 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransClean: Finding False Positives in Multi-Source Entity Matching under Real-World Conditions via Transitive Consistency
Jun 04, 2025
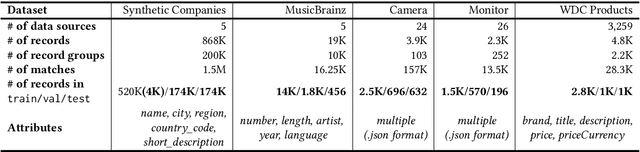
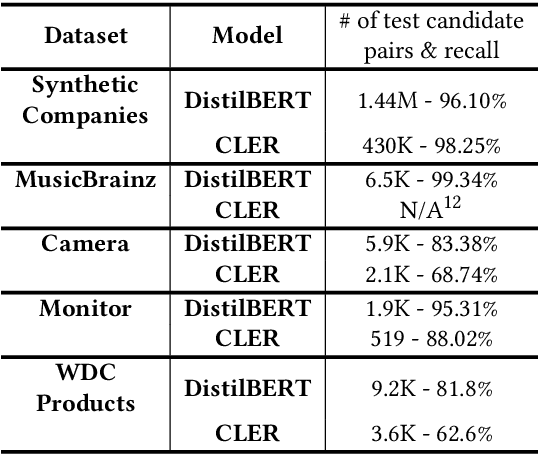
We present TransClean, a method for detecting false positive predictions of entity matching algorithms under real-world conditions characterized by large-scale, noisy, and unlabeled multi-source datasets that undergo distributional shifts. TransClean is explicitly designed to operate with multiple data sources in an efficient, robust and fast manner while accounting for edge cases and requiring limited manual labeling. TransClean leverages the Transitive Consistency of a matching, a measure of the consistency of a pairwise matching model f_theta on the matching it produces G_f_theta, based both on its predictions on directly evaluated record pairs and its predictions on implied record pairs. TransClean iteratively modifies a matching through gradually removing false positive matches while removing as few true positive matches as possible. In each of these steps, the estimation of the Transitive Consistency is exclusively done through model evaluations and produces quantities that can be used as proxies of the amounts of true and false positives in the matching while not requiring any manual labeling, producing an estimate of the quality of the matching and indicating which record groups are likely to contain false positives. In our experiments, we compare combining TransClean with a naively trained pairwise matching model (DistilBERT) and with a state-of-the-art end-to-end matching method (CLER) and illustrate the flexibility of TransClean in being able to detect most of the false positives of either setup across a variety of datasets. Our experiments show that TransClean induces an average +24.42 F1 score improvement for entity matching in a multi-source setting when compared to traditional pair-wise matching algorithms.
