 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVEXIR2Vec: An Architecture-Neutral Embedding Framework for Binary Similarity
Dec 01, 2023We propose VEXIR2Vec, a code embedding framework for finding similar functions in binaries. Our representations rely on VEX IR, the intermediate representation used by binary analysis tools like Valgrind and angr. Our proposed embeddings encode both syntactic and semantic information to represent a function, and is both application and architecture independent. We also propose POV, a custom Peephole Optimization engine that normalizes the VEX IR for effective similarity analysis. We design several optimizations like copy/constant propagation, constant folding, common subexpression elimination and load-store elimination in POV. We evaluate our framework on two experiments -- diffing and searching -- involving binaries targeting different architectures, compiled using different compilers and versions, optimization sequences, and obfuscations. We show results on several standard projects and on real-world vulnerabilities. Our results show that VEXIR2Vec achieves superior precision and recall values compared to the state-of-the-art works. Our framework is highly scalable and is built as a multi-threaded, parallel library by only using open-source tools. VEXIR2Vec achieves about $3.2 \times$ speedup on the closest competitor, and orders-of-magnitude speedup on other tools.
The Next 700 ML-Enabled Compiler Optimizations
Nov 17, 2023There is a growing interest in enhancing compiler optimizations with ML models, yet interactions between compilers and ML frameworks remain challenging. Some optimizations require tightly coupled models and compiler internals,raising issues with modularity, performance and framework independence. Practical deployment and transparency for the end-user are also important concerns. We propose ML-Compiler-Bridge to enable ML model development within a traditional Python framework while making end-to-end integration with an optimizing compiler possible and efficient. We evaluate it on both research and production use cases, for training and inference, over several optimization problems, multiple compilers and its versions, and gym infrastructures.
