 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHexagon-MLIR: An AI Compilation Stack For Qualcomm's Neural Processing Units (NPUs)
Feb 23, 2026In this paper, we present Hexagon-MLIR,an open-source compilation stack that targets Qualcomm Hexagon Neural Processing Unit (NPU) and provides unified support for lowering Triton kernels and PyTorch models . Built using the MLIR framework, our compiler applies a structured sequence of passes to exploit NPU architectural features to accelerate AI workloads. It enables faster deployment of new Triton kernels (hand-written or subgraphs from PyTorch 2.0), for our target by providing automated compilation from kernel to binary. By ingesting Triton kernels, we generate mega-kernels that maximize data locality in the NPU's Tightly Coupled Memory (TCM), reducing the bandwidth bottlenecks inherent in library-based approaches. This initiative complements our commercial toolchains by providing developers with an open-source MLIR-based compilation stack that gives them a path to advance AI compilation capabilities through a more flexible approach. Hexagon-MLIR is a work-in-progress, and we are continuing to add many more optimizations and capabilities in this effort.
POSET-RL: Phase ordering for Optimizing Size and Execution Time using Reinforcement Learning
Jul 27, 2022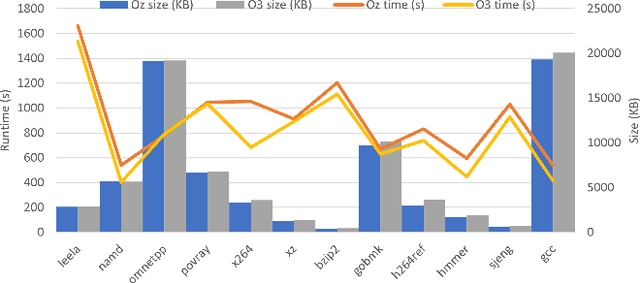
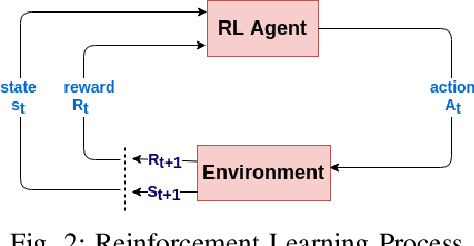
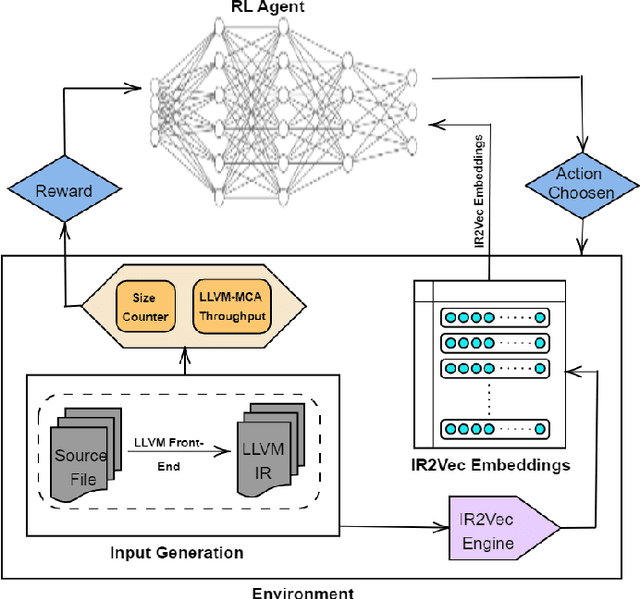
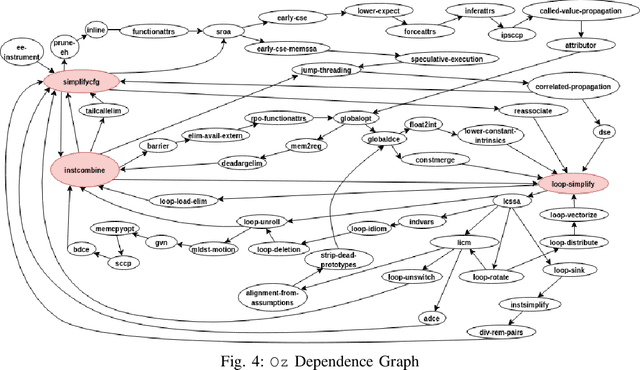
The ever increasing memory requirements of several applications has led to increased demands which might not be met by embedded devices. Constraining the usage of memory in such cases is of paramount importance. It is important that such code size improvements should not have a negative impact on the runtime. Improving the execution time while optimizing for code size is a non-trivial but a significant task. The ordering of standard optimization sequences in modern compilers is fixed, and are heuristically created by the compiler domain experts based on their expertise. However, this ordering is sub-optimal, and does not generalize well across all the cases. We present a reinforcement learning based solution to the phase ordering problem, where the ordering improves both the execution time and code size. We propose two different approaches to model the sequences: one by manual ordering, and other based on a graph called Oz Dependence Graph (ODG). Our approach uses minimal data as training set, and is integrated with LLVM. We show results on x86 and AArch64 architectures on the benchmarks from SPEC-CPU 2006, SPEC-CPU 2017 and MiBench. We observe that the proposed model based on ODG outperforms the current Oz sequence both in terms of size and execution time by 6.19% and 11.99% in SPEC 2017 benchmarks, on an average.
