 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenJoin: Conditional Generative Plan-to-Plan Query Optimizer that Learns from Subplan Hints
Nov 07, 2024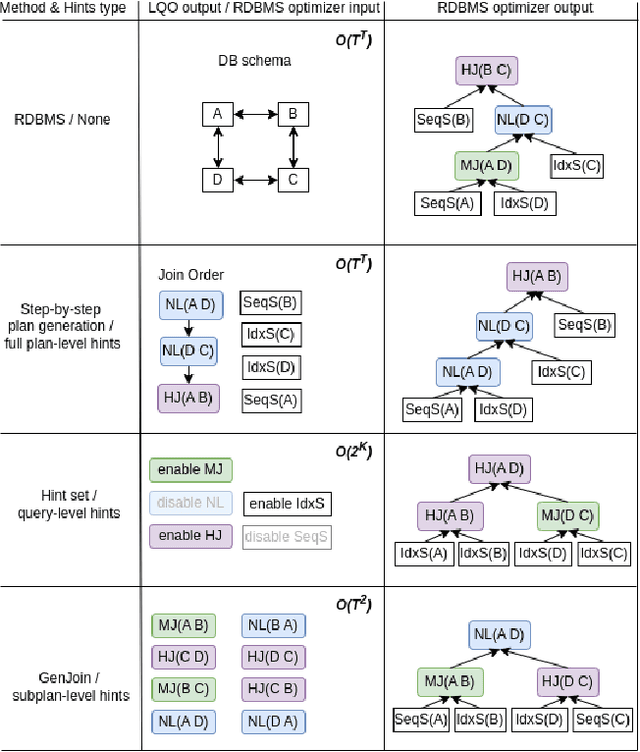
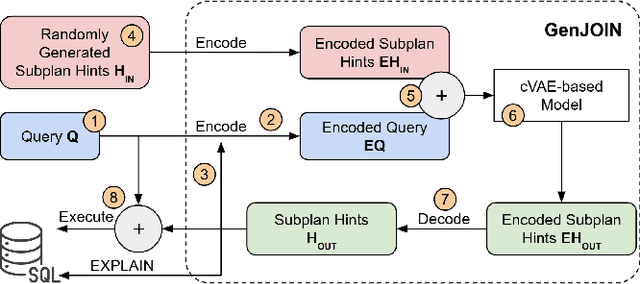
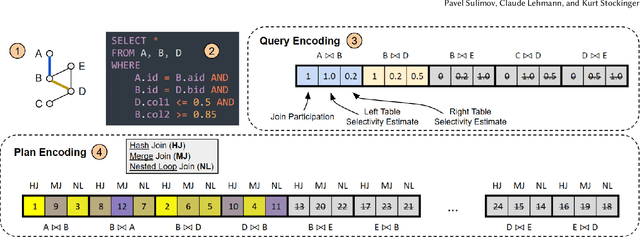
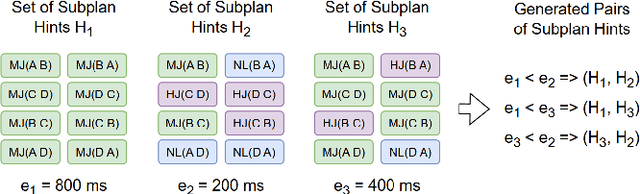
Query optimization has become a research area where classical algorithms are being challenged by machine learning algorithms. At the same time, recent trends in learned query optimizers have shown that it is prudent to take advantage of decades of database research and augment classical query optimizers by shrinking the plan search space through different types of hints (e.g. by specifying the join type, scan type or the order of joins) rather than completely replacing the classical query optimizer with machine learning models. It is especially relevant for cases when classical optimizers cannot fully enumerate all logical and physical plans and, as an alternative, need to rely on less robust approaches like genetic algorithms. However, even symbiotically learned query optimizers are hampered by the need for vast amounts of training data, slow plan generation during inference and unstable results across various workload conditions. In this paper, we present GenJoin - a novel learned query optimizer that considers the query optimization problem as a generative task and is capable of learning from a random set of subplan hints to produce query plans that outperform the classical optimizer. GenJoin is the first learned query optimizer that significantly and consistently outperforms PostgreSQL as well as state-of-the-art methods on two well-known real-world benchmarks across a variety of workloads using rigorous machine learning evaluations.
