Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Gesture Animation Generation from Speech for Virtual Human Interaction
Paper and Code
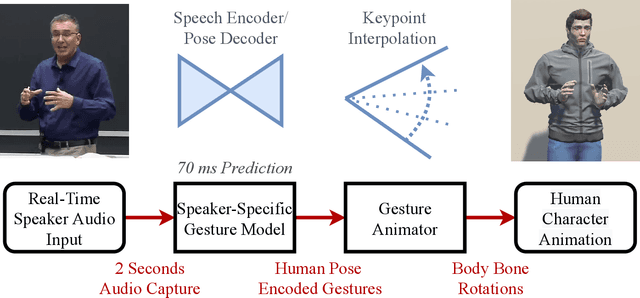
We propose a real-time system for synthesizing gestures directly from speech. Our data-driven approach is based on Generative Adversarial Neural Networks to model the speech-gesture relationship. We utilize the large amount of speaker video data available online to train our 3D gesture model. Our model generates speaker-specific gestures by taking consecutive audio input chunks of two seconds in length. We animate the predicted gestures on a virtual avatar. We achieve a delay below three seconds between the time of audio input and gesture animation. Code and videos are available at https://github.com/mrebol/Gestures-From-Speech
* In CHI EA 2021. ACM, New York, NY, USA, Article 197, 1-4 * CHI EA '21: Extended Abstracts of the 2021 CHI Conference on Human
Factors in Computing Systems. arXiv admin note: text overlap with
arXiv:2107.00712
View paper on