IR2Vec: A Flow Analysis based Scalable Infrastructure for Program Encodings
Sep 13, 2019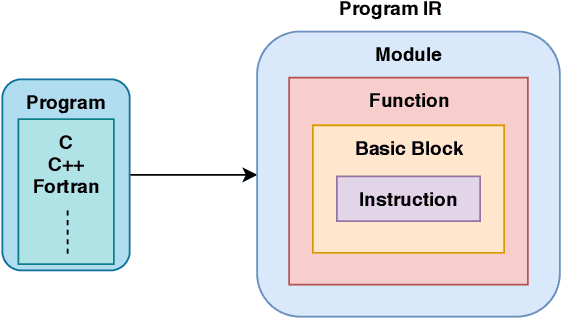
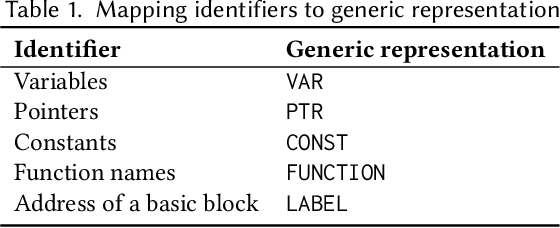
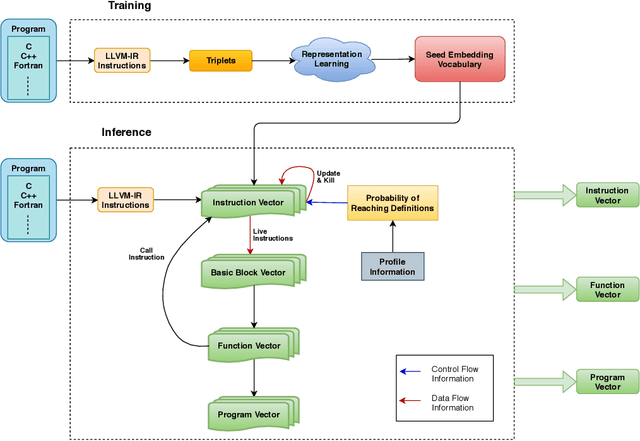

We propose IR2Vec, a Concise and Scalable encoding infrastructure to represent programs as a distributed embedding in continuous space. This distributed embedding is obtained by combining representation learning methods with data and control flow information to capture the syntax as well as the semantics of the input programs. Our embeddings are obtained from the Intermediate Representation (IR) of the source code, and are both language as well as machine independent. The entities of the IR are modelled as relationships, and their representations are learned to form a seed embedding vocabulary. This vocabulary is used along with the flow analyses information to form a hierarchy of encodings based on various levels of program abstractions. We show the effectiveness of our methodology on a software engineering task (program classification) as well as optimization tasks (Heterogeneous device mapping and Thread coarsening). The embeddings generated by IR2Vec outperform the existing methods in all the three tasks even when using simple machine learning models. As we follow an agglomerative method of forming encodings at various levels using seed embedding vocabulary, our encoding is naturally more scalable and not data-hungry when compared to the other methods.