GraLMatch: Matching Groups of Entities with Graphs and Language Models
Jun 21, 2024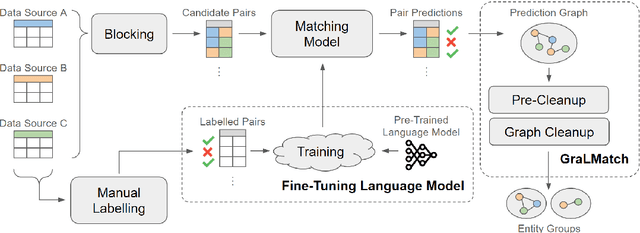
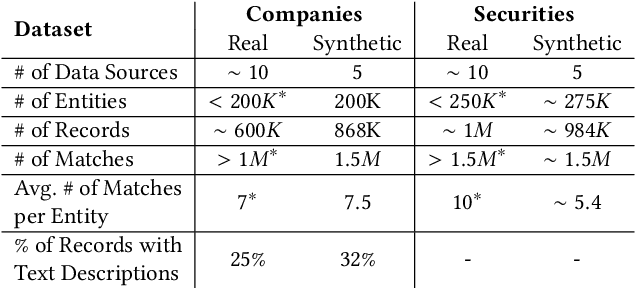
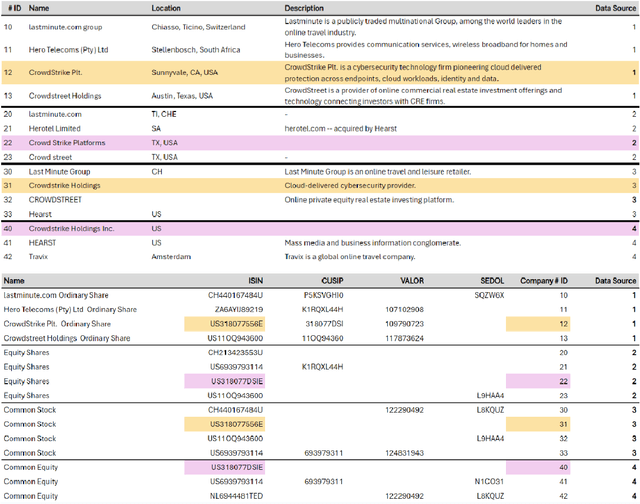
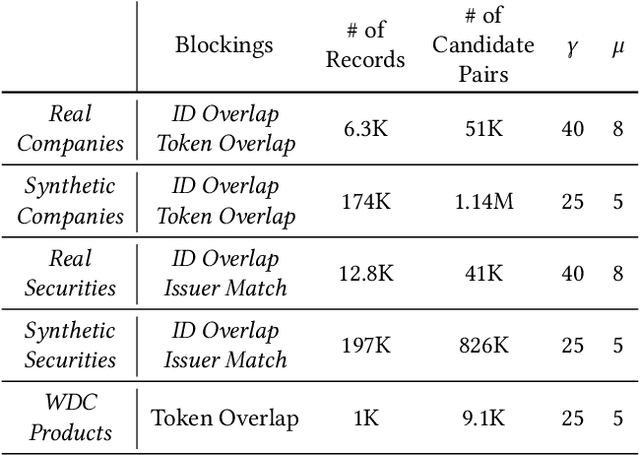
In this paper, we present an end-to-end multi-source Entity Matching problem, which we call entity group matching, where the goal is to assign to the same group, records originating from multiple data sources but representing the same real-world entity. We focus on the effects of transitively matched records, i.e. the records connected by paths in the graph G = (V,E) whose nodes and edges represent the records and whether they are a match or not. We present a real-world instance of this problem, where the challenge is to match records of companies and financial securities originating from different data providers. We also introduce two new multi-source benchmark datasets that present similar matching challenges as real-world records. A distinctive characteristic of these records is that they are regularly updated following real-world events, but updates are not applied uniformly across data sources. This phenomenon makes the matching of certain groups of records only possible through the use of transitive information. In our experiments, we illustrate how considering transitively matched records is challenging since a limited amount of false positive pairwise match predictions can throw off the group assignment of large quantities of records. Thus, we propose GraLMatch, a method that can partially detect and remove false positive pairwise predictions through graph-based properties. Finally, we showcase how fine-tuning a Transformer-based model (DistilBERT) on a reduced number of labeled samples yields a better final entity group matching than training on more samples and/or incorporating fine-tuning optimizations, illustrating how precision becomes the deciding factor in the entity group matching of large volumes of records.