modalities into the same representation space, thereby producing an informative fused image. However, the existing fusion algorithms tend to symmetrically fuse the multi-modal images, causing the loss of shallow information or bias towards a single modality in certain regions of the fusion results. In this study, we analyzed the spatial distribution differences of information in different modalities and proved that encoding features within the same network is not conducive to achieving simultaneous deep feature space alignment for multi-modal images. To overcome this issue, a Multi-Modal Asymmetric UNet (MMA-UNet) was proposed. We separately trained specialized feature encoders for different modal and implemented a cross-scale fusion strategy to maintain the features from different modalities within the same representation space, ensuring a balanced information fusion process. Furthermore, extensive fusion and downstream task experiments were conducted to demonstrate the efficiency of MMA-UNet in fusing infrared and visible image information, producing visually natural and semantically rich fusion results. Its performance surpasses that of the state-of-the-art comparison fusion methods.