POSET-RL: Phase ordering for Optimizing Size and Execution Time using Reinforcement Learning
Jul 27, 2022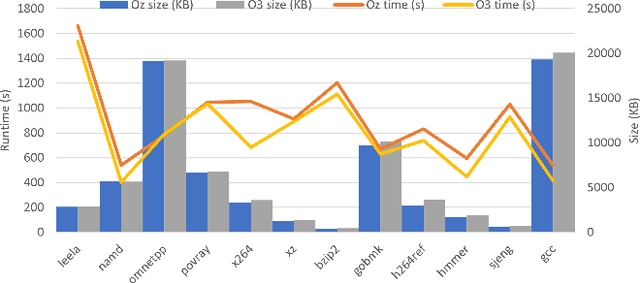
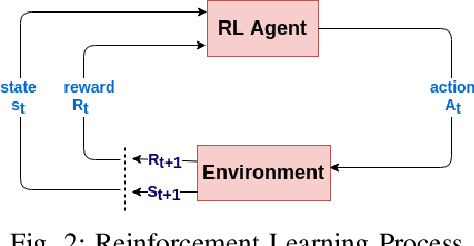
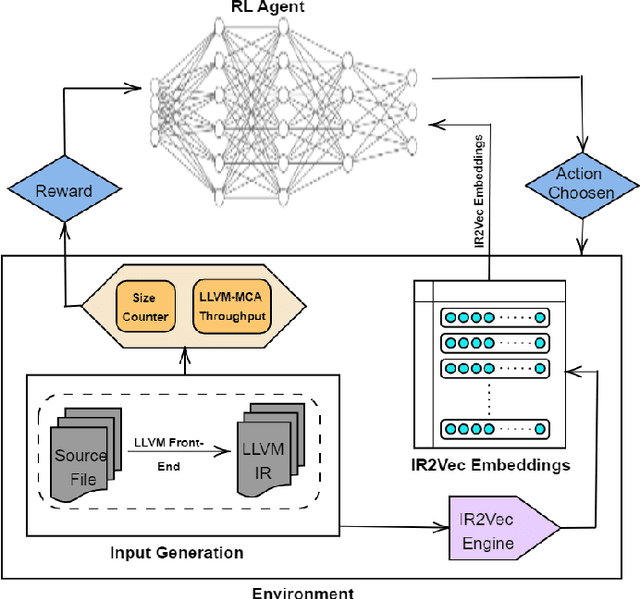
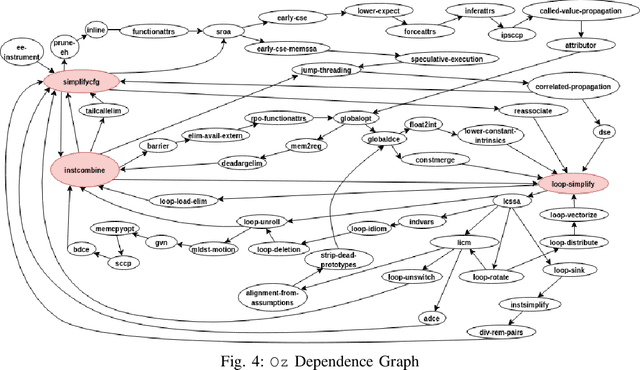
The ever increasing memory requirements of several applications has led to increased demands which might not be met by embedded devices. Constraining the usage of memory in such cases is of paramount importance. It is important that such code size improvements should not have a negative impact on the runtime. Improving the execution time while optimizing for code size is a non-trivial but a significant task. The ordering of standard optimization sequences in modern compilers is fixed, and are heuristically created by the compiler domain experts based on their expertise. However, this ordering is sub-optimal, and does not generalize well across all the cases. We present a reinforcement learning based solution to the phase ordering problem, where the ordering improves both the execution time and code size. We propose two different approaches to model the sequences: one by manual ordering, and other based on a graph called Oz Dependence Graph (ODG). Our approach uses minimal data as training set, and is integrated with LLVM. We show results on x86 and AArch64 architectures on the benchmarks from SPEC-CPU 2006, SPEC-CPU 2017 and MiBench. We observe that the proposed model based on ODG outperforms the current Oz sequence both in terms of size and execution time by 6.19% and 11.99% in SPEC 2017 benchmarks, on an average.
RL4ReAl: Reinforcement Learning for Register Allocation
Apr 05, 2022

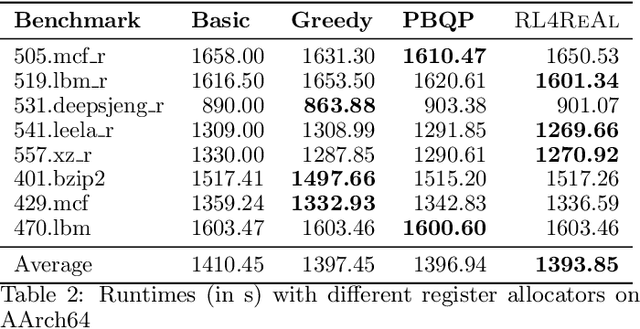
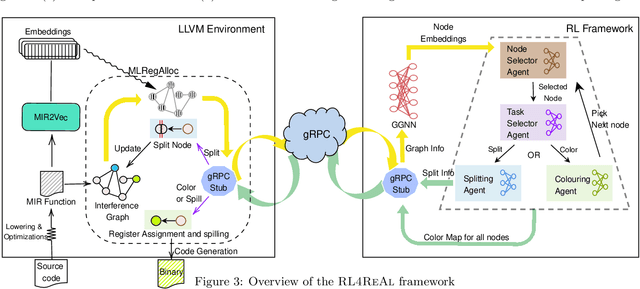
We propose a novel solution for the Register Allocation problem, leveraging multi-agent hierarchical Reinforcement Learning. We formalize the constraints that precisely define the problem for a given instruction-set architecture, while ensuring that the generated code preserves semantic correctness. We also develop a gRPC based framework providing a modular and efficient compiler interface for training and inference. Experimental results match or outperform the LLVM register allocators, targeting Intel x86 and ARM AArch64.