 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Algorithmic Framework for Systematic Literature Reviews: A Case Study for Financial Narratives
Jan 07, 2026This paper introduces an algorithmic framework for conducting systematic literature reviews (SLRs), designed to improve efficiency, reproducibility, and selection quality assessment in the literature review process. The proposed method integrates Natural Language Processing (NLP) techniques, clustering algorithms, and interpretability tools to automate and structure the selection and analysis of academic publications. The framework is applied to a case study focused on financial narratives, an emerging area in financial economics that examines how structured accounts of economic events, formed by the convergence of individual interpretations, influence market dynamics and asset prices. Drawing from the Scopus database of peer-reviewed literature, the review highlights research efforts to model financial narratives using various NLP techniques. Results reveal that while advances have been made, the conceptualization of financial narratives remains fragmented, often reduced to sentiment analysis, topic modeling, or their combination, without a unified theoretical framework. The findings underscore the value of more rigorous and dynamic narrative modeling approaches and demonstrate the effectiveness of the proposed algorithmic SLR methodology.
A Hypothesis on Good Practices for AI-based Systems for Financial Time Series Forecasting: Towards Domain-Driven XAI Methods
Nov 13, 2023Machine learning and deep learning have become increasingly prevalent in financial prediction and forecasting tasks, offering advantages such as enhanced customer experience, democratising financial services, improving consumer protection, and enhancing risk management. However, these complex models often lack transparency and interpretability, making them challenging to use in sensitive domains like finance. This has led to the rise of eXplainable Artificial Intelligence (XAI) methods aimed at creating models that are easily understood by humans. Classical XAI methods, such as LIME and SHAP, have been developed to provide explanations for complex models. While these methods have made significant contributions, they also have limitations, including computational complexity, inherent model bias, sensitivity to data sampling, and challenges in dealing with feature dependence. In this context, this paper explores good practices for deploying explainability in AI-based systems for finance, emphasising the importance of data quality, audience-specific methods, consideration of data properties, and the stability of explanations. These practices aim to address the unique challenges and requirements of the financial industry and guide the development of effective XAI tools.
Feature Selection via the Intervened Interpolative Decomposition and its Application in Diversifying Quantitative Strategies
Sep 29, 2022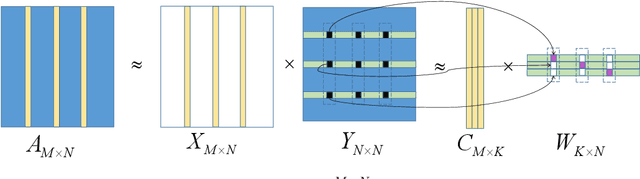
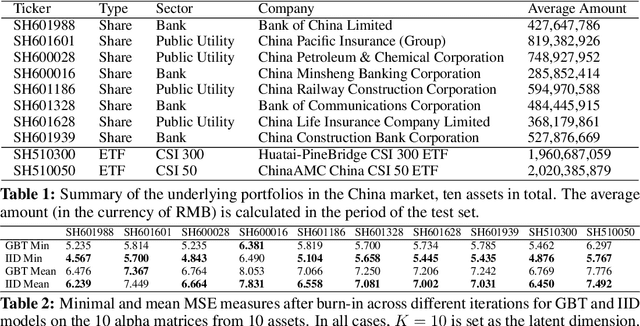
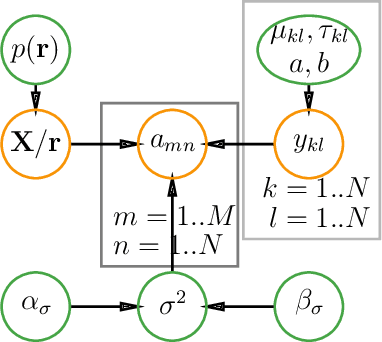
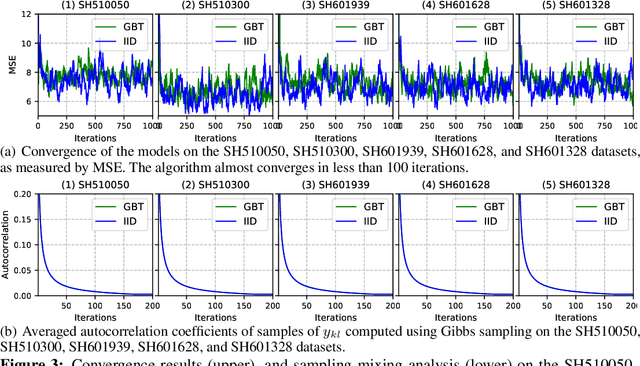
In this paper, we propose a probabilistic model for computing an interpolative decomposition (ID) in which each column of the observed matrix has its own priority or importance, so that the end result of the decomposition finds a set of features that are representative of the entire set of features, and the selected features also have higher priority than others. This approach is commonly used for low-rank approximation, feature selection, and extracting hidden patterns in data, where the matrix factors are latent variables associated with each data dimension. Gibbs sampling for Bayesian inference is applied to carry out the optimization. We evaluate the proposed models on real-world datasets, including ten Chinese A-share stocks, and demonstrate that the proposed Bayesian ID algorithm with intervention (IID) produces comparable reconstructive errors to existing Bayesian ID algorithms while selecting features with higher scores or priority.
