 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Speech Editing Detection and Content Localization via Prior-Enhanced Audio LLMs
Jan 29, 2026Speech editing achieves semantic inversion by performing fine-grained segment-level manipulation on original utterances, while preserving global perceptual naturalness. Existing detection studies mainly focus on manually edited speech with explicit splicing artifacts, and therefore struggle to cope with emerging end-to-end neural speech editing techniques that generate seamless acoustic transitions. To address this challenge, we first construct a large-scale bilingual dataset, AiEdit, which leverages large language models to drive precise semantic tampering logic and employs multiple advanced neural speech editing methods for data synthesis, thereby filling the gap of high-quality speech editing datasets. Building upon this foundation, we propose PELM (Prior-Enhanced Audio Large Language Model), the first large-model framework that unifies speech editing detection and content localization by formulating them as an audio question answering task. To mitigate the inherent forgery bias and semantic-priority bias observed in existing audio large models, PELM incorporates word-level probability priors to provide explicit acoustic cues, and further designs a centroid-aggregation-based acoustic consistency perception loss to explicitly enforce the modeling of subtle local distribution anomalies. Extensive experimental results demonstrate that PELM significantly outperforms state-of-the-art methods on both the HumanEdit and AiEdit datasets, achieving equal error rates (EER) of 0.57\% and 9.28\% (localization), respectively.
Audio-visual Event Localization on Portrait Mode Short Videos
Apr 09, 2025Audio-visual event localization (AVEL) plays a critical role in multimodal scene understanding. While existing datasets for AVEL predominantly comprise landscape-oriented long videos with clean and simple audio context, short videos have become the primary format of online video content due to the the proliferation of smartphones. Short videos are characterized by portrait-oriented framing and layered audio compositions (e.g., overlapping sound effects, voiceovers, and music), which brings unique challenges unaddressed by conventional methods. To this end, we introduce AVE-PM, the first AVEL dataset specifically designed for portrait mode short videos, comprising 25,335 clips that span 86 fine-grained categories with frame-level annotations. Beyond dataset creation, our empirical analysis shows that state-of-the-art AVEL methods suffer an average 18.66% performance drop during cross-mode evaluation. Further analysis reveals two key challenges of different video formats: 1) spatial bias from portrait-oriented framing introduces distinct domain priors, and 2) noisy audio composition compromise the reliability of audio modality. To address these issues, we investigate optimal preprocessing recipes and the impact of background music for AVEL on portrait mode videos. Experiments show that these methods can still benefit from tailored preprocessing and specialized model design, thus achieving improved performance. This work provides both a foundational benchmark and actionable insights for advancing AVEL research in the era of mobile-centric video content. Dataset and code will be released.
Forecasting Spatio-Temporal Renewable Scenarios: a Deep Generative Approach
Mar 13, 2019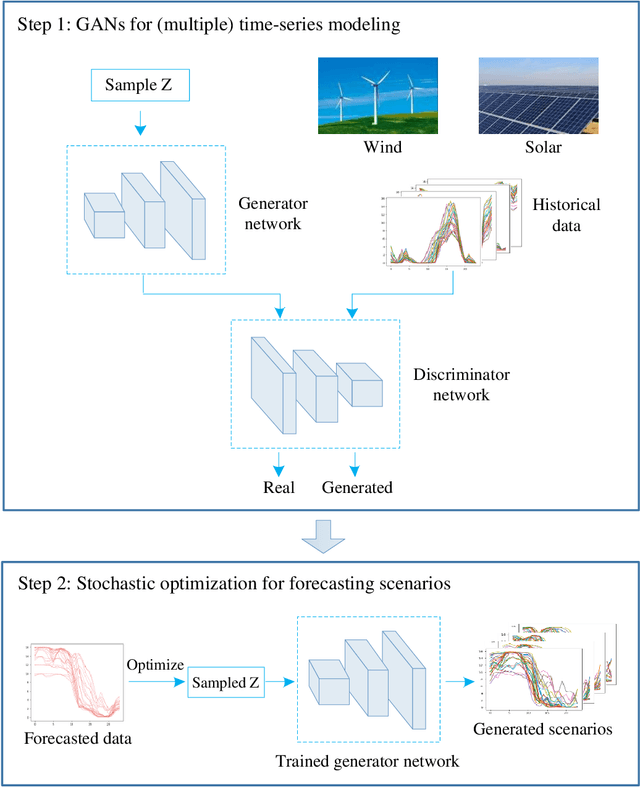



The operation and planning of large-scale power systems are becoming more challenging with the increasing penetration of stochastic renewable generation. In order to minimize the decision risks in power systems with large amount of renewable resources, there is a growing need to model the short-term generation uncertainty. By producing a group of possible future realizations for certain set of renewable generation plants, scenario approach has become one popular way for renewables uncertainty modeling. However, due to the complex spatial and temporal correlations underlying in renewable generations, traditional model-based approaches for forecasting future scenarios often require extensive knowledge, while fitted models are often hard to scale. To address such modeling burdens, we propose a learning-based, data-driven scenario forecasts method based on generative adversarial networks (GANs), which is a class of deep-learning generative algorithms used for modeling unknown distributions. We firstly utilize an improved GANs with convergence guarantees to learn the intrinsic patterns and model the unknown distributions of (multiple-site) renewable generation time-series. Then by solving an optimization problem, we are able to generate forecasted scenarios without any scenario number and forecasting horizon restrictions. Our method is totally model-free, and could forecast scenarios under different level of forecast uncertainties. Extensive numerical simulations using real-world data from NREL wind and solar integration datasets validate the performance of proposed method in forecasting both wind and solar power scenarios.