 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFA-GAN: Artifacts-free and Phase-aware High-fidelity GAN-based Vocoder
Jul 05, 2024Generative adversarial network (GAN) based vocoders have achieved significant attention in speech synthesis with high quality and fast inference speed. However, there still exist many noticeable spectral artifacts, resulting in the quality decline of synthesized speech. In this work, we adopt a novel GAN-based vocoder designed for few artifacts and high fidelity, called FA-GAN. To suppress the aliasing artifacts caused by non-ideal upsampling layers in high-frequency components, we introduce the anti-aliased twin deconvolution module in the generator. To alleviate blurring artifacts and enrich the reconstruction of spectral details, we propose a novel fine-grained multi-resolution real and imaginary loss to assist in the modeling of phase information. Experimental results reveal that FA-GAN outperforms the compared approaches in promoting audio quality and alleviating spectral artifacts, and exhibits superior performance when applied to unseen speaker scenarios.
Who is Speaking Actually? Robust and Versatile Speaker Traceability for Voice Conversion
May 09, 2023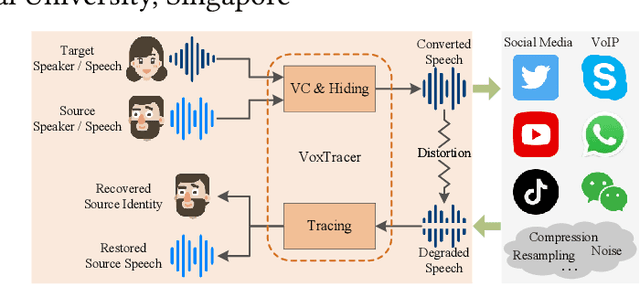
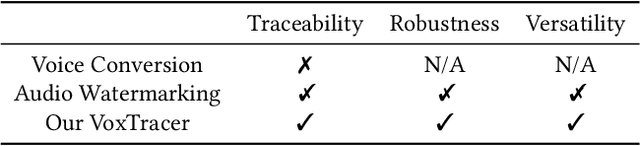
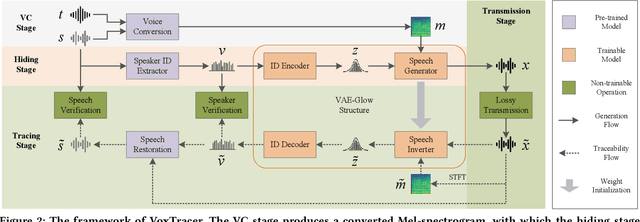
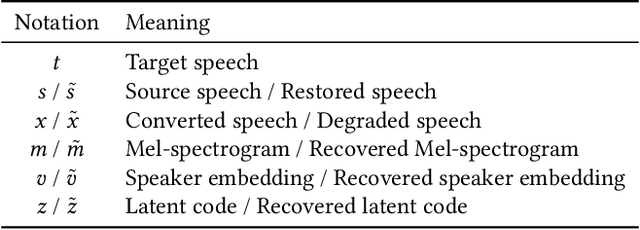
Voice conversion (VC), as a voice style transfer technology, is becoming increasingly prevalent while raising serious concerns about its illegal use. Proactively tracing the origins of VC-generated speeches, i.e., speaker traceability, can prevent the misuse of VC, but unfortunately has not been extensively studied. In this paper, we are the first to investigate the speaker traceability for VC and propose a traceable VC framework named VoxTracer. Our VoxTracer is similar to but beyond the paradigm of audio watermarking. We first use unique speaker embedding to represent speaker identity. Then we design a VAE-Glow structure, in which the hiding process imperceptibly integrates the source speaker identity into the VC, and the tracing process accurately recovers the source speaker identity and even the source speech in spite of severe speech quality degradation. To address the speech mismatch between the hiding and tracing processes affected by different distortions, we also adopt an asynchronous training strategy to optimize the VAE-Glow models. The VoxTracer is versatile enough to be applied to arbitrary VC methods and popular audio coding standards. Extensive experiments demonstrate that the VoxTracer achieves not only high imperceptibility in hiding, but also nearly 100% tracing accuracy against various types of audio lossy compressions (AAC, MP3, Opus and SILK) with a broad range of bitrates (16 kbps - 128 kbps) even in a very short time duration (0.74s). Our speech demo is available at https://anonymous.4open.science/w/DEMOofVoxTracer.