GraLMatch: Matching Groups of Entities with Graphs and Language Models
Jun 21, 2024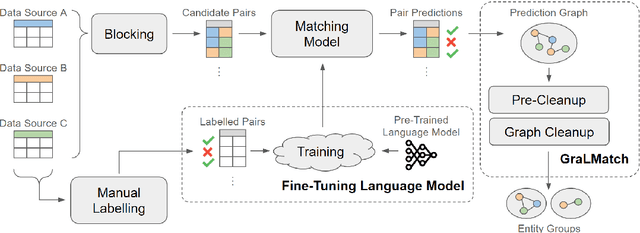
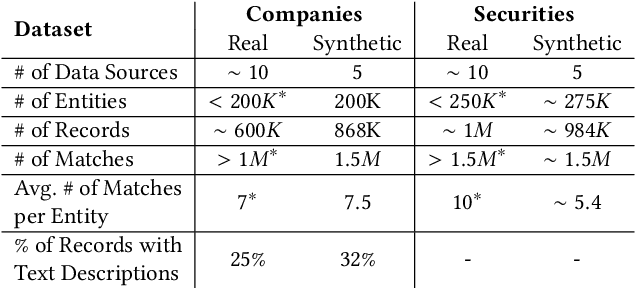
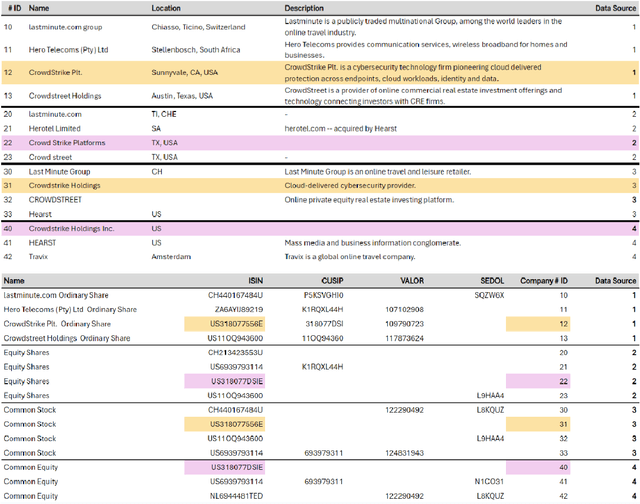
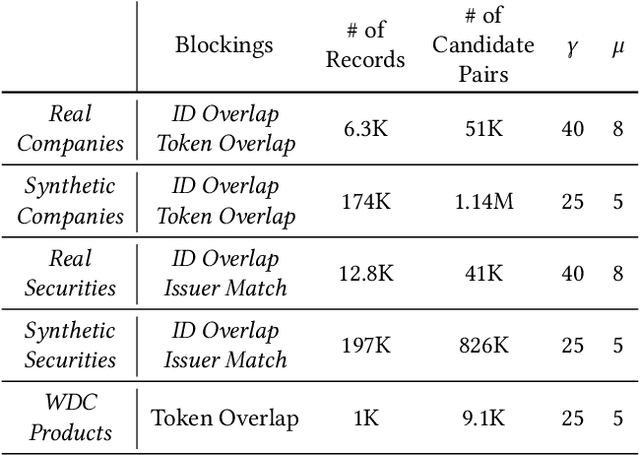
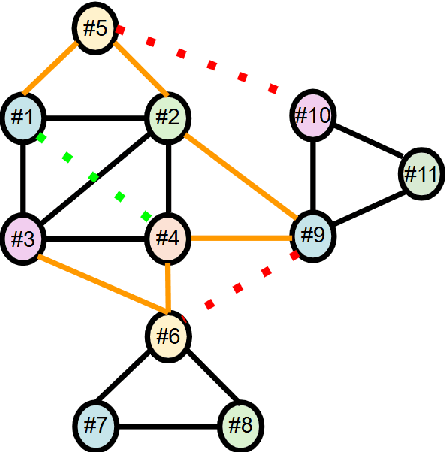
In this paper, we present an end-to-end multi-source Entity Matching problem, which we call entity group matching, where the goal is to assign to the same group, records originating from multiple data sources but representing the same real-world entity. We focus on the effects of transitively matched records, i.e. the records connected by paths in the graph G = (V,E) whose nodes and edges represent the records and whether they are a match or not. We present a real-world instance of this problem, where the challenge is to match records of companies and financial securities originating from different data providers. We also introduce two new multi-source benchmark datasets that present similar matching challenges as real-world records. A distinctive characteristic of these records is that they are regularly updated following real-world events, but updates are not applied uniformly across data sources. This phenomenon makes the matching of certain groups of records only possible through the use of transitive information. In our experiments, we illustrate how considering transitively matched records is challenging since a limited amount of false positive pairwise match predictions can throw off the group assignment of large quantities of records. Thus, we propose GraLMatch, a method that can partially detect and remove false positive pairwise predictions through graph-based properties. Finally, we showcase how fine-tuning a Transformer-based model (DistilBERT) on a reduced number of labeled samples yields a better final entity group matching than training on more samples and/or incorporating fine-tuning optimizations, illustrating how precision becomes the deciding factor in the entity group matching of large volumes of records.
