 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed Reality Communication for Medical Procedures: Teaching the Placement of a Central Venous Catheter
Dec 14, 2023Medical procedures are an essential part of healthcare delivery, and the acquisition of procedural skills is a critical component of medical education. Unfortunately, procedural skill is not evenly distributed among medical providers. Skills may vary within departments or institutions, and across geographic regions, depending on the provider's training and ongoing experience. We present a mixed reality real-time communication system to increase access to procedural skill training and to improve remote emergency assistance. Our system allows a remote expert to guide a local operator through a medical procedure. RGBD cameras capture a volumetric view of the local scene including the patient, the operator, and the medical equipment. The volumetric capture is augmented onto the remote expert's view to allow the expert to spatially guide the local operator using visual and verbal instructions. We evaluated our mixed reality communication system in a study in which experts teach the ultrasound-guided placement of a central venous catheter (CVC) to students in a simulation setting. The study compares state-of-the-art video communication against our system. The results indicate that our system enhances and offers new possibilities for visual communication compared to video teleconference-based training.
Real-time Gesture Animation Generation from Speech for Virtual Human Interaction
Aug 05, 2022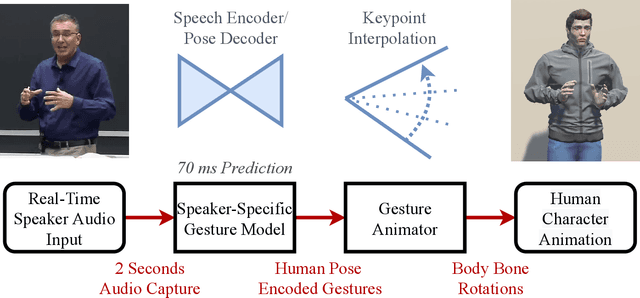
We propose a real-time system for synthesizing gestures directly from speech. Our data-driven approach is based on Generative Adversarial Neural Networks to model the speech-gesture relationship. We utilize the large amount of speaker video data available online to train our 3D gesture model. Our model generates speaker-specific gestures by taking consecutive audio input chunks of two seconds in length. We animate the predicted gestures on a virtual avatar. We achieve a delay below three seconds between the time of audio input and gesture animation. Code and videos are available at https://github.com/mrebol/Gestures-From-Speech
* CHI EA '21: Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems. arXiv admin note: text overlap with arXiv:2107.00712
Passing a Non-verbal Turing Test: Evaluating Gesture Animations Generated from Speech
Jul 01, 2021



In real life, people communicate using both speech and non-verbal signals such as gestures, face expression or body pose. Non-verbal signals impact the meaning of the spoken utterance in an abundance of ways. An absence of non-verbal signals impoverishes the process of communication. Yet, when users are represented as avatars, it is difficult to translate non-verbal signals along with the speech into the virtual world without specialized motion-capture hardware. In this paper, we propose a novel, data-driven technique for generating gestures directly from speech. Our approach is based on the application of Generative Adversarial Neural Networks (GANs) to model the correlation rather than causation between speech and gestures. This approach approximates neuroscience findings on how non-verbal communication and speech are correlated. We create a large dataset which consists of speech and corresponding gestures in a 3D human pose format from which our model learns the speaker-specific correlation. We evaluate the proposed technique in a user study that is inspired by the Turing test. For the study, we animate the generated gestures on a virtual character. We find that users are not able to distinguish between the generated and the recorded gestures. Moreover, users are able to identify our synthesized gestures as related or not related to a given utterance.