Applications of Reinforcement Learning in Finance -- Trading with a Double Deep Q-Network
Jun 28, 2022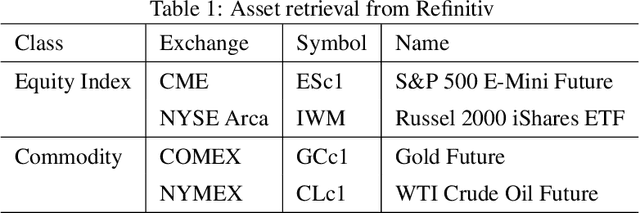
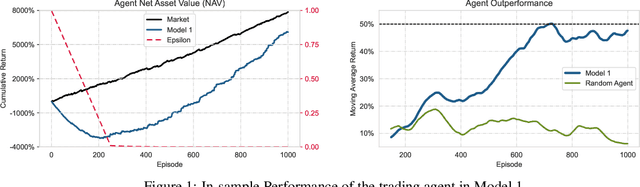
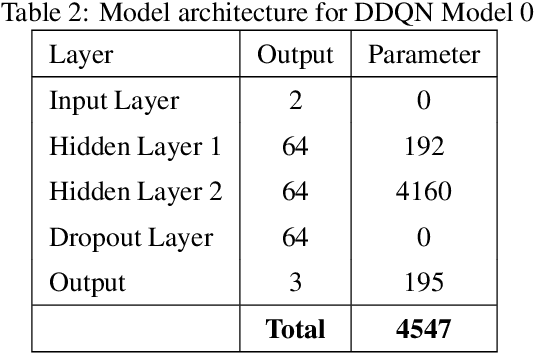
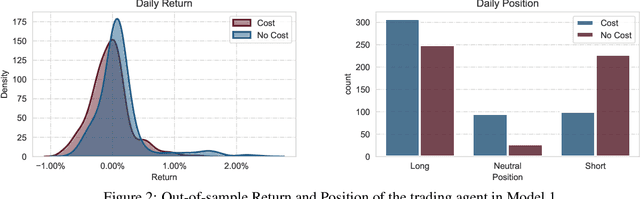
This paper presents a Double Deep Q-Network algorithm for trading single assets, namely the E-mini S&P 500 continuous futures contract. We use a proven setup as the foundation for our environment with multiple extensions. The features of our trading agent are constantly being expanded to include additional assets such as commodities, resulting in four models. We also respond to environmental conditions, including costs and crises. Our trading agent is first trained for a specific time period and tested on new data and compared with the long-and-hold strategy as a benchmark (market). We analyze the differences between the various models and the in-sample/out-of-sample performance with respect to the environment. The experimental results show that the trading agent follows an appropriate behavior. It can adjust its policy to different circumstances, such as more extensive use of the neutral position when trading costs are present. Furthermore, the net asset value exceeded that of the benchmark, and the agent outperformed the market in the test set. We provide initial insights into the behavior of an agent in a financial domain using a DDQN algorithm. The results of this study can be used for further development.
Explainable AI in Credit Risk Management
Mar 01, 2021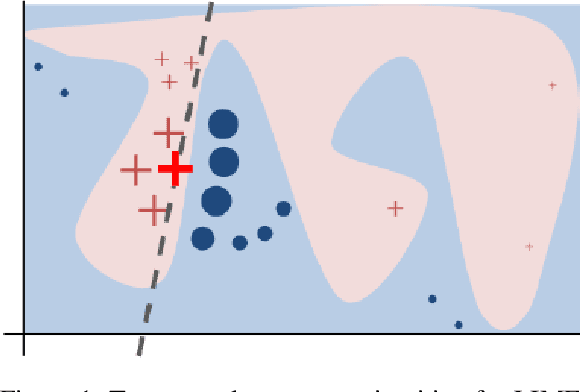


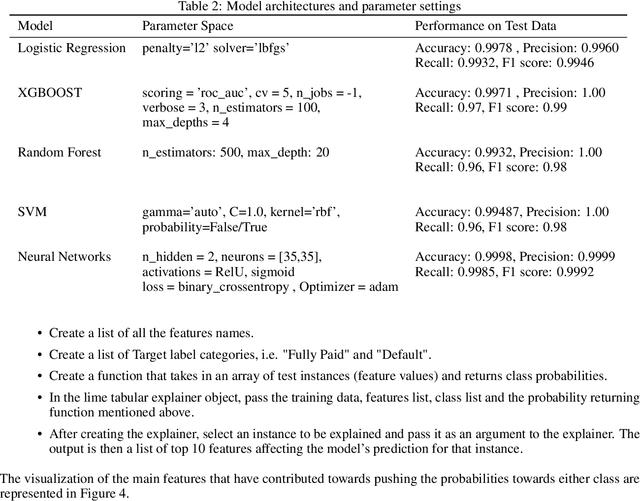
Artificial Intelligence (AI) has created the single biggest technology revolution the world has ever seen. For the finance sector, it provides great opportunities to enhance customer experience, democratize financial services, ensure consumer protection and significantly improve risk management. While it is easier than ever to run state-of-the-art machine learning models, designing and implementing systems that support real-world finance applications have been challenging. In large part because they lack transparency and explainability which are important factors in establishing reliable technology and the research on this topic with a specific focus on applications in credit risk management. In this paper, we implement two advanced post-hoc model agnostic explainability techniques called Local Interpretable Model Agnostic Explanations (LIME) and SHapley Additive exPlanations (SHAP) to machine learning (ML)-based credit scoring models applied to the open-access data set offered by the US-based P2P Lending Platform, Lending Club. Specifically, we use LIME to explain instances locally and SHAP to get both local and global explanations. We discuss the results in detail and present multiple comparison scenarios by using various kernels available for explaining graphs generated using SHAP values. We also discuss the practical challenges associated with the implementation of these state-of-art eXplainabale AI (XAI) methods and document them for future reference. We have made an effort to document every technical aspect of this research, while at the same time providing a general summary of the conclusions.