A Hypothesis on Good Practices for AI-based Systems for Financial Time Series Forecasting: Towards Domain-Driven XAI Methods
Nov 13, 2023Machine learning and deep learning have become increasingly prevalent in financial prediction and forecasting tasks, offering advantages such as enhanced customer experience, democratising financial services, improving consumer protection, and enhancing risk management. However, these complex models often lack transparency and interpretability, making them challenging to use in sensitive domains like finance. This has led to the rise of eXplainable Artificial Intelligence (XAI) methods aimed at creating models that are easily understood by humans. Classical XAI methods, such as LIME and SHAP, have been developed to provide explanations for complex models. While these methods have made significant contributions, they also have limitations, including computational complexity, inherent model bias, sensitivity to data sampling, and challenges in dealing with feature dependence. In this context, this paper explores good practices for deploying explainability in AI-based systems for finance, emphasising the importance of data quality, audience-specific methods, consideration of data properties, and the stability of explanations. These practices aim to address the unique challenges and requirements of the financial industry and guide the development of effective XAI tools.
A Time Series Approach to Explainability for Neural Nets with Applications to Risk-Management and Fraud Detection
Dec 06, 2022Artificial intelligence is creating one of the biggest revolution across technology driven application fields. For the finance sector, it offers many opportunities for significant market innovation and yet broad adoption of AI systems heavily relies on our trust in their outputs. Trust in technology is enabled by understanding the rationale behind the predictions made. To this end, the concept of eXplainable AI emerged introducing a suite of techniques attempting to explain to users how complex models arrived at a certain decision. For cross-sectional data classical XAI approaches can lead to valuable insights about the models' inner workings, but these techniques generally cannot cope well with longitudinal data (time series) in the presence of dependence structure and non-stationarity. We here propose a novel XAI technique for deep learning methods which preserves and exploits the natural time ordering of the data.
Explainable AI in Credit Risk Management
Mar 01, 2021


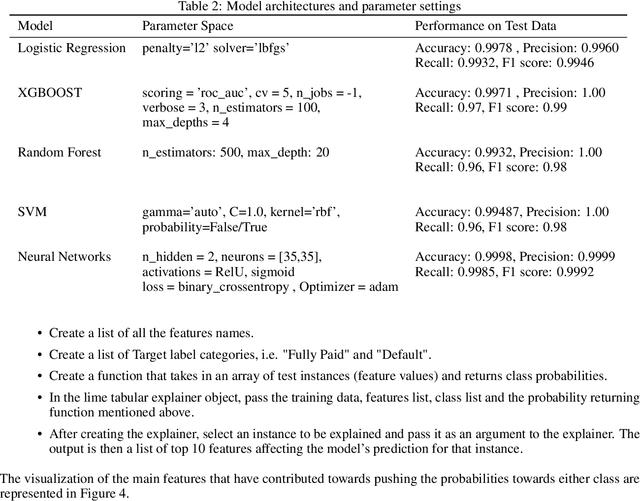
Artificial Intelligence (AI) has created the single biggest technology revolution the world has ever seen. For the finance sector, it provides great opportunities to enhance customer experience, democratize financial services, ensure consumer protection and significantly improve risk management. While it is easier than ever to run state-of-the-art machine learning models, designing and implementing systems that support real-world finance applications have been challenging. In large part because they lack transparency and explainability which are important factors in establishing reliable technology and the research on this topic with a specific focus on applications in credit risk management. In this paper, we implement two advanced post-hoc model agnostic explainability techniques called Local Interpretable Model Agnostic Explanations (LIME) and SHapley Additive exPlanations (SHAP) to machine learning (ML)-based credit scoring models applied to the open-access data set offered by the US-based P2P Lending Platform, Lending Club. Specifically, we use LIME to explain instances locally and SHAP to get both local and global explanations. We discuss the results in detail and present multiple comparison scenarios by using various kernels available for explaining graphs generated using SHAP values. We also discuss the practical challenges associated with the implementation of these state-of-art eXplainabale AI (XAI) methods and document them for future reference. We have made an effort to document every technical aspect of this research, while at the same time providing a general summary of the conclusions.